6.8.5 Hands-on Workshop: Build a PyTorch Training Evidence Pack
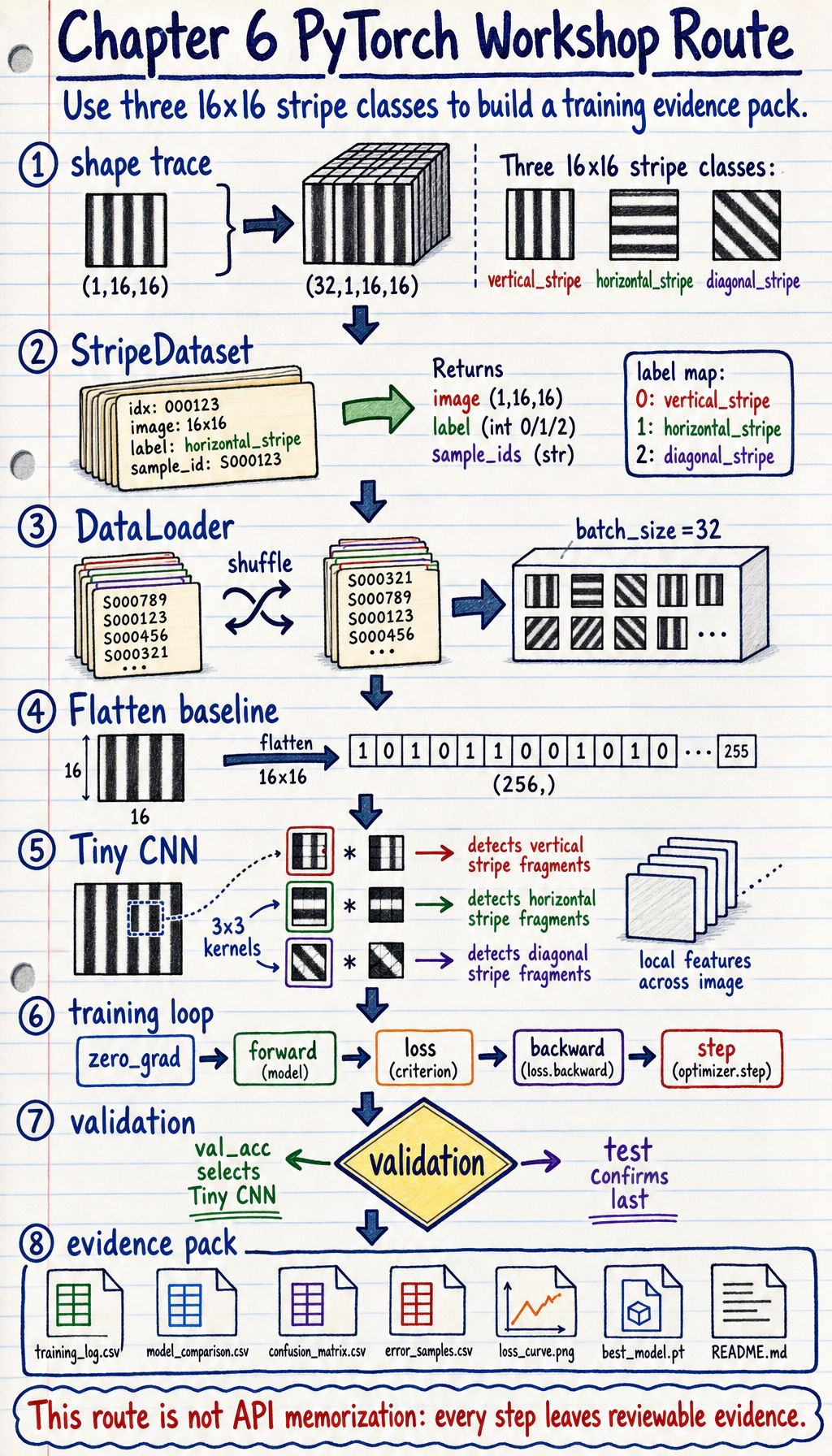
Learning Objectives
Section titled “Learning Objectives”- Build a tiny image classification dataset locally without downloads
- Compare a simple
Flatten + Linearbaseline with a small CNN - Use
Dataset,DataLoader,nn.Module, loss, optimizer, and validation correctly - Save training logs, model comparison, confusion matrix, review samples, a loss curve, and a checkpoint
- Explain common deep learning failures: shape mismatch, loss not decreasing, overfitting, and memory pressure
What You Will Build
Section titled “What You Will Build”This workshop creates a local folder called deep_learning_workshop_run/.
The task is:
Classify small synthetic 16x16 grayscale images into vertical stripe, horizontal stripe, or diagonal stripe.
The dataset is generated by code. That keeps the exercise runnable on CPU, avoids dataset downloads, and still lets you practice the same engineering habits used in real image and text projects.
| Chapter 6 idea | What you will do in the project |
|---|---|
| Tensor shape | Trace (batch, channel, height, width) before training |
| Dataset | Wrap images, labels, and sample ids in a custom Dataset |
| DataLoader | Batch and shuffle the training data |
| Baseline | Train a Flatten + Linear model first |
| CNN | Train a small convolutional network |
| Training loop | Run zero_grad -> forward -> loss -> backward -> step |
| Validation | Choose the best model with validation accuracy |
| Evidence | Save logs, curves, errors, checkpoint, and README |
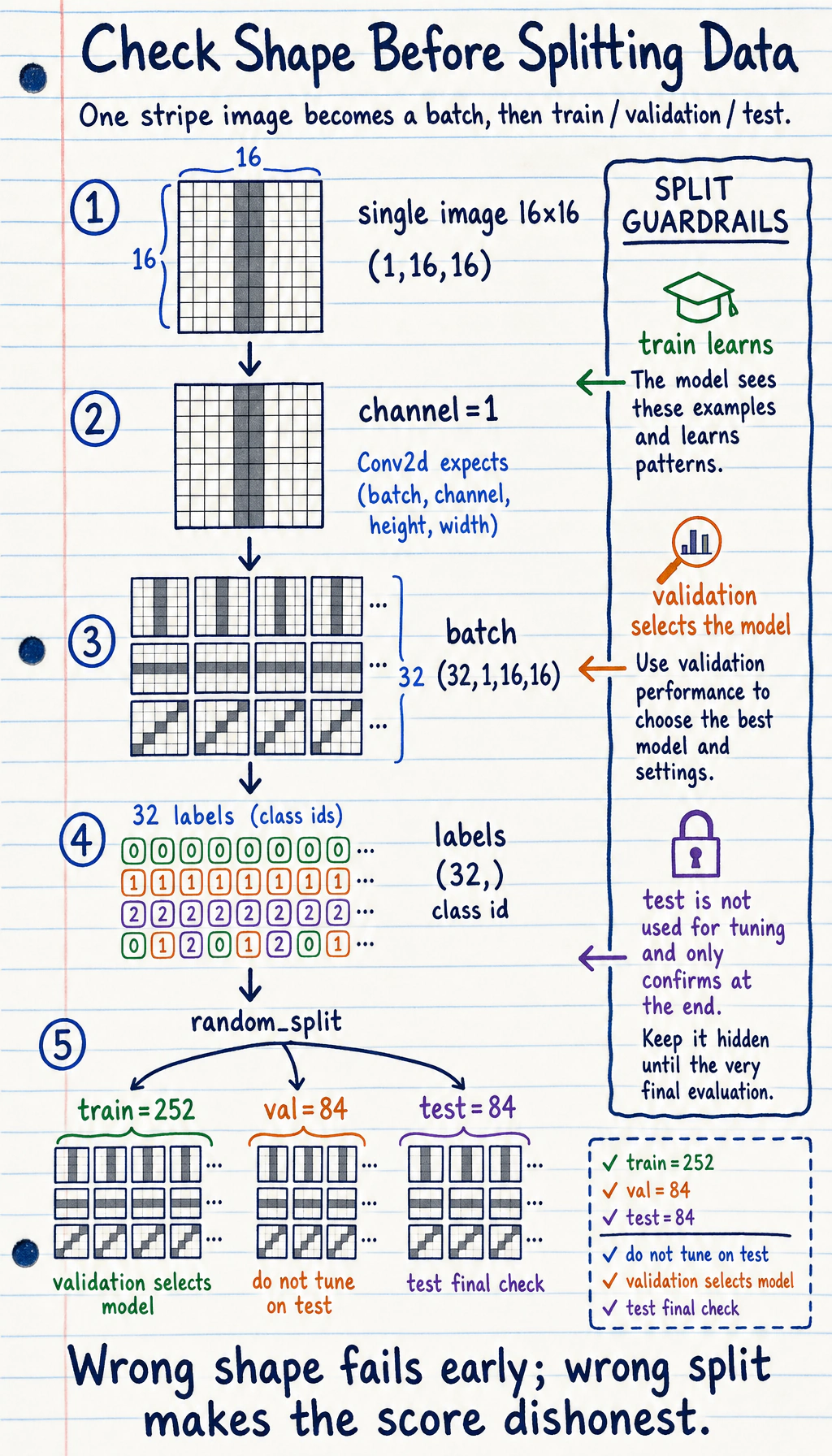
Mental Model: One Image, One Batch, Three Splits
Section titled “Mental Model: One Image, One Batch, Three Splits”Before you run the script, keep this map in your head:
- One generated image is a tensor with shape
(1, 16, 16): one grayscale channel, height 16, width 16. - A mini-batch becomes
(32, 1, 16, 16): 32 images processed together. - The label batch is
(32,): one integer class id for each image. train_setteaches the model,val_setchooses between models, andtest_setis held back for the final score.
The split matters. If you tune learning rate, epochs, or model width by repeatedly looking at the test set, the test score stops being honest. This small workshop uses random_split with a fixed seed so you can rerun it and get the same teaching evidence.
Evidence Flow: From Training Run to Report
Section titled “Evidence Flow: From Training Run to Report”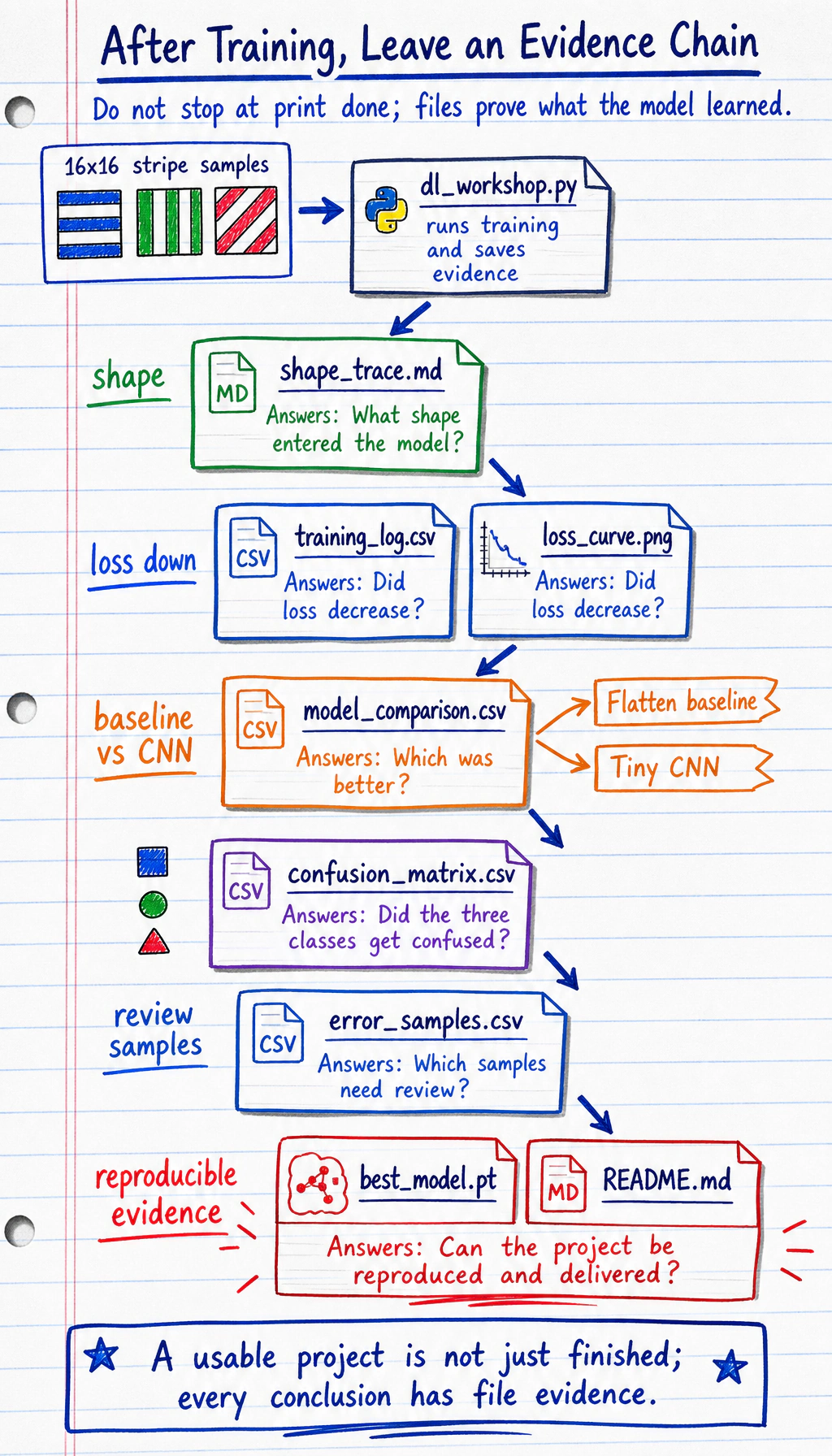
A beginner mistake is stopping at:
loss.backward()optimizer.step()print("done")That does not prove the training process is healthy. A usable deep learning project should answer:
- What shapes entered the model?
- Did the loss actually decrease?
- Did validation improve, or only training?
- Which model beat the baseline?
- Which samples should be reviewed?
- Can someone rerun the project from a clean folder?
The script below creates this evidence pack:
outputs/training_log.csv: training and validation metrics for each epoch.outputs/model_comparison.csv: baseline versus CNN comparison.outputs/confusion_matrix.csv: class-level error distribution.outputs/error_samples.csv: failed or low-confidence samples to review.outputs/metrics_summary.json: final model and test metric summary.curves/loss_curve.png: training/validation loss curve.checkpoints/best_model.pt: loadable best model state.reports/shape_trace.md: batch, label, and logits shape records.reports/debug_checklist.md: debugging checklist.README.md: rerun command, result summary, and next step.
