7.3.4 Mainstream Variants of Large Model Architectures
Learning Objectives
Section titled “Learning Objectives”- Understand the core differences among Encoder-only, Decoder-only, and Encoder-Decoder
- Understand the relationship between architecture choice, training objectives, and task types
- Use a runnable example to clearly see the information flow behind different masks
- Build an initial judgment of “which type of structure is better suited to this task”
Why do so many branches grow from the same Transformer?
Section titled “Why do so many branches grow from the same Transformer?”Because tasks differ, and so do information-flow constraints
Section titled “Because tasks differ, and so do information-flow constraints”Different NLP tasks have different essential needs:
- Text classification cares more about “understanding the whole sentence”
- Open-ended generation cares more about “continuing to write based only on the past”
- Translation and summarization care more about “encoding the input first, then generating the output”
So even if the underlying building blocks are all Transformer blocks, they will still grow into different structures.
A simple analogy
Section titled “A simple analogy”You can think of the three classic architectures as three ways of reading:
- Encoder-only: read the whole article once, then make a judgment
- Decoder-only: write while looking only at what came before, not at the future
- Encoder-Decoder: first read the original text carefully, then write a summary or translation based on it
Once this analogy makes sense, the differences that follow become much easier to understand.
What does each of the three classic structures do?
Section titled “What does each of the three classic structures do?”Encoder-only: good for understanding, not ideal for open-ended continuation
Section titled “Encoder-only: good for understanding, not ideal for open-ended continuation”A typical representative of Encoder-only is:
- BERT
Its characteristics are:
- Each position can see context on both the left and the right
- It is easier to form a complete semantic representation
- It is well suited for understanding tasks such as classification, matching, and extraction
But it is not naturally suited for free generation, because during training it does not strictly follow the constraint of “only seeing the past.”
Decoder-only: the most direct route for generation
Section titled “Decoder-only: the most direct route for generation”Typical representatives of Decoder-only are:
- GPT
- LLaMA
- Qwen
Its key constraint is:
- The current token can only see the tokens before it
This matches generation tasks perfectly, because when we generate, we also write forward one step at a time.
Its advantages are:
- Unified training objective
- Natural generation process
- Very suitable for large-scale autoregressive modeling
Encoder-Decoder: separate the responsibilities of input and output
Section titled “Encoder-Decoder: separate the responsibilities of input and output”Typical representatives of Encoder-Decoder are:
- T5
- BART
The idea is:
- The Encoder first understands the input
- The Decoder then generates the output based on the input representation
This structure is especially suitable for:
- Translation
- Summarization
- Paraphrasing
- Question answering generation
Because these tasks are naturally:
- Given one piece of text
- Output another piece of text
MoE: not changing the information flow, but changing “who does the computation”
Section titled “MoE: not changing the information flow, but changing “who does the computation””As models become larger and larger, another important branch appears:
- Mixture of Experts
