6.3.5 Transfer Learning
Learning Objectives
Section titled “Learning Objectives”- Explain why training a CNN from scratch is often wasteful.
- Distinguish a pretrained backbone from a classification head.
- Freeze a backbone and train only the new head.
- Unfreeze the last convolution block with a smaller learning rate.
- Avoid common transfer-learning mistakes such as data leakage and destructive fine-tuning.
Look at the Decision Flow First
Section titled “Look at the Decision Flow First”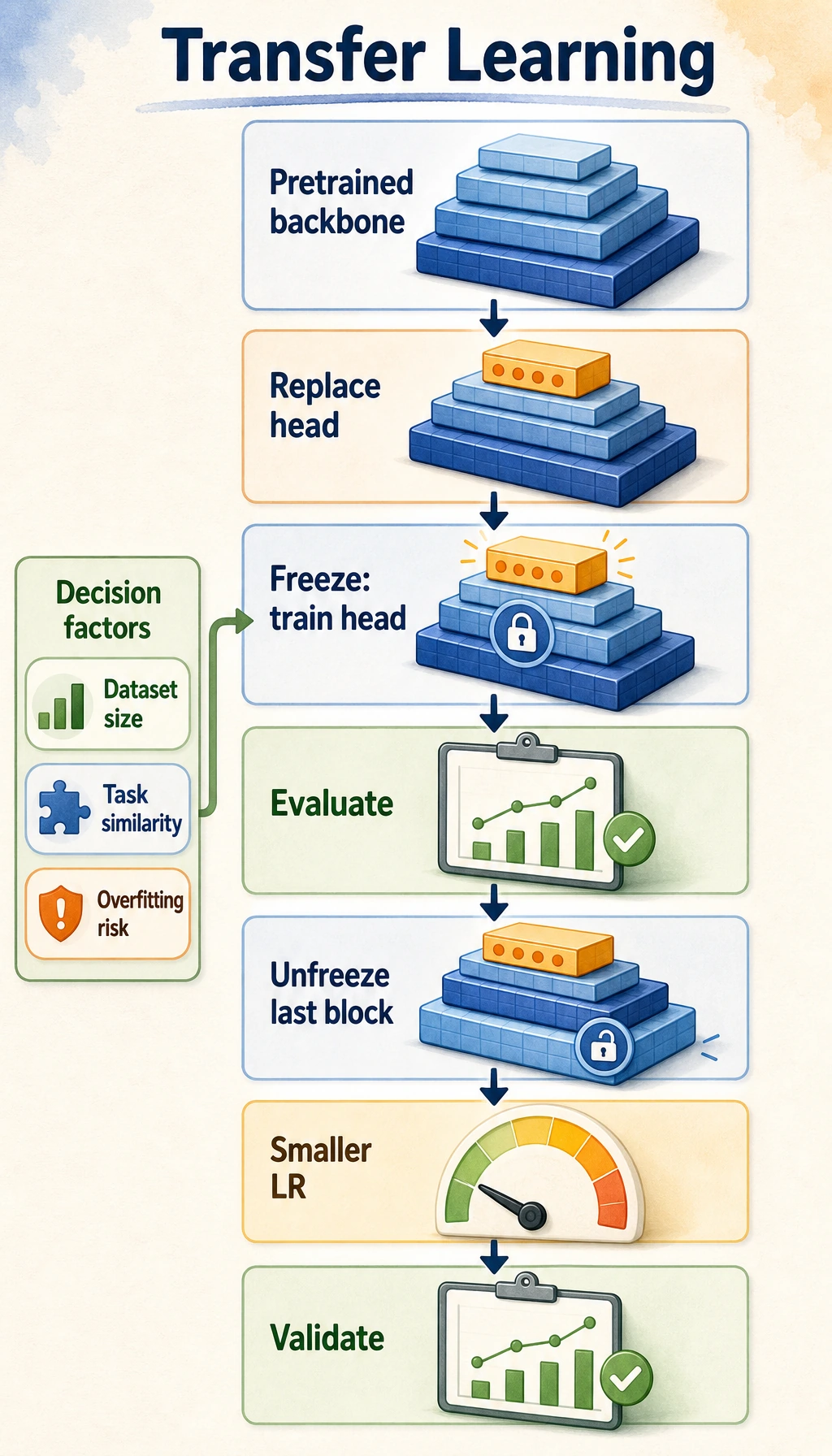
Read the flow like this:
Two questions drive the decision:
| Question | If the answer is small/similar | If the answer is large/different |
|---|---|---|
| How much labeled data do you have? | freeze most layers first | fine-tune more layers carefully |
| How similar is the new task? | pretrained features may transfer well | later layers may need adaptation |
This section uses pure PyTorch and synthetic images so the code runs without downloading torchvision weights. In real projects, the backbone is usually a pretrained torchvision or timm model.