Evidence to Keep
Section titled “Evidence to Keep”The workshop is complete when the folder proves the full training loop:
- Shape Trace
- one batch shape and logits shape
- Training Log
- train and validation curves
- Model Comparison
- baseline vs CNN
- Confusion Matrix
- class-level errors
- Error Samples
- concrete failures to inspect
- Checkpoint
- best model can be restored
- README
- command, metrics, limitations, next step
Terms to Decode Before Running
Section titled “Terms to Decode Before Running”- Tensor: a multi-dimensional array. In this workshop, one image batch has shape
(batch, channel, height, width). - Logits: raw model outputs before softmax.
CrossEntropyLossexpects logits, not probabilities. - Epoch: one full pass over the training set.
- Validation set: data used to choose a model during development. It is not the same as the final test set.
- Checkpoint: a saved model state that can be loaded later.
- CNN: Convolutional Neural Network, a network that learns local visual patterns with convolution kernels.
- Overfitting: training improves but validation does not; the model is memorizing too much.
Prepare the Environment
Section titled “Prepare the Environment”Inside this course repository, install the core and AI runtime:
python -m pip install -r requirements-course-core.txt -r requirements-course-ai.txtIf you are working in a separate folder, this workshop only needs PyTorch and Matplotlib:
python -m pip install torch matplotlibThe official PyTorch install page describes the Stable build as the currently tested and supported version. This workshop uses stable PyTorch 2.x core APIs and does not require torchvision, a GPU, or any downloaded dataset. It was verified locally with Python 3.13 and PyTorch 2.11.
Run the Complete Workshop
Section titled “Run the Complete Workshop”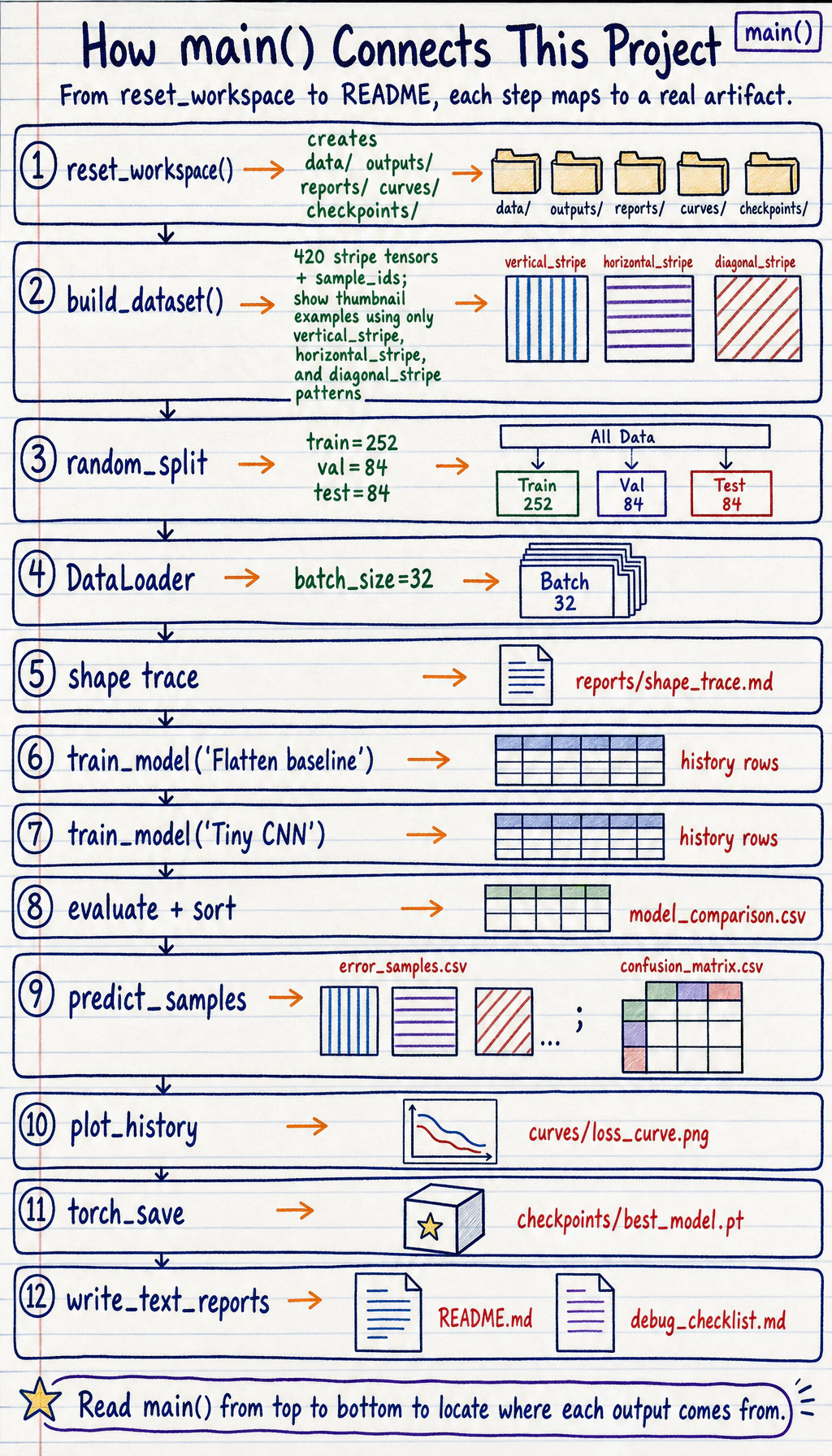
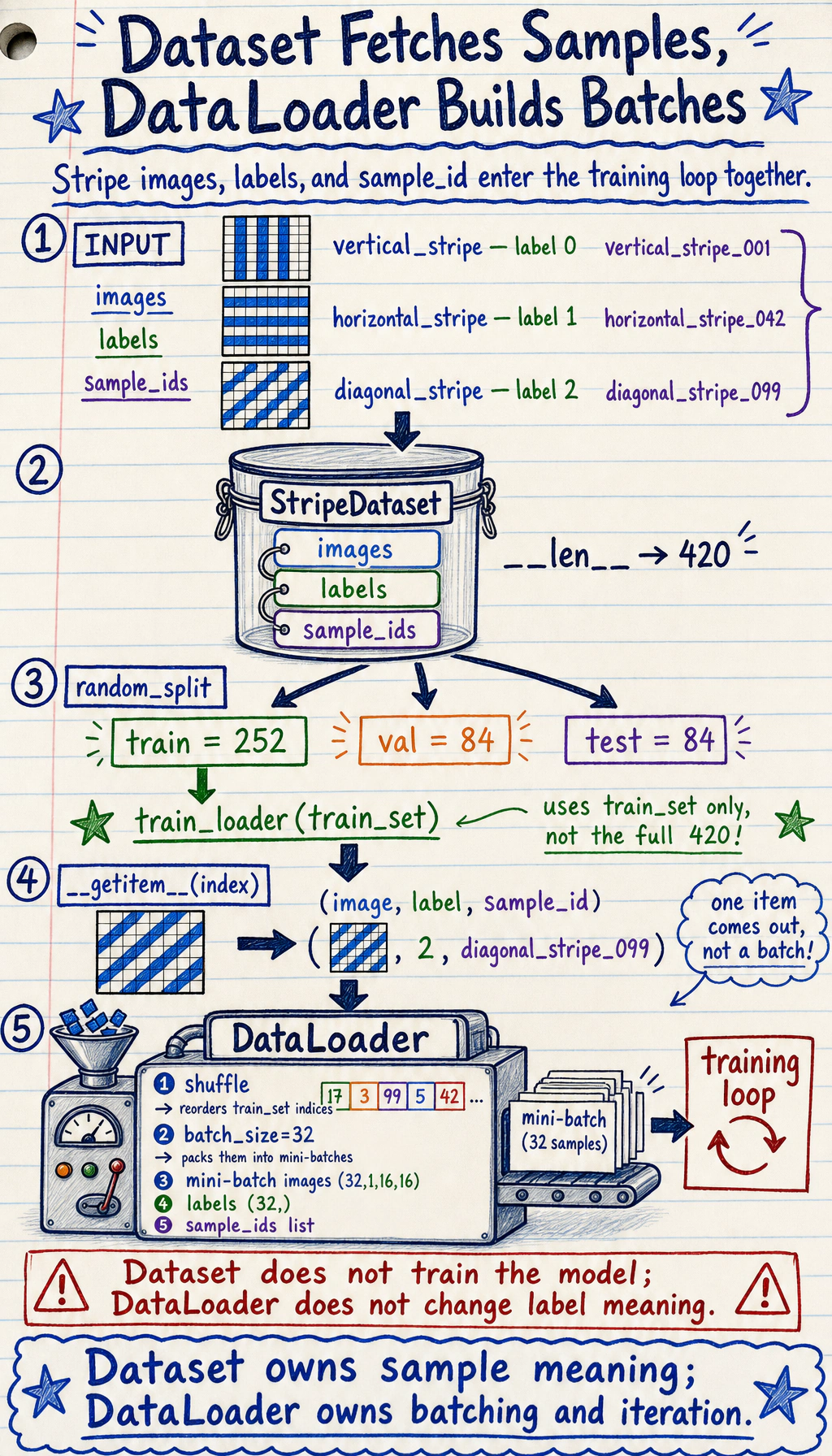
The code has three layers:
StripeDatasetknows how many samples exist and how to return one(image, label, sample_id)record.DataLoaderturns many individual records into shuffled mini-batches.- The training loop consumes those mini-batches and updates model parameters.
