9.9.6 Production Best Practices
Learning Objectives
Section titled “Learning Objectives”- Understand the most important release and operations principles in production
- Learn how to design a minimal pre-launch checklist
- Understand the role of canary rollout, rollback, alerting, and human takeover
- Build a production readiness mindset through a runnable example
What Do You Really Need to Confirm Before Launch?
Section titled “What Do You Really Need to Confirm Before Launch?”Functional correctness is only the most basic layer
Section titled “Functional correctness is only the most basic layer”Production readiness should also include at least:
- Is it observable?
- Can it be rolled back?
- Are rate limiting and timeouts in place?
- Is there a safety boundary?
- Is there an evaluation baseline?
A very practical way to judge
Section titled “A very practical way to judge”If a service goes wrong after release, do you already know:
- Where to check logs
- Which metrics to inspect
- How to switch back to the old version
- Who will take over manually
If you cannot answer these questions, the system is usually not ready for production yet.
The Six Most Important Principles for Production
Section titled “The Six Most Important Principles for Production”Start with canary rollout, not full release
Section titled “Start with canary rollout, not full release”Agent systems are usually more uncertain than ordinary CRUD systems. Canary rollout lets you observe:
- Changes in accuracy
- Changes in latency
- Changes in cost
Always keep a rollback path
Section titled “Always keep a rollback path”Without rollback, there is no truly safe release.
Critical capabilities must have a human takeover plan
Section titled “Critical capabilities must have a human takeover plan”Especially for:
- High-risk operations
- Write operations
- Tasks with external side effects
Define alerting before talking about launch
Section titled “Define alerting before talking about launch”At minimum, make it clear:
- Which metric abnormalities should trigger alerts
- Who receives the alerts
- What to check first after an alert is triggered
Every critical action should be auditable