Its focus is not to change the basic rules of self-attention, but rather:
Let different tokens activate only part of the expert networks instead of passing through the entire large FFN every time.
The main goal of this is:
- Expand parameter scale while controlling the amount of computation actually activated in each forward pass
So MoE is more like a “scaling strategy variant.”

MoE terms beginners should not skip
Section titled “MoE terms beginners should not skip”| Term | Plain meaning | Why it matters |
|---|---|---|
| Router | The module that decides which experts a token should use | It determines the computation path of each token |
| Top-k | Select only the highest-scoring k experts | It controls how many experts are active per token |
| Load balance | Prevent too many tokens from going to the same expert | Without it, some experts overload while others do almost nothing |
| Expert FFN | A feed-forward subnetwork inside the expert pool | MoE usually replaces or expands the dense FFN part |
| Active compute | The parameters actually used for one token | This is different from total parameter count |
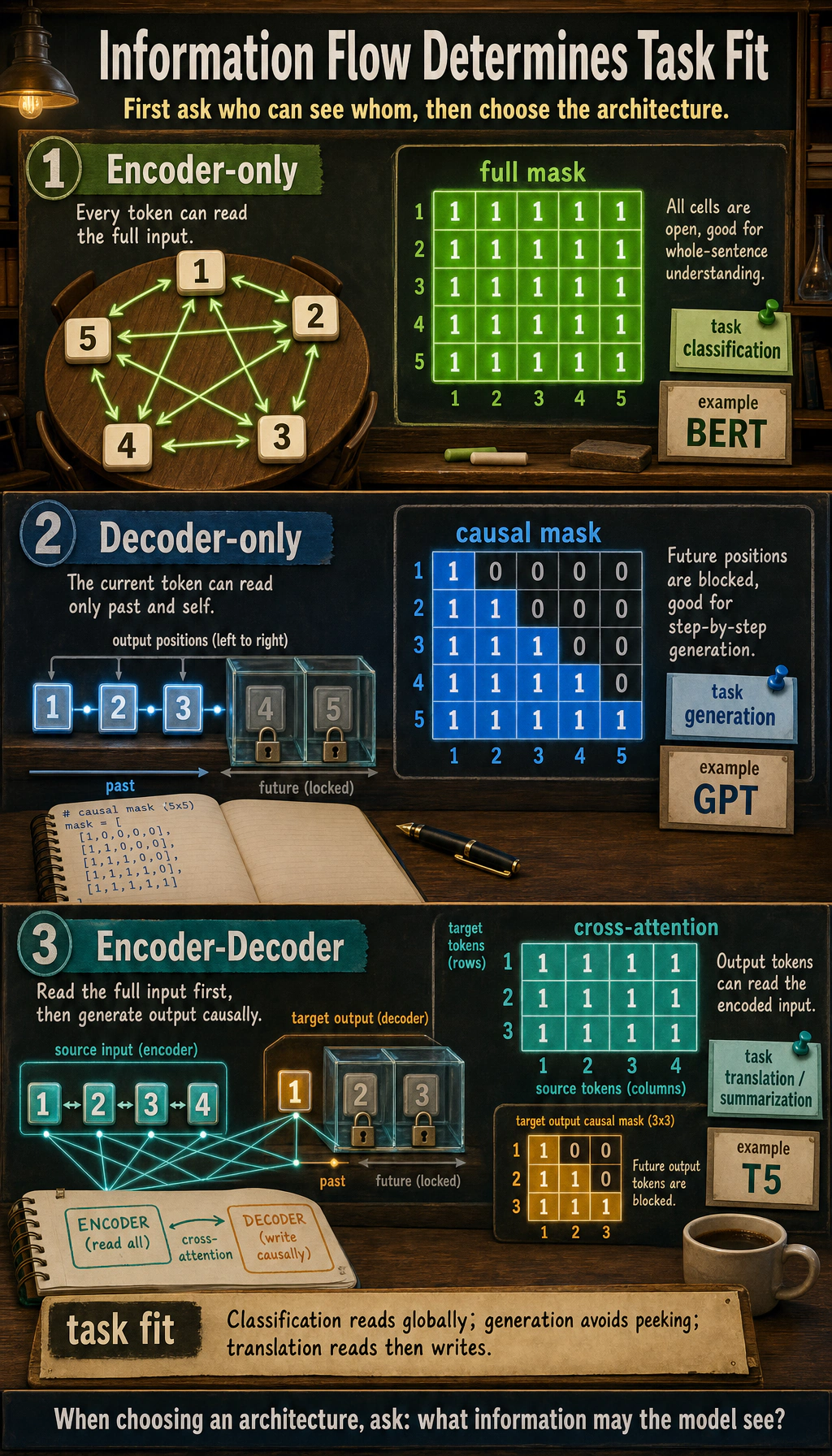
First, run a truly instructive example of structural differences
Section titled “First, run a truly instructive example of structural differences”The code below does not train a model, but it directly prints the most important difference among the three core architectures:
- Which positions can see which positions
This is closer to the structure itself than simply printing a dictionary.
def full_mask(length): return [[1 for _ in range(length)] for _ in range(length)]
def causal_mask(length): return [[1 if j <= i else 0 for j in range(length)] for i in range(length)]
def cross_attention_map(src_length, tgt_length): return [[1 for _ in range(src_length)] for _ in range(tgt_length)]
def pretty_print(title, matrix): print(title) for row in matrix: print(" ".join(str(x) for x in row)) print()
length = 5pretty_print("encoder-only self-attention", full_mask(length))pretty_print("decoder-only self-attention", causal_mask(length))pretty_print("encoder-decoder cross-attention", cross_attention_map(4, 3))Expected output:
encoder-only self-attention1 1 1 1 11 1 1 1 11 1 1 1 11 1 1 1 11 1 1 1 1
decoder-only self-attention1 0 0 0 01 1 0 0 01 1 1 0 01 1 1 1 01 1 1 1 1
encoder-decoder cross-attention1 1 1 11 1 1 11 1 1 1What is this code teaching?
Section titled “What is this code teaching?”It teaches three most fundamental things:
- Encoder-only looks both ways
- Decoder-only looks causally
- The decoder in Encoder-Decoder can also look at the input sequence
In other words, most architectural differences can ultimately be traced back to:
- Different information-flow constraints
Why is the mask so important?
Section titled “Why is the mask so important?”Because the mask determines what the model is allowed to know during training.
If the decoder does not have a causal mask, the model will peek at future tokens during training, but at generation time it cannot see the future. That creates a mismatch between training and inference.
Why does this determine task suitability?
Section titled “Why does this determine task suitability?”Because tasks themselves correspond to different information flows:
- Classification: allowed to see the full input
- Generation: cannot see the future
- Translation: the output can see the full input, but cannot see future output tokens
Whether a structure is suitable is, in essence, whether its information-flow constraints match the task.
Connect the three routes to typical tasks
Section titled “Connect the three routes to typical tasks”Why are text understanding tasks often based on Encoder-only?