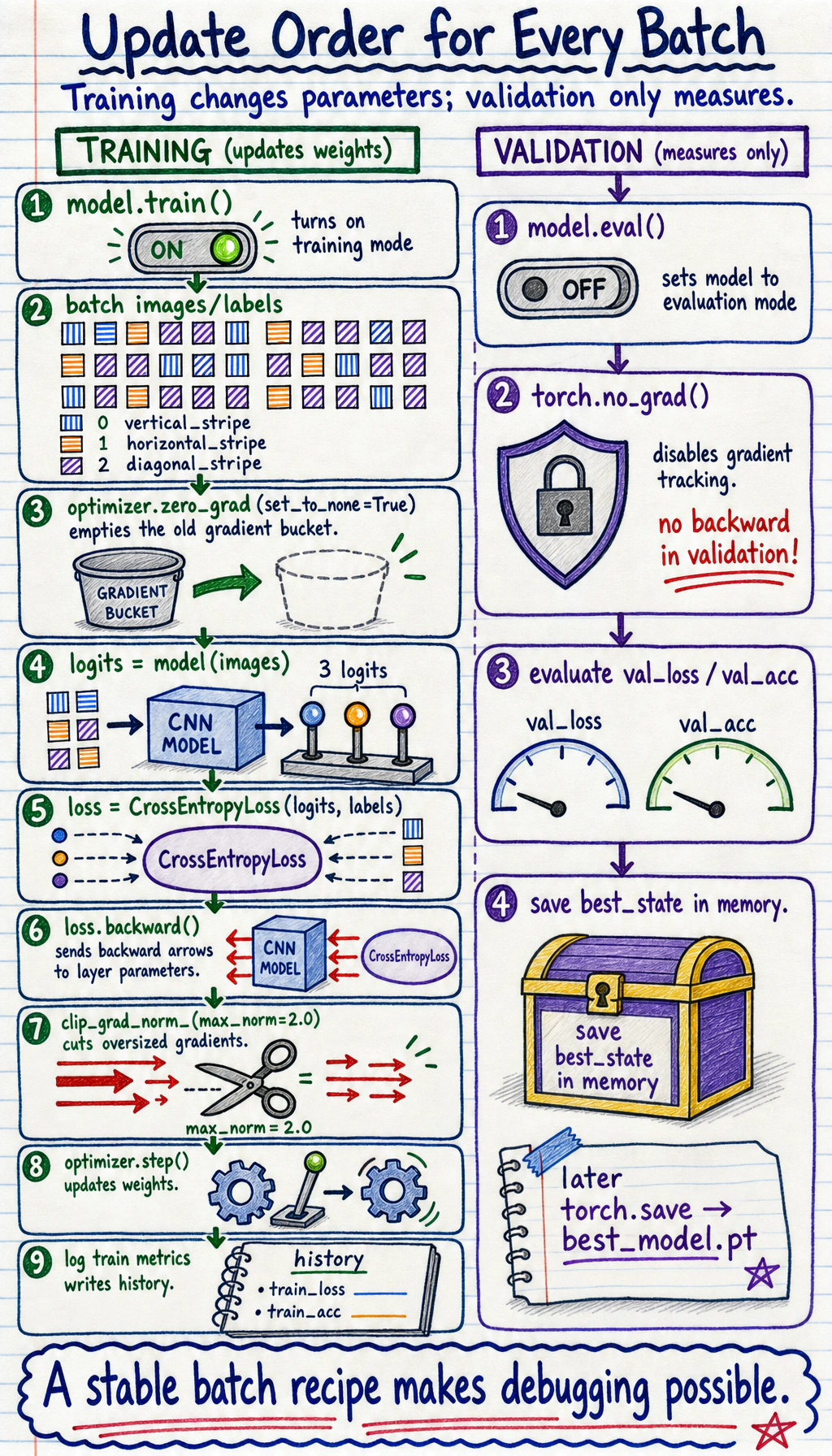
For each training batch, read the loop as an ordered recipe: clear old gradients, run the model, compute loss, backpropagate, clip very large gradients, and step the optimizer. Validation uses model.eval() and torch.no_grad() because it measures the model without changing it.
Create a Clean Folder
Section titled “Create a Clean Folder”mkdir ch06-dl-workshopcd ch06-dl-workshopCreate dl_workshop.py
Section titled “Create dl_workshop.py”Copy the code below into dl_workshop.py.