Section titled “Every critical action should be auditable”Especially:
- Tool calls
- Permission decisions
- Important state changes
Release must be tied to evaluation
Section titled “Release must be tied to evaluation”Launching is not “trusting the model,” but “letting evaluation and online signals speak together.”
Run a Minimal Readiness Checker First
Section titled “Run a Minimal Readiness Checker First”The example below simulates a pre-launch check. It does not deploy the service directly, but instead answers:
- Does this system currently meet the most basic production requirements?
deployment_config = { "has_metrics": True, "has_structured_logs": True, "has_timeout": True, "has_retry_policy": True, "has_rate_limit": False, "has_eval_suite": True, "has_canary_rollout": True, "has_rollback_plan": True, "has_human_override": False, "has_audit_log": True,}
def readiness_check(config): required = [ "has_metrics", "has_structured_logs", "has_timeout", "has_retry_policy", "has_eval_suite", "has_canary_rollout", "has_rollback_plan", "has_audit_log", ]
missing_required = [key for key in required if not config.get(key, False)] warnings = []
if not config.get("has_rate_limit", False): warnings.append("missing_rate_limit") if not config.get("has_human_override", False): warnings.append("missing_human_override")
ready = len(missing_required) == 0 return { "ready": ready, "missing_required": missing_required, "warnings": warnings, }
print(readiness_check(deployment_config))Expected output:
{'ready': True, 'missing_required': [], 'warnings': ['missing_rate_limit', 'missing_human_override']}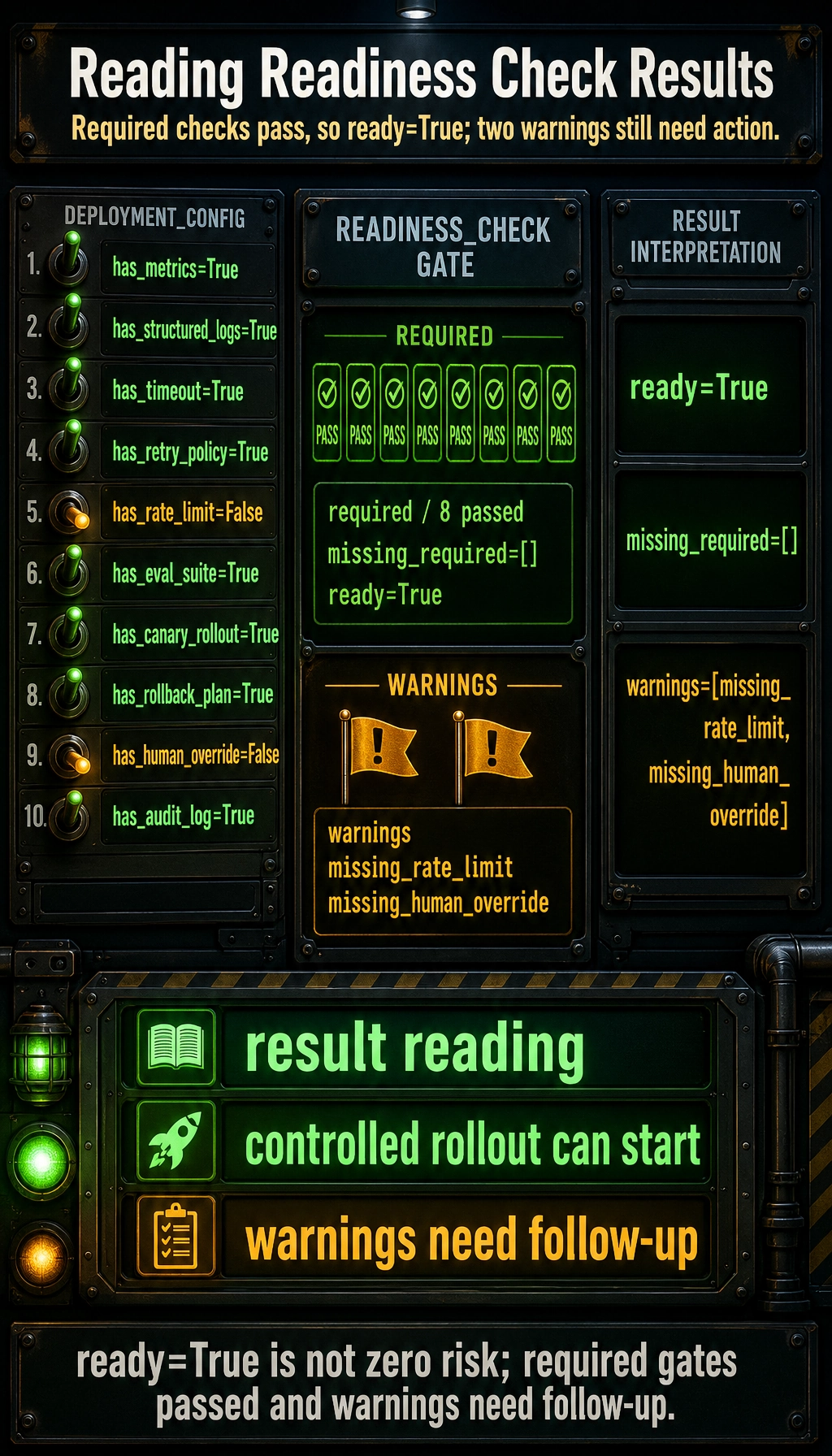
What is the most important takeaway from this example?
Section titled “What is the most important takeaway from this example?”It reminds you that:
- Production readiness is not a feeling
- It is a set of checkable conditions

Why is it important to explicitly list missing items?
Section titled “Why is it important to explicitly list missing items?”Because it shifts team discussion from:
- “It seems basically ready”
to:
- “We are currently missing rate limit and human override”
That makes the launch decision much clearer.
Why Is Canary Rollout Especially Important for Agents?