Section titled “Why are text understanding tasks often based on Encoder-only?”Because these tasks focus more on:
- The overall meaning of the sentence
- Bidirectional relationships between tokens
- Comprehensive understanding of context around each position
For example:
- Sentiment classification
- Semantic matching
- Named entity recognition
These tasks are more like “read the whole passage first, then make a judgment.”
Why do most mainstream large models now mainly follow Decoder-only?
Section titled “Why do most mainstream large models now mainly follow Decoder-only?”Because when the goal becomes:
- General chat
- Open-ended generation
- Code completion
- Long-text continuation
the decoder-only structure is the most convenient.
And with that:
- The pretraining objective is unified
- The inference path is clear
- It performs very well at very large scale
So it became the mainstream route in the era of large language models.
Why hasn’t Encoder-Decoder disappeared?
Section titled “Why hasn’t Encoder-Decoder disappeared?”Because many tasks are still very suitable for it:
- Translation
- Summarization
- Text rewriting
- Generation tasks with a clear separation between input and output
If a task is naturally “given an input, generate another output,” Encoder-Decoder still has a strong advantage.
What situations is MoE suitable for?
Section titled “What situations is MoE suitable for?”When a team is pursuing:
- Larger parameter scale
- But does not want to compute all parameters in every forward pass
then MoE starts to become attractive.
But it also brings new engineering problems:
- Is routing stable?
- Is load balanced?
- Is distributed training more complex?
Structural differences are not just about “which is stronger,” but “which is more suitable”
Section titled “Structural differences are not just about “which is stronger,” but “which is more suitable””There is no universally strongest structure forever
Section titled “There is no universally strongest structure forever”Many beginners ask:
- Which is stronger, BERT, GPT, or T5?
A more reasonable question is:
- What is the task?
- What is the training objective?
- What is the inference method?
An architecture is not a ranking list, but a task-matching problem.
Many “performance gaps” actually come from training scale and data, not just architecture
Section titled “Many “performance gaps” actually come from training scale and data, not just architecture”For example, GPT models are strong not only because they are decoder-only, but also because:
- They have more data
- They have more parameters
- The engineering is more mature
So do not turn the architecture itself into the only decisive factor.
Architecture and objective function should be viewed together
Section titled “Architecture and objective function should be viewed together”You will usually see such pairings:
- Encoder-only + masked language modeling
- Decoder-only + causal language modeling
- Encoder-Decoder + seq2seq / denoising
In other words, architecture and training objective are usually designed as a package, not assembled arbitrarily.
Common misconceptions
Section titled “Common misconceptions”Misconception 1: BERT is just an “old model,” so it is not worth learning
Section titled “Misconception 1: BERT is just an “old model,” so it is not worth learning”That is not true. It is still an important baseline for understanding tasks and representation learning.
Misconception 2: Decoder-only can do everything, so it must be the optimal solution
Section titled “Misconception 2: Decoder-only can do everything, so it must be the optimal solution”It is indeed very general, but for some tasks with clearly separated input and output, Encoder-Decoder may still be more natural.
Misconception 3: MoE is just a “bigger normal model”
Section titled “Misconception 3: MoE is just a “bigger normal model””Not exactly. The core change in MoE is:
- Parameter scale and actual activated computation are separated
This changes both training and deployment complexity.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Encoder Only
- bidirectional understanding tasks
- Decoder Only
- causal generation and chat models
- Encoder Decoder
- read one sequence and generate another
- Choice Rule
- architecture follows task and serving pattern
- Misread To Avoid
- variant names are not simple quality rankings
Summary
Section titled “Summary”The most important thing in this section is not memorizing names, but building a map of the structures:
Encoder-only is more like “read everything first, then understand,” Decoder-only is more like “generate in time order,” Encoder-Decoder is more like “read first, then write,” and MoE changes the computation path when scaling up.
As long as you can connect architecture, task, and information flow, when you see a new model name later, you will no longer be left with only the impression that “it is very popular.”
Exercises
Section titled “Exercises”- Explain in your own words: Why is the causal mask the core constraint of Decoder-only?
- Think of a translation or summarization task, and explain why it is naturally suitable for Encoder-Decoder.
- If you were doing text classification, would you prioritize Encoder-only or Decoder-only? Why?
- Suppose you want to continue scaling up to a very large model, but your computation budget per step is limited. Why does MoE become attractive?
Solution approach and explanation
- The causal mask forces each token to predict from the past rather than looking ahead. That constraint is what turns a Transformer block into an autoregressive generator.
- Translation and summarization naturally have an input sequence and an output sequence. The encoder can read the whole source, while the decoder generates the target step by step while attending back to the encoded source.
- For classic classification, Encoder-only is often the simpler first choice because it can read the whole input bidirectionally and produce a compact representation. Decoder-only can also classify, but it is usually chosen when generation or a unified LLM interface matters.
- MoE activates only part of the model for each token. It can increase total parameter capacity without making every training or inference step pay for every expert.