from __future__ import annotations
import copyimport csvimport jsonimport mathimport shutilfrom pathlib import Path
import matplotlib
matplotlib.use("Agg")import matplotlib.pyplot as pltimport torchfrom torch import nnfrom torch.utils.data import DataLoader, Dataset, random_split
RUN_DIR = Path("deep_learning_workshop_run")DATA_DIR = RUN_DIR / "data"OUTPUT_DIR = RUN_DIR / "outputs"REPORT_DIR = RUN_DIR / "reports"CURVE_DIR = RUN_DIR / "curves"CHECKPOINT_DIR = RUN_DIR / "checkpoints"
CLASSES = ["vertical_stripe", "horizontal_stripe", "diagonal_stripe"]IMAGE_SIZE = 16SAMPLES_PER_CLASS = 140BATCH_SIZE = 32SEED = 42
def reset_workspace() -> None: if RUN_DIR.exists(): shutil.rmtree(RUN_DIR) for folder in (DATA_DIR, OUTPUT_DIR, REPORT_DIR, CURVE_DIR, CHECKPOINT_DIR): folder.mkdir(parents=True, exist_ok=True)
class StripeDataset(Dataset): def __init__(self, images: torch.Tensor, labels: torch.Tensor, sample_ids: list[str]): self.images = images.float() self.labels = labels.long() self.sample_ids = sample_ids
def __len__(self) -> int: return len(self.labels)
def __getitem__(self, index: int): return self.images[index], self.labels[index], self.sample_ids[index]
def make_stripe_image(label: int, generator: torch.Generator) -> torch.Tensor: image = torch.randn((IMAGE_SIZE, IMAGE_SIZE), generator=generator) * 0.20 if label == 0: col = int(torch.randint(1, IMAGE_SIZE - 2, (1,), generator=generator)) image[:, col : col + 2] += 1.0 elif label == 1: row = int(torch.randint(1, IMAGE_SIZE - 2, (1,), generator=generator)) image[row : row + 2, :] += 1.0 else: offset = int(torch.randint(-3, 4, (1,), generator=generator)) for row in range(IMAGE_SIZE): col = row + offset if 0 <= col < IMAGE_SIZE: image[row, col] += 1.1 if col + 1 < IMAGE_SIZE: image[row, col + 1] += 0.8
if float(torch.rand((), generator=generator)) < 0.18: top = int(torch.randint(0, IMAGE_SIZE - 4, (1,), generator=generator)) left = int(torch.randint(0, IMAGE_SIZE - 4, (1,), generator=generator)) image[top : top + 4, left : left + 4] *= 0.25 return image.clamp(-1.0, 1.5).unsqueeze(0)
def build_dataset(seed: int = SEED) -> StripeDataset: generator = torch.Generator().manual_seed(seed) images = [] labels = [] sample_ids = [] for label, class_name in enumerate(CLASSES): for index in range(SAMPLES_PER_CLASS): images.append(make_stripe_image(label, generator)) labels.append(label) sample_ids.append(f"{class_name}_{index:03d}") return StripeDataset(torch.stack(images), torch.tensor(labels), sample_ids)
class FlattenBaseline(nn.Module): def __init__(self): super().__init__() self.net = nn.Sequential(nn.Flatten(), nn.Linear(IMAGE_SIZE * IMAGE_SIZE, len(CLASSES)))
def forward(self, x: torch.Tensor) -> torch.Tensor: return self.net(x)
class TinyCNN(nn.Module): def __init__(self): super().__init__() self.features = nn.Sequential( nn.Conv2d(1, 8, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(), nn.AdaptiveAvgPool2d((1, 1)), ) self.classifier = nn.Linear(16, len(CLASSES))
def forward(self, x: torch.Tensor) -> torch.Tensor: x = self.features(x) x = torch.flatten(x, 1) return self.classifier(x)
def evaluate(model: nn.Module, loader: DataLoader, loss_fn: nn.Module) -> tuple[float, float]: model.eval() total_loss = 0.0 total_correct = 0 total_examples = 0 with torch.no_grad(): for images, labels, _sample_ids in loader: logits = model(images) loss = loss_fn(logits, labels) total_loss += float(loss.item()) * len(labels) total_correct += int((logits.argmax(dim=1) == labels).sum().item()) total_examples += len(labels) return total_loss / total_examples, total_correct / total_examples
def train_model(name: str, model: nn.Module, train_loader: DataLoader, val_loader: DataLoader, *, epochs: int, lr: float): loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=lr) history = [] best_state = copy.deepcopy(model.state_dict()) best_val_acc = -math.inf
for epoch in range(1, epochs + 1): model.train() total_loss = 0.0 total_correct = 0 total_examples = 0 for images, labels, _sample_ids in train_loader: optimizer.zero_grad(set_to_none=True) logits = model(images) loss = loss_fn(logits, labels) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=2.0) optimizer.step()
total_loss += float(loss.item()) * len(labels) total_correct += int((logits.argmax(dim=1) == labels).sum().item()) total_examples += len(labels)
train_loss = total_loss / total_examples train_acc = total_correct / total_examples val_loss, val_acc = evaluate(model, val_loader, loss_fn) history.append( { "model": name, "epoch": epoch, "train_loss": round(train_loss, 4), "train_acc": round(train_acc, 4), "val_loss": round(val_loss, 4), "val_acc": round(val_acc, 4), } ) if val_acc > best_val_acc: best_val_acc = val_acc best_state = copy.deepcopy(model.state_dict())
model.load_state_dict(best_state) return history, best_val_acc
def predict_samples(model: nn.Module, loader: DataLoader) -> list[dict]: model.eval() rows = [] with torch.no_grad(): for images, labels, sample_ids in loader: logits = model(images) probabilities = torch.softmax(logits, dim=1) confidence, predictions = probabilities.max(dim=1) for sample_id, actual, pred, conf in zip(sample_ids, labels.tolist(), predictions.tolist(), confidence.tolist()): rows.append( { "sample_id": sample_id, "actual": CLASSES[actual], "predicted": CLASSES[pred], "confidence": round(float(conf), 4), "correct": actual == pred, } ) return rows
def confusion_matrix_rows(prediction_rows: list[dict]) -> list[list[str | int]]: matrix = [[0 for _ in CLASSES] for _ in CLASSES] name_to_index = {name: index for index, name in enumerate(CLASSES)} for row in prediction_rows: matrix[name_to_index[row["actual"]]][name_to_index[row["predicted"]]] += 1 return [["actual/predicted", *CLASSES], *[[CLASSES[i], *matrix[i]] for i in range(len(CLASSES))]]
def write_csv(path: Path, rows: list[dict]) -> None: with path.open("w", newline="", encoding="utf-8") as file: writer = csv.DictWriter(file, fieldnames=list(rows[0].keys())) writer.writeheader() writer.writerows(rows)
def write_matrix_csv(path: Path, rows: list[list[str | int]]) -> None: with path.open("w", newline="", encoding="utf-8") as file: csv.writer(file).writerows(rows)
def plot_history(history: list[dict]) -> None: grouped = {} for row in history: grouped.setdefault(row["model"], []).append(row)
plt.figure(figsize=(8, 5)) for name, rows in grouped.items(): epochs = [row["epoch"] for row in rows] plt.plot(epochs, [row["train_loss"] for row in rows], label=f"{name} train_loss") plt.plot(epochs, [row["val_loss"] for row in rows], linestyle="--", label=f"{name} val_loss") plt.xlabel("epoch") plt.ylabel("loss") plt.title("Training and validation loss") plt.legend() plt.tight_layout() plt.savefig(CURVE_DIR / "loss_curve.png", dpi=140) plt.close()