Section titled “Why Is Canary Rollout Especially Important for Agents?”Because Agent issues are often probabilistic
Section titled “Because Agent issues are often probabilistic”Some issues do not reproduce reliably in local testing, but only show up under real traffic, for example:
- A certain type of complex input triggers the wrong path
- A tool behaves unstably under high concurrency
- Some prompts go out of control on edge cases
The main benefits of canary rollout
Section titled “The main benefits of canary rollout”- Validate with a small amount of traffic first
- Keep the old system as a fallback
- Collect metrics in a real environment
A very simple traffic routing example
Section titled “A very simple traffic routing example”def route_request(request_id, canary_ratio=0.2): bucket = sum(ord(c) for c in request_id) % 100 return "new_agent" if bucket < canary_ratio * 100 else "stable_agent"
for request_id in ["req-001", "req-002", "req-003", "req-004"]: print(request_id, "->", route_request(request_id))Expected output:
req-001 -> new_agentreq-002 -> new_agentreq-003 -> stable_agentreq-004 -> stable_agent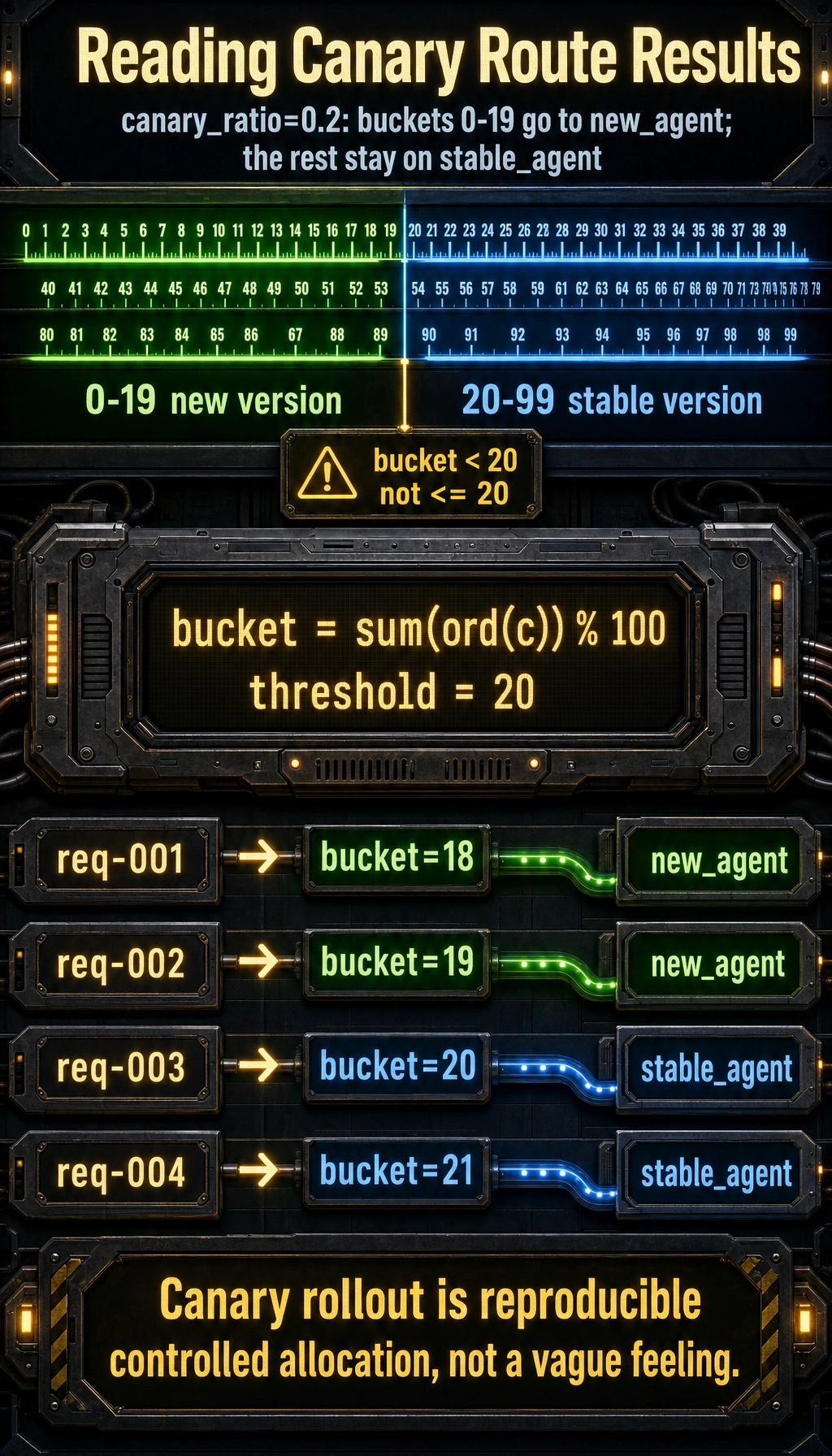
Although this code is simple, it shows that:
- Canary rollout is not mysterious
- In essence, it is controlled traffic allocation
Why Must Rollback Be Designed in Advance?
