E.C.3 Naive Bayes
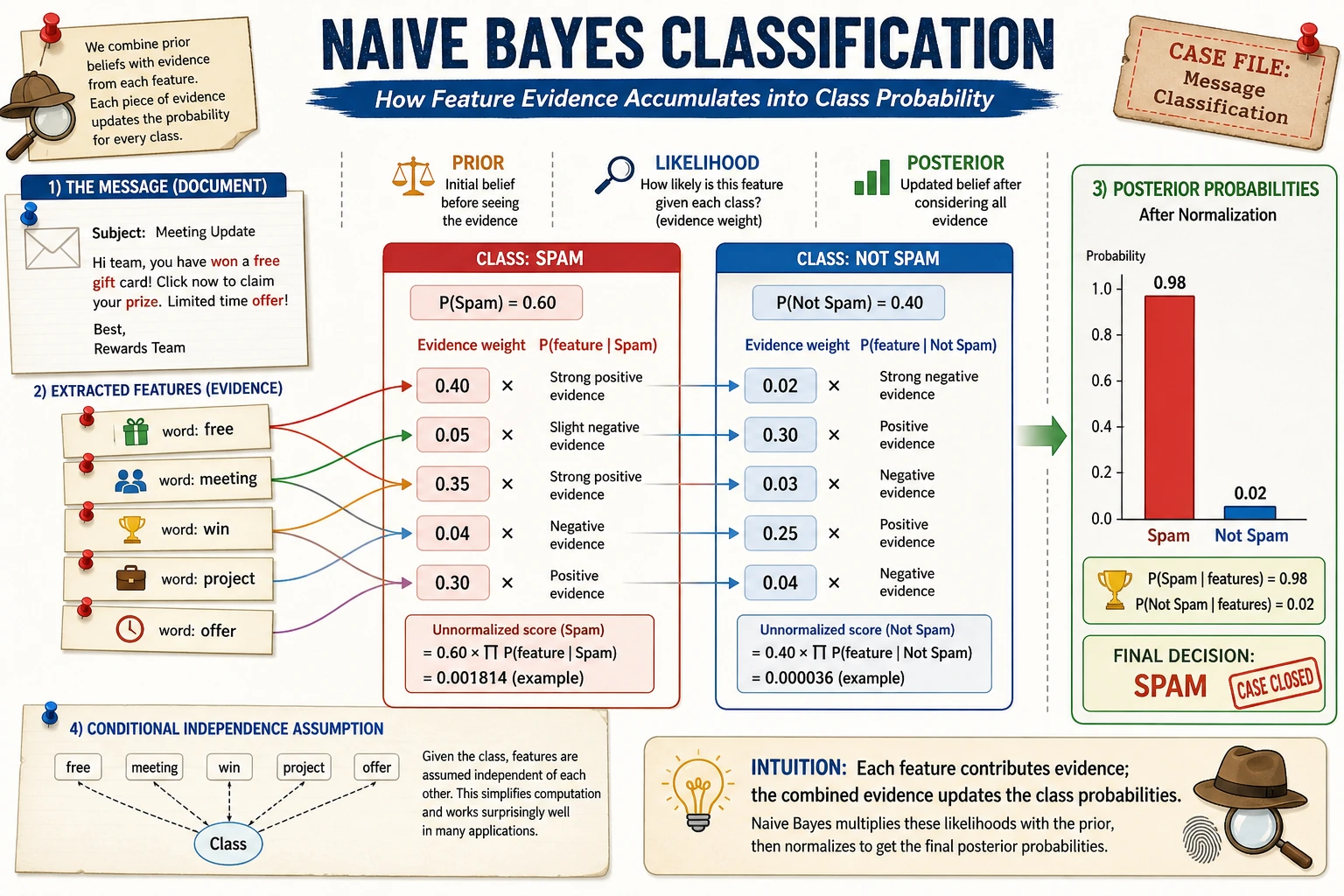
Naive Bayes compares which class is more likely to generate the observed evidence. In text tasks, word counts are often strong enough to create a cheap and useful baseline.
What You Need
Section titled “What You Need”- Python 3.10+
- Current stable
scikit-learn
python -m pip install -U scikit-learnKey Terms
Section titled “Key Terms”- Bag of words: represent text by word counts.
- Conditional probability: probability of evidence given a class.
- Naive assumption: features are treated as independent given the class.
- Smoothing: prevents unseen words from becoming impossible.
alpha: smoothing strength inMultinomialNB.
Run A Text Classifier
Section titled “Run A Text Classifier”Create naive_bayes_text.py:
from sklearn.feature_extraction.text import CountVectorizerfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.pipeline import make_pipeline
texts = [ "How long does a refund take?", "How do I apply for a refund?", "When can I issue an invoice?", "Where is the e-invoice sent?", "What should I do if I forget my password?", "Where is the password reset entry?",]
labels = [ "refund", "refund", "invoice", "invoice", "password", "password",]
model = make_pipeline( CountVectorizer(), MultinomialNB(alpha=1.0),)
model.fit(texts, labels)pred = model.predict([ "How do I handle a refund?", "When can I issue an e-invoice?",])print("predictions:", pred.tolist())Run it:
python naive_bayes_text.pyExpected output:
predictions: ['refund', 'invoice']This is a complete baseline: text to counts, counts to probabilities, probabilities to labels.
Baseline Review
Section titled “Baseline Review”Review Naive Bayes by looking at the evidence words for each class. If a class only works because of one accidental token, add more examples or improve preprocessing before blaming the algorithm.
This baseline is especially useful for routing tasks: support tickets, simple intent labels, document type classification, and quick spam-like filters. Its limitation is also clear: word order and deeper meaning are mostly ignored.
Change Smoothing
Section titled “Change Smoothing”Change alpha=1.0 to 0.1 and 2.0. With tiny datasets, smoothing can noticeably change how strongly the model trusts rare words.
Practical Rule
Section titled “Practical Rule”Try Naive Bayes when:
- The task is text classification.
- You need a quick baseline.
- Data is small or labels are simple.
- Interpretability matters.
Move to stronger models when semantics, context, or word order matter a lot.
Baseline Review
Section titled “Baseline Review”Review Naive Bayes by keeping the evidence counts that pushed the prediction. The useful question is not only “what label won,” but which words, tokens, or features moved the probability toward that label.
This model is strongest when the evidence is simple and explainable. It becomes weaker when features are heavily dependent or when rare tokens dominate. Keep one success case and one failure case so the baseline remains a comparison point, not a mysterious score.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Model Family
- SVM, KNN, Naive Bayes, LDA, or another classical baseline
- Dataset View
- feature scale, class balance, decision boundary, and train/test split
- Metric
- accuracy/F1, confusion matrix, margin, neighbor behavior, or projection quality
- Failure Check
- scaling, high dimensionality, weak assumptions, leakage, or poor baseline fit
- Expected Output
- classical-ML baseline result with one limitation note
Common Mistakes
Section titled “Common Mistakes”- Thinking “naive” means useless.
- Forgetting that feature representation still matters.
- Comparing it only with large models instead of using it as a cheap baseline.
Practice
Section titled “Practice”Add a certificate class with two examples. Then test whether a new certificate question is routed to the new label.
Reference implementation and walkthrough
A reasonable update adds two certificate labels and texts with words such as certificate, proof, or completion, then predicts a new certificate-related question. If the model returns certificate, the new class is at least reachable.
If it does not, inspect the vocabulary and smoothing rather than assuming the model is broken. With only two examples, Naive Bayes can be strongly affected by word choice, so the explanation should mention data coverage and not only the predicted label.