def write_text_reports(summary: dict, shape_trace: str) -> None: (REPORT_DIR / "shape_trace.md").write_text(shape_trace, encoding="utf-8") (REPORT_DIR / "debug_checklist.md").write_text( "\n".join( [ "# Debug Checklist", "", "- If the loss does not decrease, lower the learning rate and verify labels.", "- If shapes do not match, print one batch and one logits tensor first.", "- If training accuracy rises but validation accuracy stalls, suspect overfitting.", "- If results change every run, check random seeds and DataLoader shuffle settings.", "- If GPU memory is exhausted, reduce batch size or image size before changing the model.", ] ) + "\n", encoding="utf-8", ) (RUN_DIR / "README.md").write_text( "\n".join( [ "# Deep Learning Workshop Evidence Pack", "", "Run command:", "", "```bash", "python dl_workshop.py", "```", "", f"Best model: {summary['best_model']}", f"Test accuracy: {summary['test_accuracy']}", "", "Evidence files:", "- outputs/training_log.csv", "- outputs/model_comparison.csv", "- outputs/confusion_matrix.csv", "- outputs/error_samples.csv", "- curves/loss_curve.png", "- reports/shape_trace.md", "- reports/debug_checklist.md", ] ) + "\n", encoding="utf-8", )
def main() -> None: torch.manual_seed(SEED) reset_workspace()
dataset = build_dataset() generator = torch.Generator().manual_seed(SEED) train_set, val_set, test_set = random_split(dataset, [252, 84, 84], generator=generator) train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True, generator=generator) val_loader = DataLoader(val_set, batch_size=BATCH_SIZE) test_loader = DataLoader(test_set, batch_size=BATCH_SIZE)
sample_images, sample_labels, _sample_ids = next(iter(train_loader)) shape_trace = "\n".join( [ "# Shape Trace", "", f"- One image batch: `{tuple(sample_images.shape)}` means batch, channel, height, width.", f"- One label batch: `{tuple(sample_labels.shape)}` means one class id per image.", f"- Model output should be `(batch, {len(CLASSES)})`, one logit per class.", ] ) + "\n"
configs = [ {"name": "Flatten baseline", "model": FlattenBaseline(), "epochs": 4, "lr": 0.01}, {"name": "Tiny CNN", "model": TinyCNN(), "epochs": 10, "lr": 0.006}, ] all_history = [] comparison_rows = [] trained_models = {} loss_fn = nn.CrossEntropyLoss()
for config in configs: history, best_val_acc = train_model( config["name"], config["model"], train_loader, val_loader, epochs=config["epochs"], lr=config["lr"], ) test_loss, test_acc = evaluate(config["model"], test_loader, loss_fn) all_history.extend(history) comparison_rows.append( { "model": config["name"], "epochs": config["epochs"], "best_val_acc": round(best_val_acc, 4), "test_loss": round(test_loss, 4), "test_accuracy": round(test_acc, 4), } ) trained_models[config["name"]] = config["model"]
comparison_rows = sorted(comparison_rows, key=lambda row: (row["test_accuracy"], row["best_val_acc"]), reverse=True) best_name = comparison_rows[0]["model"] best_model = trained_models[best_name] predictions = predict_samples(best_model, test_loader) errors = [row for row in predictions if not row["correct"]] review_rows = errors[:10] if errors else sorted(predictions, key=lambda row: row["confidence"])[:10] for row in review_rows: row["review_reason"] = "wrong prediction" if not row["correct"] else "lowest-confidence correct prediction"
summary = { "best_model": best_name, "test_accuracy": comparison_rows[0]["test_accuracy"], "classes": CLASSES, "train_samples": len(train_set), "val_samples": len(val_set), "test_samples": len(test_set), }
write_csv(OUTPUT_DIR / "training_log.csv", all_history) write_csv(OUTPUT_DIR / "model_comparison.csv", comparison_rows) write_matrix_csv(OUTPUT_DIR / "confusion_matrix.csv", confusion_matrix_rows(predictions)) write_csv(OUTPUT_DIR / "error_samples.csv", review_rows) (OUTPUT_DIR / "metrics_summary.json").write_text(json.dumps(summary, indent=2), encoding="utf-8") torch.save({"model_name": best_name, "model_state": best_model.state_dict(), "classes": CLASSES}, CHECKPOINT_DIR / "best_model.pt") plot_history(all_history) write_text_reports(summary, shape_trace)
print("STEP 1: data prepared") print(f"train_samples: {len(train_set)}") print(f"val_samples: {len(val_set)}") print(f"test_samples: {len(test_set)}") print(f"classes: {len(CLASSES)}") print("STEP 2: model comparison") print(f"baseline_val_acc: {next(row['best_val_acc'] for row in comparison_rows if row['model'] == 'Flatten baseline'):.3f}") print(f"cnn_val_acc: {next(row['best_val_acc'] for row in comparison_rows if row['model'] == 'Tiny CNN'):.3f}") print(f"best_model: {best_name}") print(f"test_accuracy: {comparison_rows[0]['test_accuracy']:.3f}") print("STEP 3: evidence files") print(RUN_DIR / "README.md") print(OUTPUT_DIR / "training_log.csv") print(OUTPUT_DIR / "model_comparison.csv") print(CURVE_DIR / "loss_curve.png") print(REPORT_DIR / "shape_trace.md")
if __name__ == "__main__": main()Run It
Section titled “Run It”python dl_workshop.pyExpected output:
STEP 1: data preparedtrain_samples: 252val_samples: 84test_samples: 84classes: 3STEP 2: model comparisonbaseline_val_acc: 0.929cnn_val_acc: 1.000best_model: Tiny CNNtest_accuracy: 1.000STEP 3: evidence filesdeep_learning_workshop_run/README.mddeep_learning_workshop_run/outputs/training_log.csvdeep_learning_workshop_run/outputs/model_comparison.csvdeep_learning_workshop_run/curves/loss_curve.pngdeep_learning_workshop_run/reports/shape_trace.mdConfirm that the evidence files really exist:
find deep_learning_workshop_run -maxdepth 2 -type f | sortExpected output:
deep_learning_workshop_run/README.mddeep_learning_workshop_run/checkpoints/best_model.ptdeep_learning_workshop_run/curves/loss_curve.pngdeep_learning_workshop_run/outputs/confusion_matrix.csvdeep_learning_workshop_run/outputs/error_samples.csvdeep_learning_workshop_run/outputs/metrics_summary.jsondeep_learning_workshop_run/outputs/model_comparison.csvdeep_learning_workshop_run/outputs/training_log.csvdeep_learning_workshop_run/reports/debug_checklist.mddeep_learning_workshop_run/reports/shape_trace.mdRead the Output Step by Step
Section titled “Read the Output Step by Step”
Start with shape_trace.md
Section titled “Start with shape_trace.md”Run:
sed -n '1,20p' deep_learning_workshop_run/reports/shape_trace.mdExpected output:
# Shape Trace
- One image batch: `(32, 1, 16, 16)` means batch, channel, height, width.- One label batch: `(32,)` means one class id per image.- Model output should be `(batch, 3)`, one logit per class.Read it as:
32: batch size1: grayscale channel16: image height16: image width
If this shape does not match what Conv2d expects, training will fail before the model can learn anything.
Read training_log.csv
Section titled “Read training_log.csv”Run a tiny reader instead of trying to inspect the whole CSV by eye:
python - <<'PY'import csvfrom collections import defaultdictfrom pathlib import Path
rows = list(csv.DictReader((Path("deep_learning_workshop_run") / "outputs" / "training_log.csv").open()))by_model = defaultdict(list)for row in rows: by_model[row["model"]].append(row)
for model, model_rows in by_model.items(): first = model_rows[0] last = model_rows[-1] print( f"{model}: " f"first_train_loss={float(first['train_loss']):.4f}, " f"last_train_loss={float(last['train_loss']):.4f}, " f"last_val_acc={float(last['val_acc']):.4f}" )PYExpected output:
Flatten baseline: first_train_loss=0.8555, last_train_loss=0.1929, last_val_acc=0.9286Tiny CNN: first_train_loss=1.0961, last_train_loss=0.0711, last_val_acc=1.0000Look for three things:
- Does
train_lossgo down? - Does
val_lossalso go down? - Does
val_accimprove without a large train/validation gap?
