6.4.1 RNN Roadmap: Process Sequences Step by Step
RNNs are built for ordered data: text, time series, clicks, sensor readings, and any input where earlier steps affect later steps.
Look at the Sequence Flow First
Section titled “Look at the Sequence Flow First”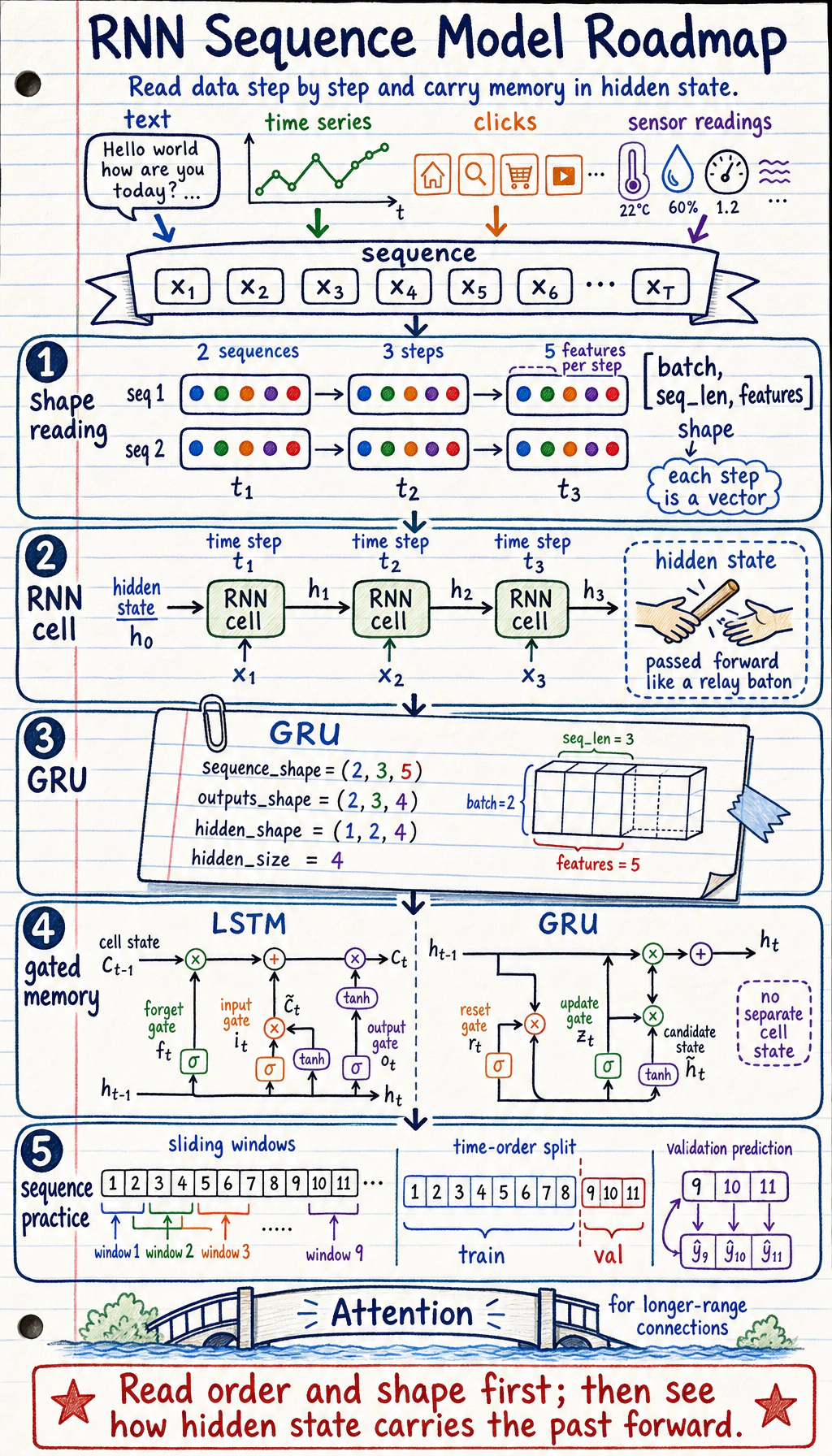
| Concept | First meaning |
|---|---|
| sequence length | how many time steps |
| input size | features per step |
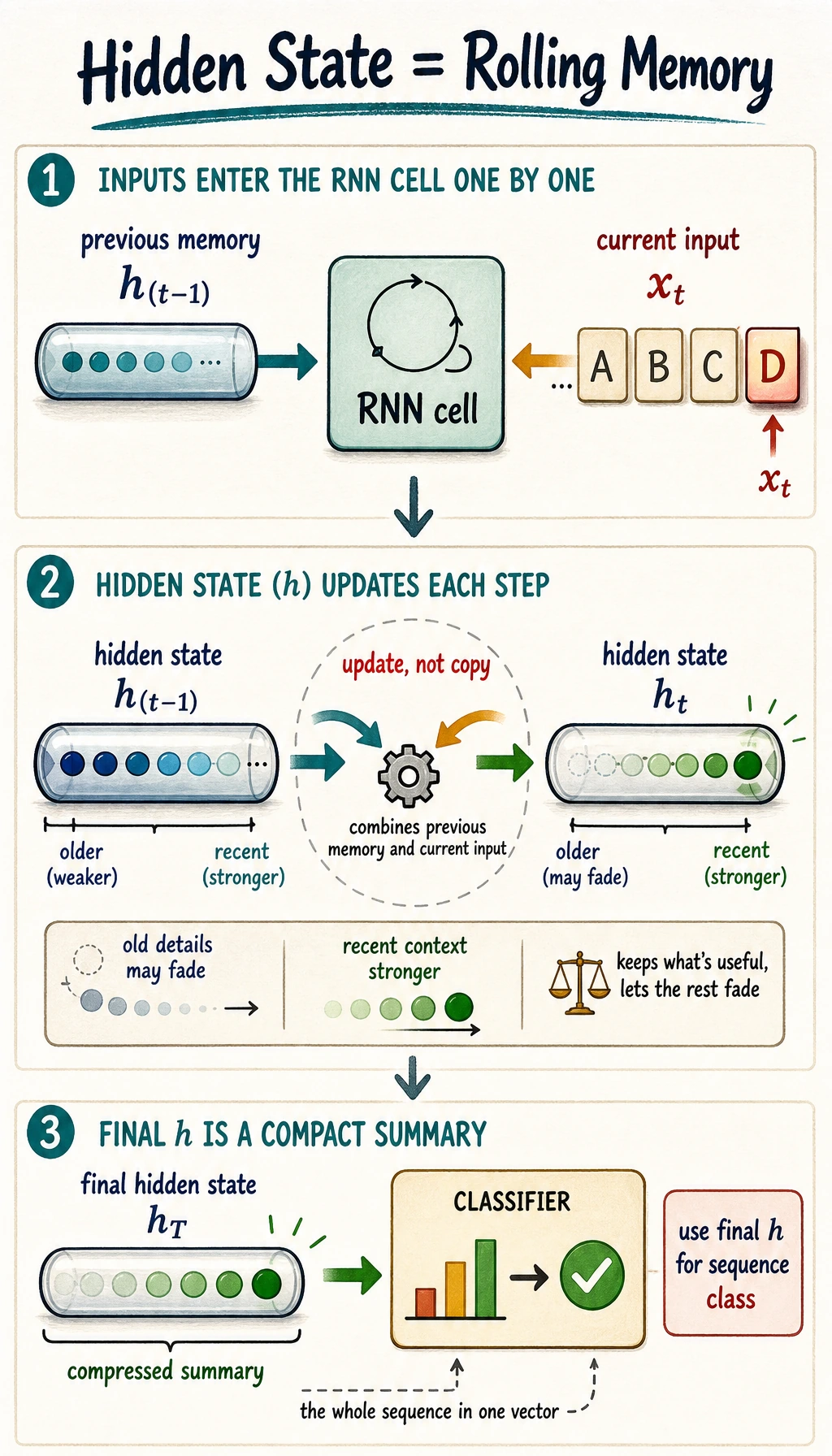
| hidden state | rolling memory |
| LSTM / GRU | gated memory control |
| batch first | shape style [batch, seq_len, features] |
Run One GRU Shape Check
Section titled “Run One GRU Shape Check”Create rnn_first_loop.py and run it after installing torch.
import torch
sequence = torch.randn(2, 3, 5)gru = torch.nn.GRU(input_size=5, hidden_size=4, batch_first=True)outputs, hidden = gru(sequence)
print("sequence_shape:", tuple(sequence.shape))print("outputs_shape:", tuple(outputs.shape))print("hidden_shape:", tuple(hidden.shape))Expected output:
sequence_shape: (2, 3, 5)outputs_shape: (2, 3, 4)hidden_shape: (1, 2, 4)Read this as two sequences, three steps each, five features per step. The GRU returns a hidden representation of size 4.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to practice |
|---|---|---|
| 1 | 6.4.2 RNN Basics | sequence input, hidden state, shape |
| 2 | 6.4.3 LSTM and GRU | gates, long dependency, memory control |
| 3 | 6.4.4 Sequence Practice | sliding windows, train/eval loop |
Evidence to Keep
Section titled “Evidence to Keep”Keep one sequence shape note:
- Input
- [batch, seq_len, features]
- Outputs
- one hidden representation per step
- Hidden
- compressed rolling memory
- Gate Reason
- LSTM/GRU help preserve or discard information
- Baseline
- compare sequence model against a simple naive rule
Pass Check
Section titled “Pass Check”You pass this roadmap when you can read [batch, seq_len, features], explain hidden state as rolling memory, and know why LSTM/GRU were introduced for longer dependencies.
Check reasoning and explanation
- A passing answer connects tensors, model layers, loss,
backward(), and optimizer updates into one training loop. - The evidence should include a runnable mini experiment, tensor-shape checks, and a loss or validation curve you can explain.
- A good self-check names one failure mode such as shape mismatch, no loss decrease, overfitting, data leakage, or using Attention/Transformer words without explaining the data flow.