8.0 Learning Checklist: LLM Application Development and RAG
Use this page as a printable checklist. If you need the full explanation, return to the Chapter 8 entry page.
Two-Hour First Pass
Section titled “Two-Hour First Pass”| Time box | Do this | Stop when you can say |
|---|---|---|
| 20 min | Read the RAG application loop on the entry page | ”A RAG answer should be tied to retrieved evidence.” |
| 25 min | Run the tiny RAG script | ”I can inspect top-k chunks before trusting the answer.” |
| 25 min | Skim 8.1 RAG basics and document processing | ”Chunk size, overlap, and metadata affect retrieval and citations.” |
| 25 min | Skim 8.3 API practice and tool/function calling | ”An LLM app needs request, response, error, and retry paths.” |
| 25 min | Read the debugging ladder | ”I can separate document, retrieval, generation, citation, and ops failures.” |
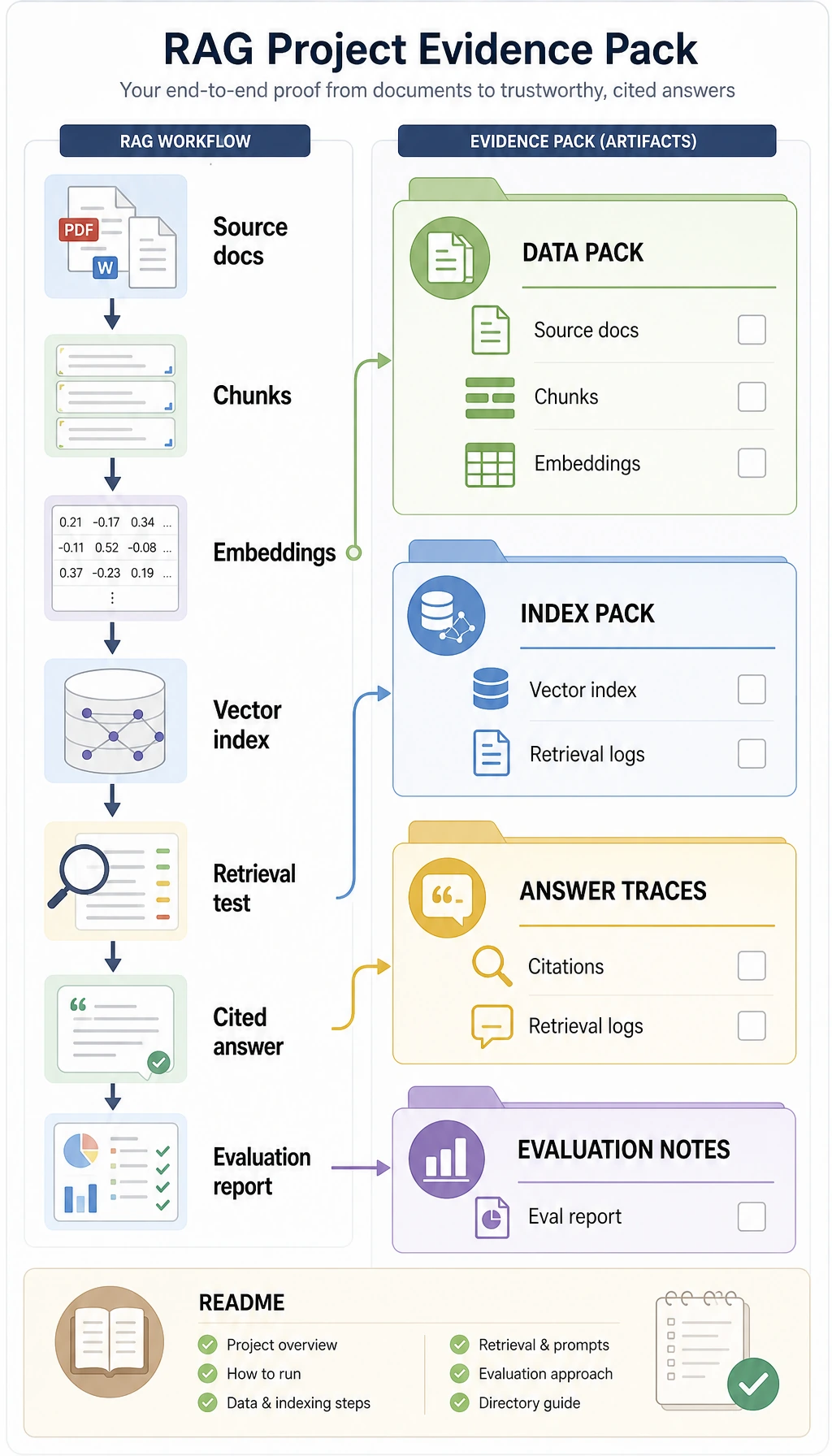
Required Evidence
Section titled “Required Evidence”| Evidence | Minimum version |
|---|---|
chunks.jsonl | 5-10 chunks with id, source, text, and version |
retrieval_logs.jsonl | query, top-k chunk IDs, score, and source for each test question |
eval_questions.csv | at least 10 fixed questions with expected source or answer points |
failure_cases.md | at least three failures labeled as document, chunking, retrieval, generation, citation, or deploy |
rag_config.md | chunk size, overlap, top-k, rerank choice, prompt version |
context_strategy.md | long context, RAG, memory, or hybrid decision with one rejected alternative |
rag_app_workshop_output.txt | output from 8.5.6 Hands-on: Full Chapter 8 RAG App Workshop |
README.md | run command, sample question, cited answer, evaluation result, next fix |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Rag Eval Set
- fixed questions with expected evidence
- Retrieval Trace
- query, chunks, scores, selected evidence
- Answer Trace
- cited answer and unsupported claim check
- App Trace
- request, response, validation, logs
- Project Readme
- run command, metrics, failures, next action
Quality Gates
Section titled “Quality Gates”| Gate | Pass condition |
|---|---|
| Citation | Every factual answer cites a chunk, source, and version. |