Core Terms
Section titled “Core Terms”| Term | Meaning |
|---|---|
| backbone | feature extractor, usually all layers before the final classifier |
| head | task-specific classifier or regressor attached to the backbone |
| freeze | set requires_grad=False so parameters do not update |
| fine-tune | unfreeze some pretrained layers and continue training |
| logits | raw class scores before softmax |
The practical rule is:
small data -> train the head firstnot good enough -> unfreeze later backbone layers with a smaller learning rateFull Lab: Simulate Transfer Learning Offline
Section titled “Full Lab: Simulate Transfer Learning Offline”This lab has three stages:
- Pretrain a tiny backbone on simple line patterns.
- Reuse that backbone on a new target task and train only the head.
- Unfreeze the last convolution layer and fine-tune with a smaller learning rate.
Run the full script:
import copyimport numpy as npimport torchfrom torch import nn
SEED = 7np.random.seed(SEED)torch.manual_seed(SEED)
def make_image(label, task, size=16, noise=0.05): img = np.zeros((size, size), dtype=np.float32) c = size // 2
if task == "source": if label == 0: img[:, c] = 1.0 elif label == 1: img[c, :] = 1.0 else: for i in range(size): img[i, i] = 1.0 elif task == "target": if label == 0: img[:, c] = 1.0 img[c, :] = 1.0 elif label == 1: for i in range(size): img[i, size - 1 - i] = 1.0 else: img[3:-3, 3] = 1.0 img[3:-3, -4] = 1.0 img[3, 3:-3] = 1.0 img[-4, 3:-3] = 1.0
img += np.random.randn(size, size).astype(np.float32) * noise return np.clip(img, 0.0, 1.0)
def make_dataset(task, per_class, size=16): X, y = [], [] for label in range(3): for _ in range(per_class): X.append(make_image(label, task, size=size)) y.append(label) X = torch.tensor(np.array(X)).unsqueeze(1) y = torch.tensor(np.array(y), dtype=torch.long) return X, y
class TinyBackbone(nn.Module): def __init__(self): super().__init__() self.features = nn.Sequential( nn.Conv2d(1, 8, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(), nn.AdaptiveAvgPool2d((1, 1)), )
def forward(self, x): return self.features(x).flatten(1)
class ImageClassifier(nn.Module): def __init__(self, backbone=None, num_classes=3): super().__init__() self.backbone = backbone if backbone is not None else TinyBackbone() self.head = nn.Linear(16, num_classes)
def forward(self, x): return self.head(self.backbone(x))
def accuracy(model, X, y): with torch.no_grad(): return (model(X).argmax(dim=1) == y).float().mean().item()
def train(model, X, y, optimizer, epochs, label, print_every): loss_fn = nn.CrossEntropyLoss() for epoch in range(1, epochs + 1): logits = model(X) loss = loss_fn(logits, y)
optimizer.zero_grad() loss.backward() optimizer.step()
