E.F AI Product Design Thinking
AI product design starts with the user problem, not the model capability. A feature is worth building only when value, cost, risk, and user experience can be explained.
See the Decision Loop First
Section titled “See the Decision Loop First”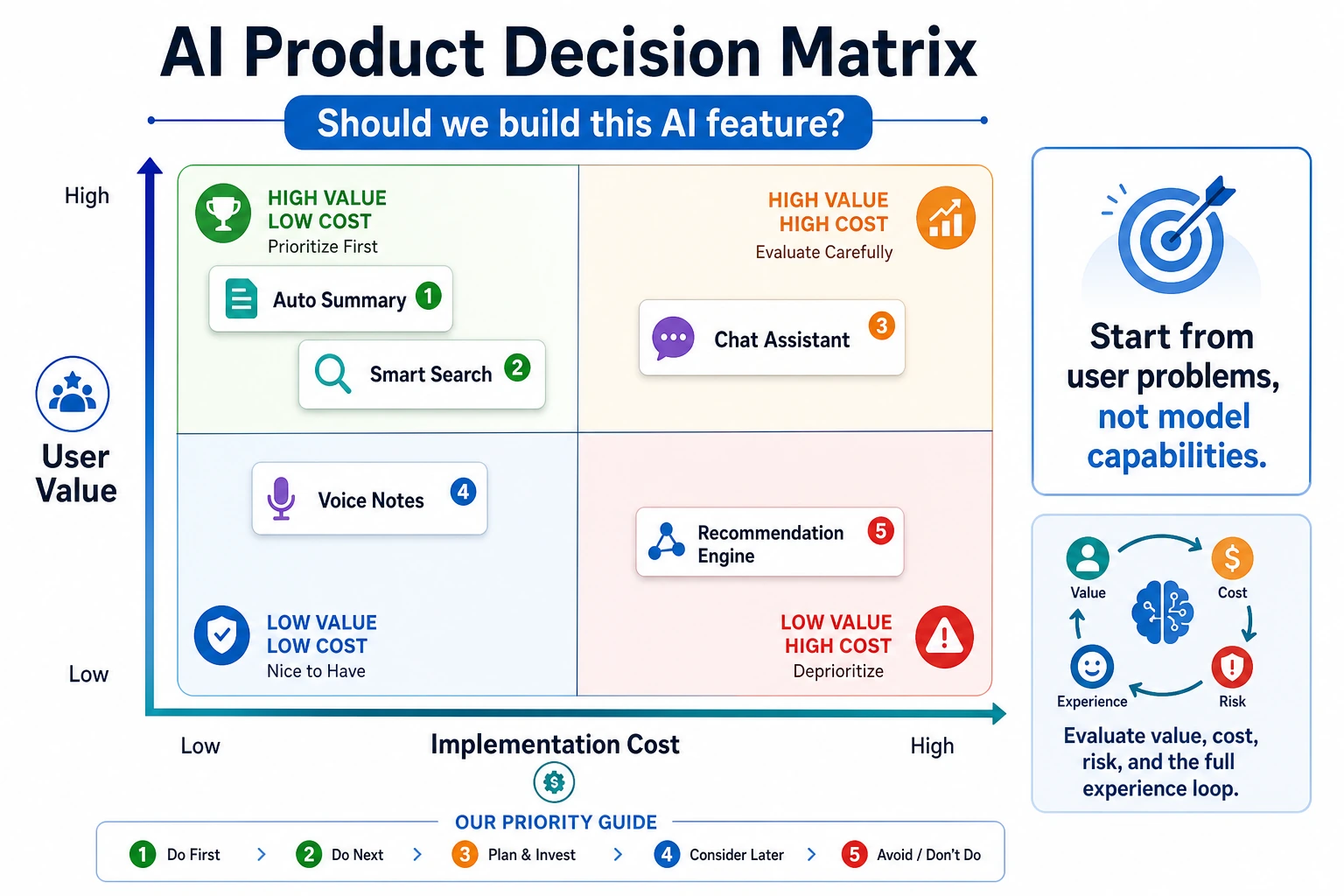
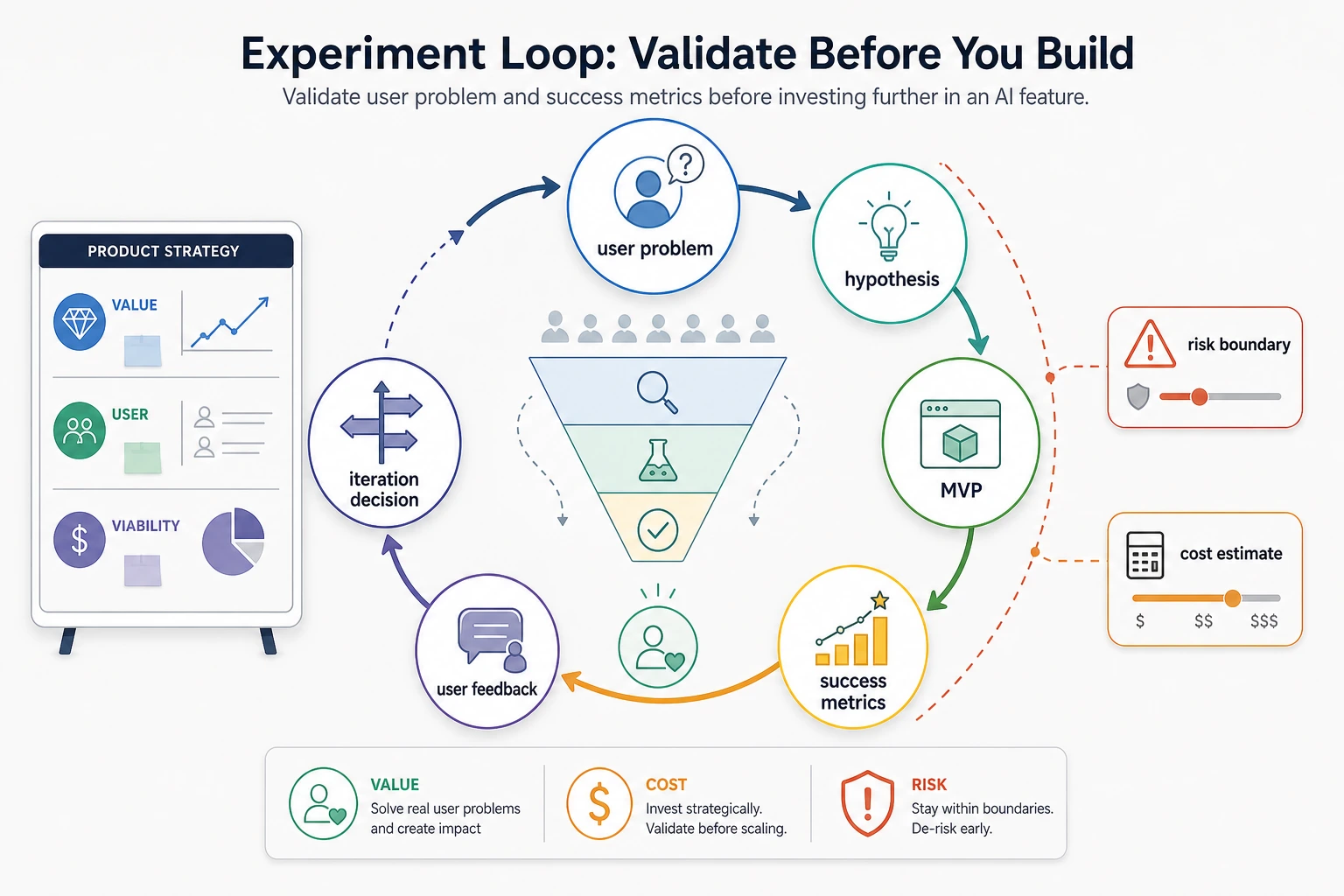
The first product habit is to make trade-offs explicit before implementation starts.