Section titled “Why Must Rollback Be Designed in Advance?”Rollback is not something you improvise after something breaks
Section titled “Rollback is not something you improvise after something breaks”If the system has a problem and you only then start thinking about:
- Which version to switch back to
- How to restore state
- How to handle data side effects
it is usually already too late.
Rollback should answer at least three questions
Section titled “Rollback should answer at least three questions”- How do you switch back to the old version?
- How do you handle intermediate state created by the new version?
- Do you need to pause high-risk actions?
Why is rollback more complex for Agents than for ordinary pages?
Section titled “Why is rollback more complex for Agents than for ordinary pages?”Because it may have already produced:
- Tool-call side effects
- Persistent state
- Writes to external systems
So rollback is not just “switch the image,” but also a question of state consistency.
How Should Alerting and Human Takeover Work Together?
Section titled “How Should Alerting and Human Takeover Work Together?”More alerts are not always better
Section titled “More alerts are not always better”The key is:
- Alerts should trigger specific actions
For example:
- Timeout rate > 5%
- Circuit breaker stays open continuously
- Cost suddenly deviates from the normal range
Human takeover is not system failure; it is system maturity
Section titled “Human takeover is not system failure; it is system maturity”In high-risk systems, human takeover means you acknowledge that:
- Automation is not unlimited
That is actually a sign of mature design.
Common takeover methods
Section titled “Common takeover methods”- Hand off to a human support agent
- Pause write operations
- Switch to read-only mode
- Require human approval
The Most Common Mistakes
Section titled “The Most Common Mistakes”Mistake 1: Only doing functional self-tests before launch
Section titled “Mistake 1: Only doing functional self-tests before launch”Without evaluation, observability, rollback, and canary rollout, functional self-tests are far from enough.
Mistake 2: Thinking only safety systems need auditing
Section titled “Mistake 2: Thinking only safety systems need auditing”Many ordinary business Agents also involve:
- User data
- Write operations
- External side effects
Auditing is just as important.
Mistake 3: Treating production best practices as just a checklist
Section titled “Mistake 3: Treating production best practices as just a checklist”A checklist is important, but it is only truly useful when:
- The team knows who is responsible
- People will actually execute it when something goes wrong
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Runtime
- queues, workers, state store, tool services, and model endpoint
- Persistence
- checkpoints, event log, memory store, and recovery path
- Ops Signal
- latency, cost, error rate, trace coverage, and saturation
- Failure Check
- stuck run, duplicate action, partial failure, or runaway cost
- Recovery Action
- resume, rollback, cancel, human handoff, or degrade gracefully
Summary
Section titled “Summary”The most important thing in this section is to build a production mindset:
Agent production readiness does not end when the function works. It must also include canary rollout, rollback, alerting, auditing, and human takeover mechanisms.
Only when these mechanisms are in place does the system deserve to be called “production.”
Exercises
Section titled “Exercises”- Based on your current project, create your own readiness configuration table and see which items are missing.
- Why is canary rollout more important for Agents than for static pages?
- If a high-risk tool call starts happening abnormally often, would you first add alerting, circuit breaking, or human takeover? Why?
- Think about it: why is rollback not just “switching the code back to the previous version”?
Project reference and review notes
- A readiness table should include owner, status, evidence, and next action for tools, permissions, tracing, evaluation cases, rollback, budget limits, human approval, and incident response.
- Canary rollout matters for Agents because behavior depends on prompts, tools, external data, model versions, and user goals. Small traffic exposure catches failures that static page checks cannot.
- If high-risk calls spike, add alerting immediately so humans know, then use circuit breaking if the behavior is dangerous or unexplained, and human takeover for cases that must continue safely.
- Rollback is more than switching code because prompts, model versions, tool schemas, memory, queues, cached results, and external side effects may also need to be reverted or reconciled.