if epoch == 1 or epoch % print_every == 0: acc = accuracy(model, X, y) print(f"{label} epoch={epoch:02d} loss={loss.item():.4f} acc={acc:.3f}")
source_X, source_y = make_dataset("source", per_class=80)target_train_X, target_train_y = make_dataset("target", per_class=12)target_val_X, target_val_y = make_dataset("target", per_class=40)
# Stage 1: pretrain a source model.source_model = ImageClassifier(num_classes=3)train( source_model, source_X, source_y, torch.optim.Adam(source_model.parameters(), lr=0.03), epochs=60, label="pretrain", print_every=20,)
# Stage 2: transfer the backbone and train only a new head.frozen_backbone = copy.deepcopy(source_model.backbone)transfer_model = ImageClassifier(backbone=frozen_backbone, num_classes=3)for p in transfer_model.backbone.parameters(): p.requires_grad = False
print("trainable_after_freeze")for name, p in transfer_model.named_parameters(): print(f"{name:<28} {p.requires_grad}")
train( transfer_model, target_train_X, target_train_y, torch.optim.Adam(transfer_model.head.parameters(), lr=0.05), epochs=20, label="head", print_every=10,)print("head_only_val_acc", round(accuracy(transfer_model, target_val_X, target_val_y), 3))
# Stage 3: unfreeze the last conv layer and fine-tune gently.for p in transfer_model.backbone.features[3].parameters(): p.requires_grad = True
optimizer = torch.optim.Adam( [ {"params": transfer_model.backbone.features[3].parameters(), "lr": 0.0005}, {"params": transfer_model.head.parameters(), "lr": 0.005}, ])train( transfer_model, target_train_X, target_train_y, optimizer, epochs=20, label="finetune", print_every=10,)print("finetune_val_acc", round(accuracy(transfer_model, target_val_X, target_val_y), 3))Expected output:
pretrain epoch=01 loss=1.0995 acc=0.667pretrain epoch=20 loss=0.0000 acc=1.000pretrain epoch=40 loss=0.0000 acc=1.000pretrain epoch=60 loss=0.0000 acc=1.000trainable_after_freezebackbone.features.0.weight Falsebackbone.features.0.bias Falsebackbone.features.3.weight Falsebackbone.features.3.bias Falsehead.weight Truehead.bias Truehead epoch=01 loss=2.4749 acc=0.361head epoch=10 loss=0.7364 acc=0.667head epoch=20 loss=0.4991 acc=0.944head_only_val_acc 0.875finetune epoch=01 loss=0.4759 acc=0.667finetune epoch=10 loss=0.4367 acc=1.000finetune epoch=20 loss=0.4096 acc=1.000finetune_val_acc 1.0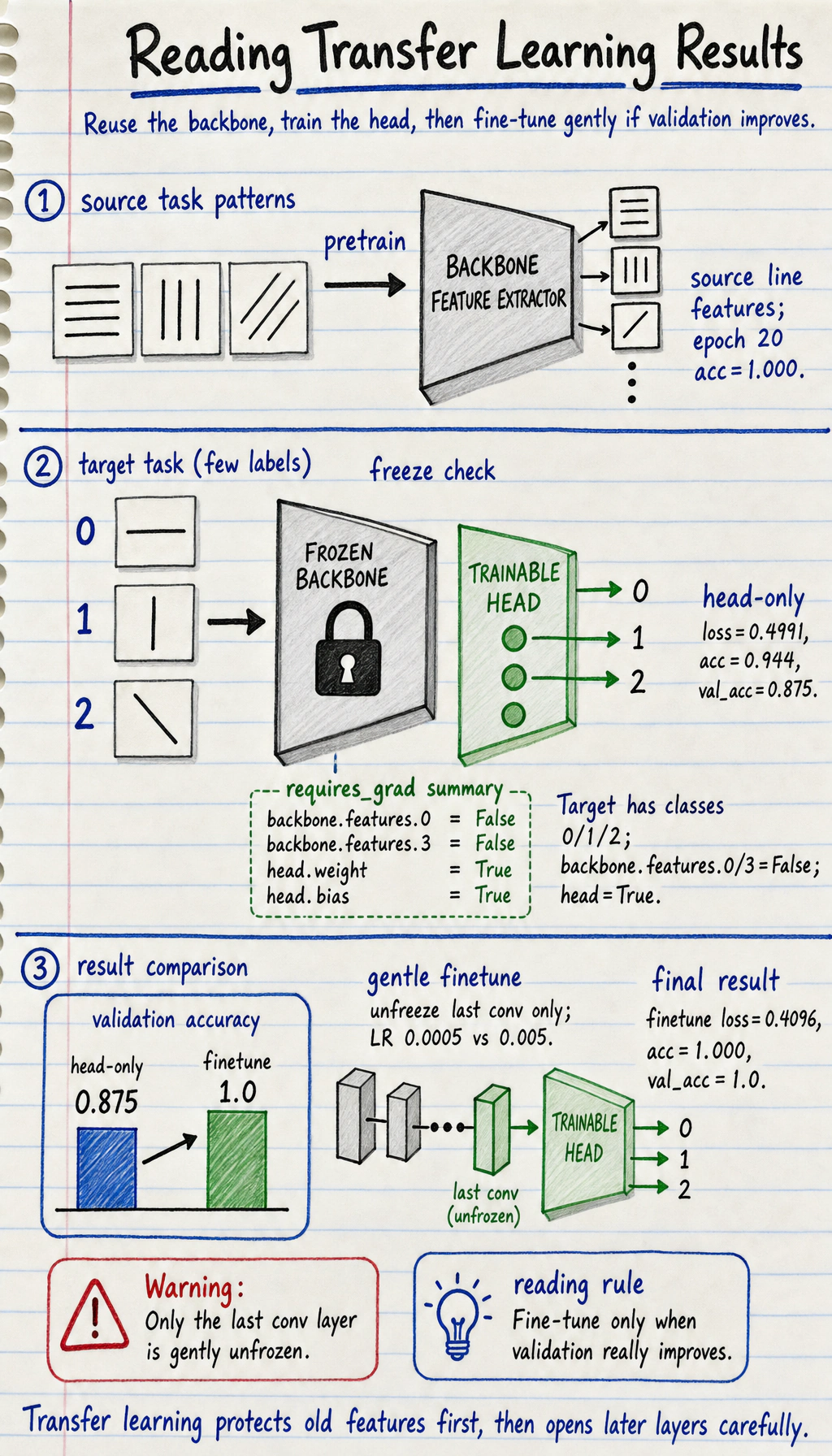
Read the result in three passes:
pretrainproves the tiny backbone can extract reusable line-pattern features.trainable_after_freezeis the safety check: the backbone stays frozen and only the new head updates.head_only_val_acc=0.875is already useful, andfinetune_val_acc=1.0shows that gently unfreezing the last convolution helped on this validation set.
