11.6.3 BERT Series
Learning Objectives
Section titled “Learning Objectives”- Understand why BERT became a milestone in NLP
- Clearly explain the core difference between BERT and autoregressive models like GPT
- Master key concepts such as
[CLS],[SEP],[MASK], and bidirectional context - Read a minimal BERT input example
- Understand common fine-tuning methods for BERT
Background: Which paper did BERT come from?
Section titled “Background: Which paper did BERT come from?”The most important historical milestone in this section is:
| Year | Paper | Key Authors | What it solved most importantly |
|---|---|---|---|
| 2018 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | Devlin et al. | Made bidirectional Transformer pretraining + fine-tuning the main path for modern NLP understanding tasks |
For beginners, the most important thing to remember first is:
- BERT is not “just another model name”
- It represents a very important paradigm shift:
First do general pretraining on massive text, then fine-tune the same base model for different tasks.
That is also why, when you learn large models today, many ideas about “pretrain first, then adapt” can be seen very clearly in BERT as an early prototype.
What problem did BERT actually solve?
Section titled “What problem did BERT actually solve?”First, the old problem: word meaning depends on context
Section titled “First, the old problem: word meaning depends on context”Words do not always have a fixed meaning.
For example, the English word bank:
- “river bank” means the riverbank
- “bank account” means a financial bank
The same is true in another English example:
- “I ate an apple” — apple means the fruit
- “Apple released a new device” — Apple means the company
If a model can only give each word a fixed vector, it will struggle.
BERT’s key breakthrough
Section titled “BERT’s key breakthrough”One of BERT’s core contributions is:
Making a word’s representation truly depend on context.
In other words, the same word can get different representations in different sentences.
This is called a “contextual representation.”
A better analogy for beginners
Section titled “A better analogy for beginners”You can think of BERT as:
- a “careful reader” that looks both before and after when reading a sentence
Unlike early static word vectors, which only give a word one fixed business card, it is more like:
- when the same word appears in different sentences, BERT re-understands the role it is playing now
That is why BERT is especially suitable for understanding tasks.
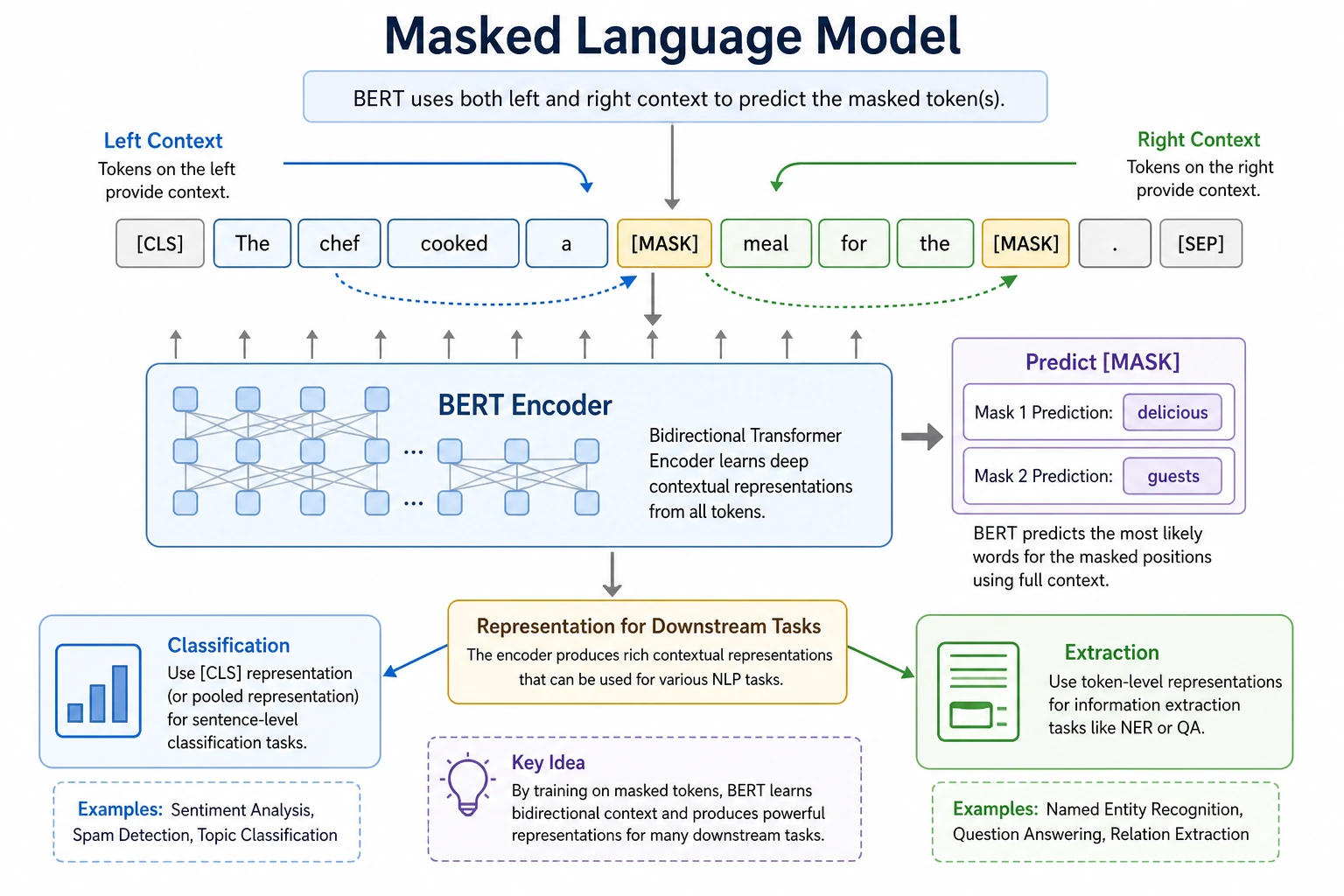
Why is BERT called a “bidirectional” model?
Section titled “Why is BERT called a “bidirectional” model?”What does bidirectional mean?
Section titled “What does bidirectional mean?”Consider the sentence:
“I took a walk next to the bank yesterday”
When understanding “bank,” people do not only look at the left context “I took a walk next to the,” but also the right context “yesterday.”
BERT’s important feature is:
The representation of the current token uses both left and right context at the same time.
The core difference from GPT
Section titled “The core difference from GPT”Roughly speaking:
- BERT: more focused on understanding, reads context bidirectionally
- GPT: more focused on generation, looks only at left history
So:
- For classification, extraction, and matching tasks, BERT is very strong
- For continuation, dialogue, and generation, the GPT route is more natural
What does BERT input actually look like?
Section titled “What does BERT input actually look like?”Three very common special tokens
Section titled “Three very common special tokens”| token | role |
|---|---|
[CLS] | Aggregation position for sentence-level tasks |
[SEP] | Sentence separator |
[MASK] | Position hidden during pretraining |
A minimal input example
Section titled “A minimal input example”tokens = ["[CLS]", "I", "love", "natural", "language", "processing", "[SEP]"]print(tokens)print("sequence length:", len(tokens))Expected output:
['[CLS]', 'I', 'love', 'natural', 'language', 'processing', '[SEP]']sequence length: 7The two boundary tokens are part of the actual sequence length. This matters because model cost and attention masks are calculated over the full token sequence, not only the visible words.
For sentence-pair tasks, such as question matching:
tokens = [ "[CLS]", "How", "is", "the", "weather", "today", "[SEP]", "Will", "it", "rain", "in", "Beijing", "today", "[SEP]"]print(tokens)Expected output:
['[CLS]', 'How', 'is', 'the', 'weather', 'today', '[SEP]', 'Will', 'it', 'rain', 'in', 'Beijing', 'today', '[SEP]']Notice that sentence pairs use two [SEP] markers: one to close sentence A and one to close sentence B. In a real BERT input, segment IDs then help the model distinguish the two sides.
A beginner-friendly input structure table
Section titled “A beginner-friendly input structure table”| Component | Most important thing to remember |
|---|---|
[CLS] | Aggregation position for sentence-level tasks |
[SEP] | Sentence boundary separator |
[MASK] | Position to be recovered during pretraining |
This table is especially helpful for beginners because it turns BERT input from a “mysterious token string” into a few understandable parts.
What does BERT do during pretraining?
Section titled “What does BERT do during pretraining?”The classic task: Masked Language Modeling
Section titled “The classic task: Masked Language Modeling”BERT’s most classic training objective is MLM, which means:
Hide some tokens in a sentence and let the model guess them back from context.