| Empty retrieval | System refuses to answer when evidence is missing. |
| Regression eval | Same questions run before and after each chunking, retrieval, reranking, or prompt change. |
| Operations | Logs include query, top-k, prompt version, latency, token cost, and failure label. |
Expected result: your Chapter 8 project folder contains chunks, retrieval logs, fixed eval questions, cited answers, failure labels, app logs, and a README that explains the next retrieval or generation fix.
Exit Questions
Section titled “Exit Questions”- Can you explain why RAG is different from asking a longer Prompt?
- Can you show which document chunks were retrieved for a question?
- Can you explain why chunk metadata is necessary for citations and debugging?
- Can you handle empty retrieval with a no-answer response instead of a guess?
- Can you compare two RAG versions using the same evaluation questions?
- Can you explain when long context is simpler than RAG, and when RAG or memory is still required?
Check reasoning and explanation
- RAG is different because it retrieves evidence before answering. A longer Prompt still depends on what the model already knows or guesses, while RAG can pull fresh, private, or document-based facts into the answer.
- Show the query, top-k chunks, scores, source, and version so someone else can check the retrieval path.
- Metadata keeps the source, version, and location attached to each chunk, which makes citation, debugging, and regression analysis possible.
- When retrieval is empty, the safest response is a no-answer or needs-more-information reply, not a guess.
- Use the same evaluation questions before and after retrieval, chunking, or reranking changes so the comparison stays fair.
If the answer is yes, move to Chapter 9. Chapter 9 will upgrade the system from answer generation to Agents that can plan, call tools, and recover from failures.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Rag Eval Set
- fixed questions with expected evidence
- Retrieval Trace
- query, chunks, scores, selected evidence
- Answer Trace
- cited answer and unsupported claim check
- App Trace
- request, response, validation, logs
- Project Readme
- run command, metrics, failures, next action