What the Lab Teaches
Section titled “What the Lab Teaches”| Stage | What happened | Practical meaning |
|---|---|---|
| pretrain | backbone learned line-like visual features | this stands in for a real pretrained model |
| freeze | only the new head was trainable | fast and safer for small target data |
| train head | target validation accuracy became useful | reused features were already helpful |
| fine-tune | last conv layer adapted gently | small learning rate reduces damage to old features |
Fine-tuning is not automatically better. It can overfit or destroy pretrained features if the target data is tiny or the learning rate is too high. Always judge by validation results, not by the training loss alone.
Evidence to Keep
Section titled “Evidence to Keep”For a transfer-learning experiment, keep this decision record:
- Frozen Check
- which layers have requires_grad=False
- Head Result
- validation score after training only the new head
- Finetune Result
- validation score after unfreezing later layers
- Decision
- keep frozen or fine-tune based on validation, not training loss
- Risk Note
- data size, domain mismatch, preprocessing mismatch
This turns transfer learning from “use a big model” into a controlled engineering workflow.
Real Project Workflow
Section titled “Real Project Workflow”- Split data into train/validation/test before touching the model.
- Load a pretrained backbone.
- Replace the head so output classes match your task.
- Freeze the backbone and train the head.
- Inspect validation errors.
- If needed, unfreeze later blocks and use a smaller learning rate for the backbone.
- Stop when validation improves no further.
For real images, also match the preprocessing expected by the pretrained weights: input size, normalization mean/std, and color channel order.
Freeze or Fine-Tune?
Section titled “Freeze or Fine-Tune?”| Situation | Starting choice |
|---|---|
| very small dataset, similar task | freeze backbone, train head |
| medium dataset, similar task | freeze first, then unfreeze last block |
| larger dataset, different visual domain | fine-tune more blocks carefully |
| medical/satellite/industrial images | validate carefully; pretrained natural-image features may transfer only partly |
| deployment-limited device | prefer smaller backbone or freeze-and-head baseline first |
Common Mistakes
Section titled “Common Mistakes”| Mistake | Why it hurts | Fix |
|---|---|---|
| fine-tuning all layers immediately | unstable on small data | train head first |
| using one learning rate for everything | backbone updates too aggressively | use smaller LR for pretrained layers |
forgetting requires_grad checks | wrong layers train silently | print trainable parameters |
| evaluating on training data only | hides overfitting | keep a validation set |
| preprocessing mismatch | pretrained features receive unfamiliar input scale | use the weights’ expected transform |
| leakage across splits | validation becomes meaningless | split by image source/user/object when needed |
Exercises
Section titled “Exercises”- Add a fourth target class and design a new synthetic pattern.
- Increase target training data from
12to40per class. Does head-only training improve? - Change the backbone fine-tuning learning rate from
0.0005to0.05. What happens? - Print only trainable parameter names after unfreezing the last convolution.
- Explain when GAP plus a small head is preferable to a large
Flattenhead.
Reference implementation and walkthrough
- A fourth synthetic class needs a pattern that is visually distinct, a new label index, and a classifier head with one more output unit.
- More target samples should make head-only training stronger because the new head sees more examples. Still compare validation accuracy, not only train accuracy.
0.05is usually too large for fine-tuning a reused backbone. Expect unstable loss or damaged pretrained features.- After unfreezing only the last convolution, the printed trainable names should include the classifier head plus that last convolution, not the whole backbone.
- GAP plus a small head is preferable when you want fewer parameters, better shape flexibility, and lower overfitting risk. A large
Flattenhead is fragile on small data.
Key Takeaways
Section titled “Key Takeaways”- Transfer learning reuses visual features instead of relearning everything from scratch.
- The safest first baseline is usually: replace head, freeze backbone, train head.
- Fine-tune later layers only when validation results justify it.
- Use smaller learning rates for pretrained layers.
- Good transfer learning is an engineering workflow, not just copying a large model.