For example:
“I love [MASK] language processing”
The model must infer what [MASK] is from the surrounding context.
A minimal runnable example
Section titled “A minimal runnable example”tokens = ["[CLS]", "I", "love", "[MASK]", "language", "processing", "[SEP]"]mask_index = tokens.index("[MASK]")
candidates = ["natural", "machine", "deep"]
print("tokens =", tokens)print("mask index =", mask_index)print("candidate fill-ins =", candidates)Expected output:
tokens = ['[CLS]', 'I', 'love', '[MASK]', 'language', 'processing', '[SEP]']mask index = 3candidate fill-ins = ['natural', 'machine', 'deep']The index tells you exactly where the model must predict. In a real MLM model, the candidate with the highest score would be selected from the whole vocabulary, not from this tiny hand-written list.
This example is not actually training a model, but it already teaches you:
- the
[MASK]position is explicit - the model’s job is to recover the hidden information
- predictions at the current position depend on bidirectional context
Why is this important?
Section titled “Why is this important?”Because it forces the model to truly understand:
- what is said on the left
- what is said on the right
- what should go in the hidden position
This makes BERT very good at understanding tasks.
The safest default learning order for BERT
Section titled “The safest default learning order for BERT”A more stable order is usually:
- First understand what bidirectional context is filling in
- Then look at the most common tokens:
[CLS] / [SEP] / [MASK] - Then see what MLM asks the model to learn during training
- Finally look at how fine-tuning attaches a classification head
This is easier than jumping straight into paper details and large-model parameters.
BERT input is not just tokens
Section titled “BERT input is not just tokens”Token Embedding
Section titled “Token Embedding”Each token is first turned into a vector.
Position Embedding
Section titled “Position Embedding”The model also needs to know the order, so positional encoding must be added.
Segment Embedding
Section titled “Segment Embedding”For sentence-pair tasks, the model also needs to know “which tokens belong to sentence A” and “which tokens belong to sentence B”.
You can think of BERT input as the sum of three parts:
final input representation = token embedding + position embedding + segment embedding
This step is important because Transformer itself does not inherently contain sequence-order awareness.
A truly runnable offline BERT example
Section titled “A truly runnable offline BERT example”The example below does not require downloading pretrained weights. You only need to install transformers and torch, and you can initialize a small random BERT locally. It is mainly here to help you understand input/output shapes.
import torchfrom transformers import BertConfig, BertModel
config = BertConfig( vocab_size=100, hidden_size=32, num_hidden_layers=2, num_attention_heads=4, intermediate_size=64)
model = BertModel(config)
input_ids = torch.tensor([ [1, 5, 8, 9, 2, 0, 0], # a shorter sample, padded with 0s at the end [1, 7, 6, 3, 4, 2, 0]])
attention_mask = torch.tensor([ [1, 1, 1, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 0]])
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
print("last_hidden_state shape:", outputs.last_hidden_state.shape)print("pooler_output shape :", outputs.pooler_output.shape)Expected output:
last_hidden_state shape: torch.Size([2, 7, 32])pooler_output shape : torch.Size([2, 32])The model is randomly initialized, so the numeric values are not meaningful predictions. The useful part is the shape: 2 samples, 7 positions per sample, and 32 hidden dimensions per token.
How should we understand the outputs?
Section titled “How should we understand the outputs?”-
last_hidden_state- shape:
[batch, seq_len, hidden_size] - each token has a contextual representation
- shape:
-
pooler_output- shape:
[batch, hidden_size] - usually can be understood as one kind of whole-sentence summary representation
- shape:
This also explains why BERT is suitable for:
- token-level tasks: use
last_hidden_state - sentence-level tasks: use
[CLS]or sentence-level representations
How do we use BERT for classification?
Section titled “How do we use BERT for classification?”Typical workflow
Section titled “Typical workflow”The most common approach is:
- Input a sentence
- Pass it through BERT
- Take
[CLS]or a sentence representation - Attach a linear classification head
This is the classic fine-tuning approach.