These questions are more useful than asking only whether the final accuracy is high.
Compare baseline and CNN
Section titled “Compare baseline and CNN”Run:
python - <<'PY'import csvimport jsonfrom pathlib import Path
run = Path("deep_learning_workshop_run")summary = json.loads((run / "outputs" / "metrics_summary.json").read_text())print(f"best_model={summary['best_model']}")print(f"test_accuracy={summary['test_accuracy']:.3f}")
with (run / "outputs" / "model_comparison.csv").open() as file: for row in csv.DictReader(file): print( f"{row['model']}: " f"best_val_acc={float(row['best_val_acc']):.3f}, " f"test_accuracy={float(row['test_accuracy']):.3f}" )PYExpected output:
best_model=Tiny CNNtest_accuracy=1.000Tiny CNN: best_val_acc=1.000, test_accuracy=1.000Flatten baseline: best_val_acc=0.929, test_accuracy=0.917The Flatten baseline ignores the idea of local visual patterns. The Tiny CNN can learn small local kernels, so it is a better match for stripe-like image data. This is the practical meaning of “choose a model structure that matches the data structure.”
Review error_samples.csv
Section titled “Review error_samples.csv”First read the confusion matrix:
cat deep_learning_workshop_run/outputs/confusion_matrix.csvExpected output:
actual/predicted,vertical_stripe,horizontal_stripe,diagonal_stripevertical_stripe,25,0,0horizontal_stripe,0,28,0diagonal_stripe,0,0,31Then inspect the review sample file:
python - <<'PY'import csvfrom pathlib import Path
rows = list(csv.DictReader((Path("deep_learning_workshop_run") / "outputs" / "error_samples.csv").open()))print(f"review_rows={len(rows)}")first = rows[0]print( f"first_review={first['sample_id']} " f"predicted={first['predicted']} " f"confidence={float(first['confidence']):.4f} " f"reason={first['review_reason']}")PYExpected output:
review_rows=10first_review=diagonal_stripe_099 predicted=diagonal_stripe confidence=0.4211 reason=lowest-confidence correct predictionIf the model makes mistakes, this file stores wrong predictions. If the model gets all test samples correct, it stores the lowest-confidence correct predictions instead. Both are useful: real projects need review samples, not only a final score.
Look at the loss curve
Section titled “Look at the loss curve”Open deep_learning_workshop_run/curves/loss_curve.png.
Ask:
- Are training and validation moving in the same direction?
- Does one model converge faster?
- Does validation stop improving while training keeps improving?
This is the habit you will reuse in transfer learning, fine-tuning, and large model training.
Load the Checkpoint Once
Section titled “Load the Checkpoint Once”A checkpoint is useful only if it can be loaded. Run a quick smoke test:
python - <<'PY'from pathlib import Pathimport torch
checkpoint = torch.load(Path("deep_learning_workshop_run") / "checkpoints" / "best_model.pt", map_location="cpu")print(checkpoint["model_name"])print(", ".join(checkpoint["classes"]))PYExpected output:
Tiny CNNvertical_stripe, horizontal_stripe, diagonal_stripeThis does not rebuild the model yet. It simply proves the file contains the model name, saved parameters, and class list needed for a future inference script.
Common Errors and Debugging Loop
Section titled “Common Errors and Debugging Loop”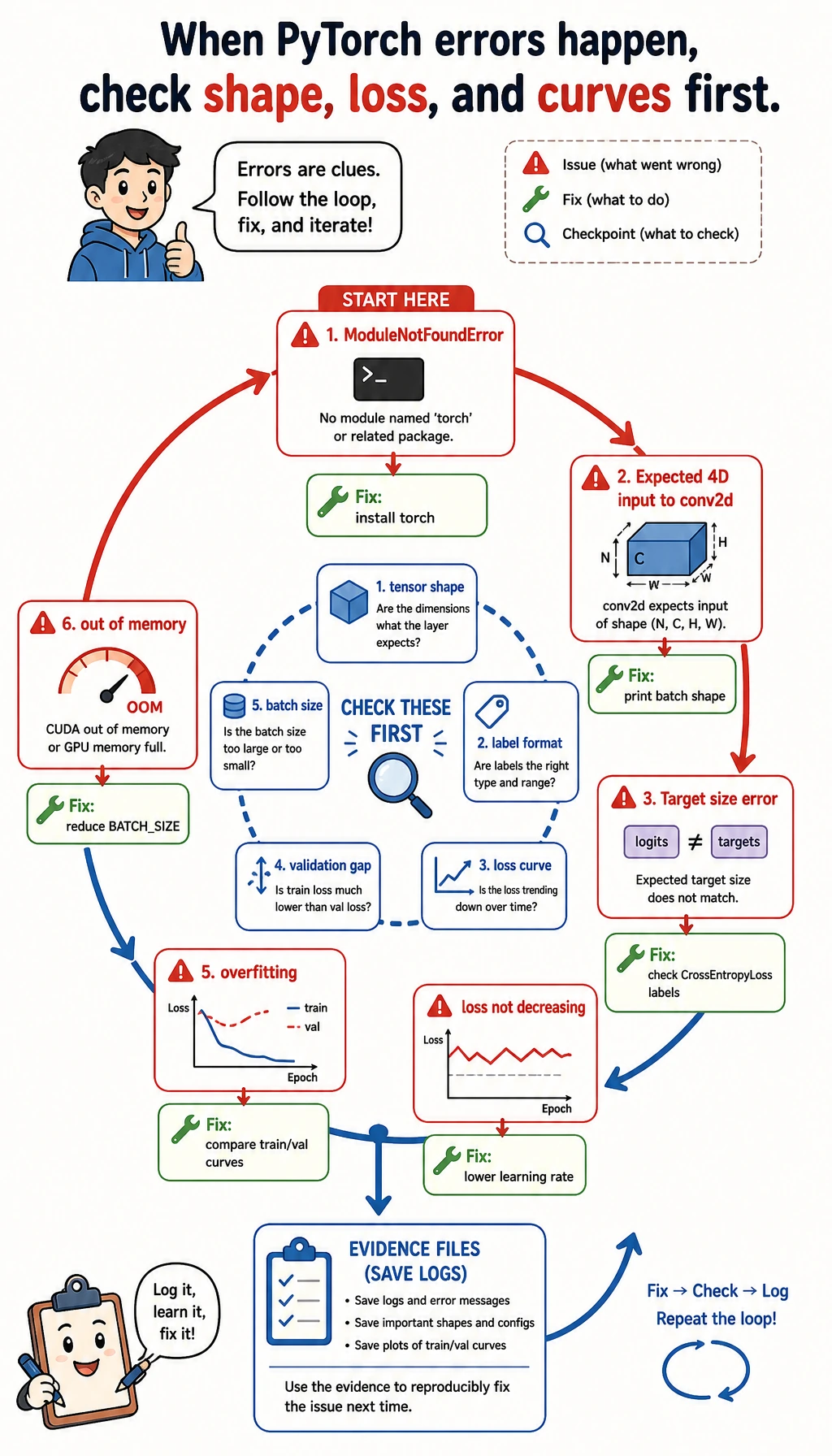
| Symptom | Likely cause | What to do |
|---|---|---|
ModuleNotFoundError: No module named 'torch' | PyTorch is not installed in the active environment | Run python -m pip install torch matplotlib |
Expected 4D input to conv2d | Image tensor is missing channel or batch dimension | Print the batch shape and make sure it is (batch, channel, height, width) |