Read the first image as a launch gate: high value is not enough if risk, cost, or user trust cannot be managed. Read the second image as the operating rhythm after launch: hypothesis, prototype, metric, user feedback, and decision should keep looping.
Run a Tiny Prioritization Score
Section titled “Run a Tiny Prioritization Score”ideas = [ {"name": "AI Tutor", "value": 9, "cost": 6, "risk": 4, "ux": 8}, {"name": "AI Customer Service", "value": 8, "cost": 5, "risk": 5, "ux": 7}, {"name": "AI Code Review", "value": 7, "cost": 4, "risk": 6, "ux": 6}, {"name": "AI Medical Diagnosis", "value": 9, "cost": 8, "risk": 9, "ux": 5},]
def score(item): return round( item["value"] * 0.45 + (10 - item["cost"]) * 0.2 + (10 - item["risk"]) * 0.2 + item["ux"] * 0.15, 2, )
def decision(item): if item["risk"] >= 8: return "do_not_launch" return "pilot" if item["score"] >= 6 else "wait"
ranked = sorted(({**item, "score": score(item)} for item in ideas), key=lambda item: item["score"], reverse=True)
for item in ranked: print(item["name"], "score=", item["score"], "decision=", decision(item))Expected output:
AI Tutor score= 7.25 decision= pilotAI Customer Service score= 6.65 decision= pilotAI Code Review score= 6.05 decision= pilotAI Medical Diagnosis score= 5.4 decision= do_not_launchThe numbers are not final truth. They force you to say what you are optimizing for and where launch should be blocked.
Turn the Score into a Decision Note
Section titled “Turn the Score into a Decision Note”After the script prints a ranking, do not stop at the top score. Write one small decision note:
Example decision note:
- Feature: AI Tutor
- Decision: pilot
- Success metric: exercise completion rate improves by 15%.
- Main risk: it gives confident but wrong explanations.
- Launch blocker: no review path for high-risk advice.
- Next test: run with 10 real learner questions and record failures.
This note is the bridge between product thinking and engineering work. Engineers can build from it because it names a metric, a risk, a blocker, and the next experiment.
The launch blocker matters more than the numeric score. A medical diagnosis assistant can score high on user value, but still be blocked if the team cannot provide clinical review, audit logs, escalation, and clear responsibility boundaries.
Design the Smallest Useful Test
Section titled “Design the Smallest Useful Test”Before building a full feature, define a small test that can change your decision:
| Idea | Smallest useful test |
|---|---|
| AI Tutor | Try 10 real learner questions and mark correctness, tone, and next-step usefulness. |
| AI Customer Service | Run 30 historical tickets and measure containment rate plus unsafe answer rate. |
| AI Code Review | Compare AI comments with human review on 5 pull requests and count actionable findings. |
The test should have a decision rule before it starts. For example: pilot only if at least 8 of 10 tutor answers are correct, no high-risk answer is unreviewed, and learners say the next step is clear.
Product Checklist
Section titled “Product Checklist”| Question | Good Answer |
|---|---|
| Who is stuck? | A specific user group and task |
| What improves? | Completion rate, time saved, quality, or cost |
| What can go wrong? | Risk boundary and human fallback |
| What proves progress? | A metric or user test result |
| What stops launch? | A concrete blocker, not a vague concern |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Product Question
- user problem, workflow, value metric, and risk boundary
- Experiment
- hypothesis, smallest test, metric, and decision rule
- Artifact
- feature spec, prototype note, user story, or evaluation result
- Failure Check
- building demos without measuring value or ignoring user workflow
- Expected Output
- AI product decision note that can guide implementation
Pass Check
Section titled “Pass Check”You pass this elective when you can score one AI feature idea, explain the trade-off, define a success metric, and name one condition where the feature should not launch.
Check reasoning and explanation
A strong answer does not treat the score as magic. It explains the user problem, the value metric, the major cost or risk, and the launch blocker. For example, a tutor feature may be worth piloting if it improves exercise completion, but it should not launch if it gives unsafe or unreviewed advice in high-stakes contexts.
The useful output is a decision note: pilot, wait, or do not launch, plus the evidence that would change that decision.