A small conceptual example
Section titled “A small conceptual example”import torchfrom torch import nn
# Assume this is the [CLS] representation output by BERTcls_embedding = torch.randn(4, 32) # batch=4, hidden=32
# Attach a classification headclassifier = nn.Linear(32, 2)logits = classifier(cls_embedding)
print("logits shape:", logits.shape)Expected output:
logits shape: torch.Size([4, 2])This means the batch has 4 samples and the classifier returns 2 raw scores for each sample. A real classifier would usually apply softmax or cross-entropy on top of these logits.
This code is very simple, but it teaches you something very important:
BERT is often not the end of a task, but a powerful representation layer.
What is most worth showing when BERT is used in a project
Section titled “What is most worth showing when BERT is used in a project”What is usually most worth showing is not:
- “I used BERT”
but rather:
- What the input text looks like
- How the
[CLS]representation connects to the classification head - What it does better than traditional representations or lighter models
- Which failure cases it still gets wrong
That way, other people can more easily see:
- you understand BERT’s role in the task pipeline
- you did more than just change the model name
What tasks is BERT good for?
Section titled “What tasks is BERT good for?”Especially suitable for
Section titled “Especially suitable for”- Text classification
- Sentence-pair matching
- Named entity recognition
- Extractive question answering
Where it is less natural
Section titled “Where it is less natural”BERT itself was not designed for free-form long-text generation. If the task focus is:
- long conversation generation
- continuation
- large-scale text creation
then the GPT route is usually more natural.
Why is BERT no longer the only main character?
Section titled “Why is BERT no longer the only main character?”The reason is not that BERT is useless, but that the ecosystem kept moving forward
Section titled “The reason is not that BERT is useless, but that the ecosystem kept moving forward”Later NLP and LLM development brought:
- larger-scale pretraining
- stronger generative models
- more unified task interfaces
So today, many applications more often discuss GPT, T5, and Llama-style routes.
But BERT is still very worth learning
Section titled “But BERT is still very worth learning”Because it helps you truly understand:
- contextual representations
- encoder-only models
- the pretraining + fine-tuning paradigm
- the difference between token-level and sentence-level tasks
These are all important foundations for learning large models later.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Model Choice
- BERT, GPT, T5, Transformers pipeline, or other pretrained baseline
- Tokenizer Output
- ids, masks, decoded text, or batch shape
- Task Result
- classification, generation, extraction, or text-to-text output
- Failure Check
- wrong model family, token limit, domain mismatch, cost, or latency
- Expected Output
- model call result plus a short choice rationale
Common beginner mistakes
Section titled “Common beginner mistakes”Mixing up BERT and GPT as if they were the same thing
Section titled “Mixing up BERT and GPT as if they were the same thing”They are both important, but their training objectives and strengths are not the same.
Thinking [CLS] is “naturally the best sentence vector”
Section titled “Thinking [CLS] is “naturally the best sentence vector””It is useful in many tasks, but it is not a universal best choice.
Only knowing “use BERT for classification” without knowing what it actually learns
Section titled “Only knowing “use BERT for classification” without knowing what it actually learns”What you really need to master is:
- why it is bidirectional
- why MLM works
- why it is better suited to understanding tasks
Summary
Section titled “Summary”The most important thing in this section is not memorizing BERT’s full name, but grasping these three points:
- BERT is a representative model of bidirectional context modeling
- It learns to “understand tokens from context” through MLM
- It is very suitable for understanding tasks and the fine-tuning paradigm
Once you understand these three points, many differences will become naturally clear when you later learn GPT, T5, and LLMs.
Exercises
Section titled “Exercises”- Create a sentence with
[MASK]by yourself, and write the candidate word(s) you think are most reasonable. - Change
hidden_sizein the offline BERT example to 64, then see how the output shape changes. - Think about this: why can a training objective like “I love [MASK] language processing” help the model learn bidirectional understanding?
- Explain in your own words: what is the core difference between BERT and GPT in the way they “look at context”?
Reference implementation and walkthrough
- A valid
[MASK]example should have enough left and right context for multiple plausible candidates, such as “I love [MASK] language processing.” - If
hidden_sizebecomes 64, the last hidden state should end with dimension 64 instead of the previous hidden dimension. - Masked language modeling helps bidirectional understanding because the model must use both left and right context to infer the missing token.
- BERT reads context bidirectionally for understanding tasks; GPT reads causally from left to right for next-token generation.