Target size or class index error | Labels do not match CrossEntropyLoss expectations | Use integer class ids with shape (batch,) |
| Loss does not decrease | Learning rate is wrong, labels are wrong, or inputs are badly scaled | Try a smaller learning rate and overfit a tiny batch |
| Training improves but validation does not | Overfitting or bad split | Add regularization, more data, augmentation, or early stopping |
| CPU/GPU memory issue | Batch, image, or model is too large | Reduce BATCH_SIZE, image size, or model width first |
Turn This Into a Portfolio Project
Section titled “Turn This Into a Portfolio Project”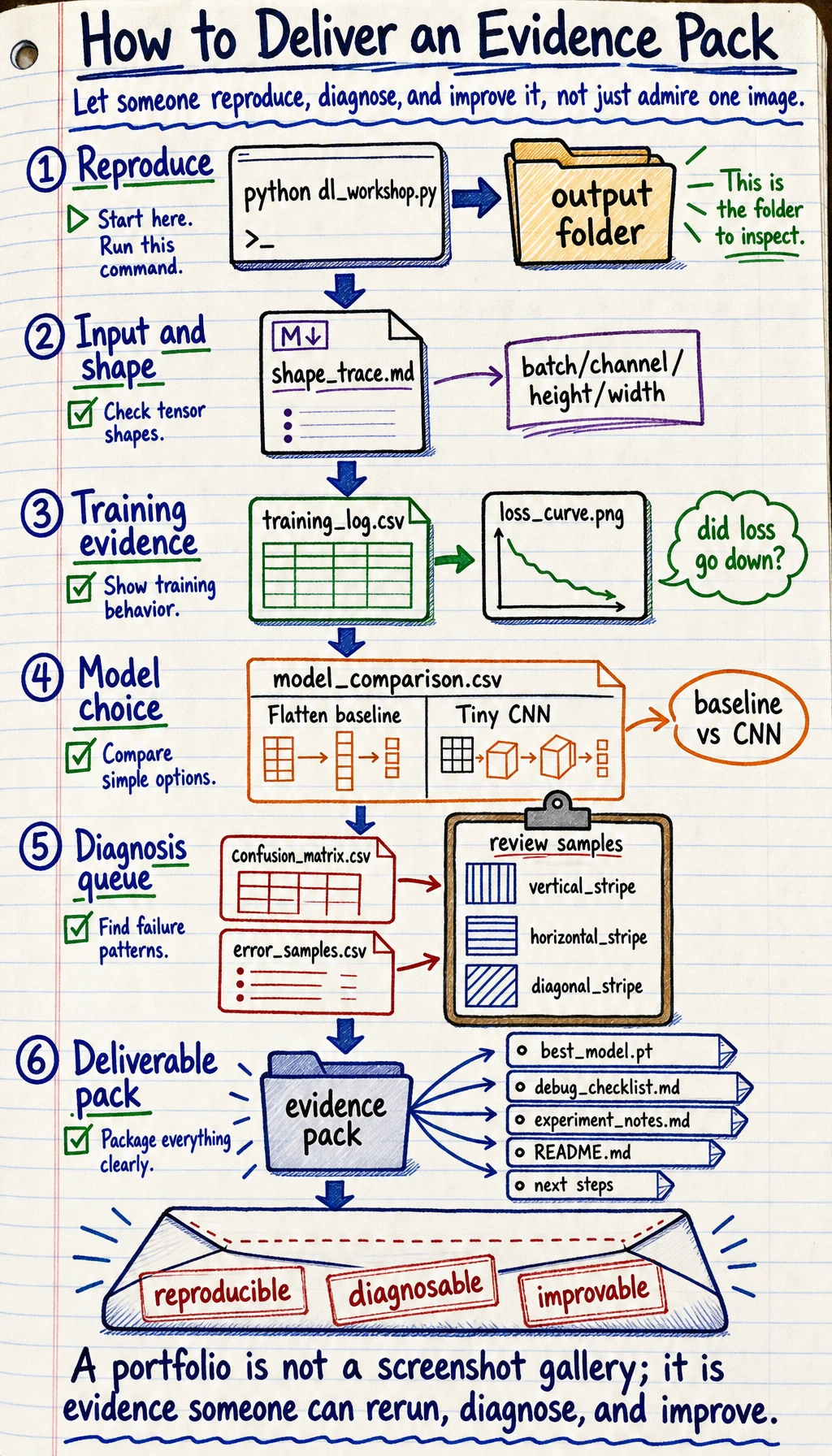

Upgrade the workshop in small steps:
- Replace the synthetic stripe dataset with a small folder of real images.
- Add
config.jsonforbatch_size,learning_rate,epochs, and model name. - Add data augmentation after you have a stable baseline.
- Save a grid of review samples instead of only a CSV.
- Add early stopping and explain why the chosen epoch is best.
- Write a README paragraph explaining the top failure patterns.
Practice a One-Variable Rerun
Section titled “Practice a One-Variable Rerun”Do one small experiment before you move on:
- Keep a copy of the first run’s
training_log.csvandloss_curve.png. - Change only one constant in
dl_workshop.py, such asBATCH_SIZE, the CNN learning rate, or the CNN epoch count. - Run
python dl_workshop.pyagain. - Compare the new
training_log.csv,model_comparison.csv,loss_curve.png, anderror_samples.csv.
Add a short experiment note:
python - <<'PY'from pathlib import Path
run = Path("deep_learning_workshop_run")note = run / "reports" / "experiment_notes.md"note.write_text( "\n".join( [ "# Experiment Notes", "", "- Run 1: default constants, Tiny CNN selected by validation accuracy.", "- Next change: adjust only `BATCH_SIZE` or only `lr`, then compare `training_log.csv` and `loss_curve.png`.", ] ) + "\n", encoding="utf-8",)print(note)PYExpected output:
deep_learning_workshop_run/reports/experiment_notes.mdThe important habit is not getting a better score every time. It is changing one variable, rerunning cleanly, and explaining the result with evidence.
Operation guide and checkpoints
A strong rerun note should identify exactly one changed variable, then compare artifacts rather than memory:
- If
BATCH_SIZEchanged, compare training speed, curve smoothness, and validation accuracy. Larger batches may be smoother but not always better. - If the CNN learning rate changed, compare whether the loss curve descends, oscillates, or stalls. A lower loss in the first epoch is not enough evidence.
- If epoch count changed, check whether validation loss improved or began to overfit. More epochs are useful only when validation evidence supports them.
- The final note should name the next action, such as keeping the default, testing one nearby value, or reverting because validation got worse.
Portfolio Checklist
Section titled “Portfolio Checklist”Before calling a Chapter 6 project done, make sure you have:
- A run command that works from a clean folder
- A tensor shape trace
- A baseline model
- An improved model
- Training and validation logs
- A loss curve
- A model comparison table
- A checkpoint
- Review samples or failed samples
- A README with limitations and next steps
Summary
Section titled “Summary”This workshop turns Chapter 6 into one runnable loop: tensors, dataset, dataloader, model, loss, optimizer, training, validation, checkpoint, curves, review samples, and README evidence. If you can rerun it and explain each output file, you are practicing deep learning as an engineering workflow, not only copying PyTorch code.