4.3.1 Calculus Roadmap: How Models Learn by Reducing Loss
Calculus explains how a model changes its parameters. The first goal is intuition: measure change, move in a better direction, repeat.
Look at the Map First
Section titled “Look at the Map First”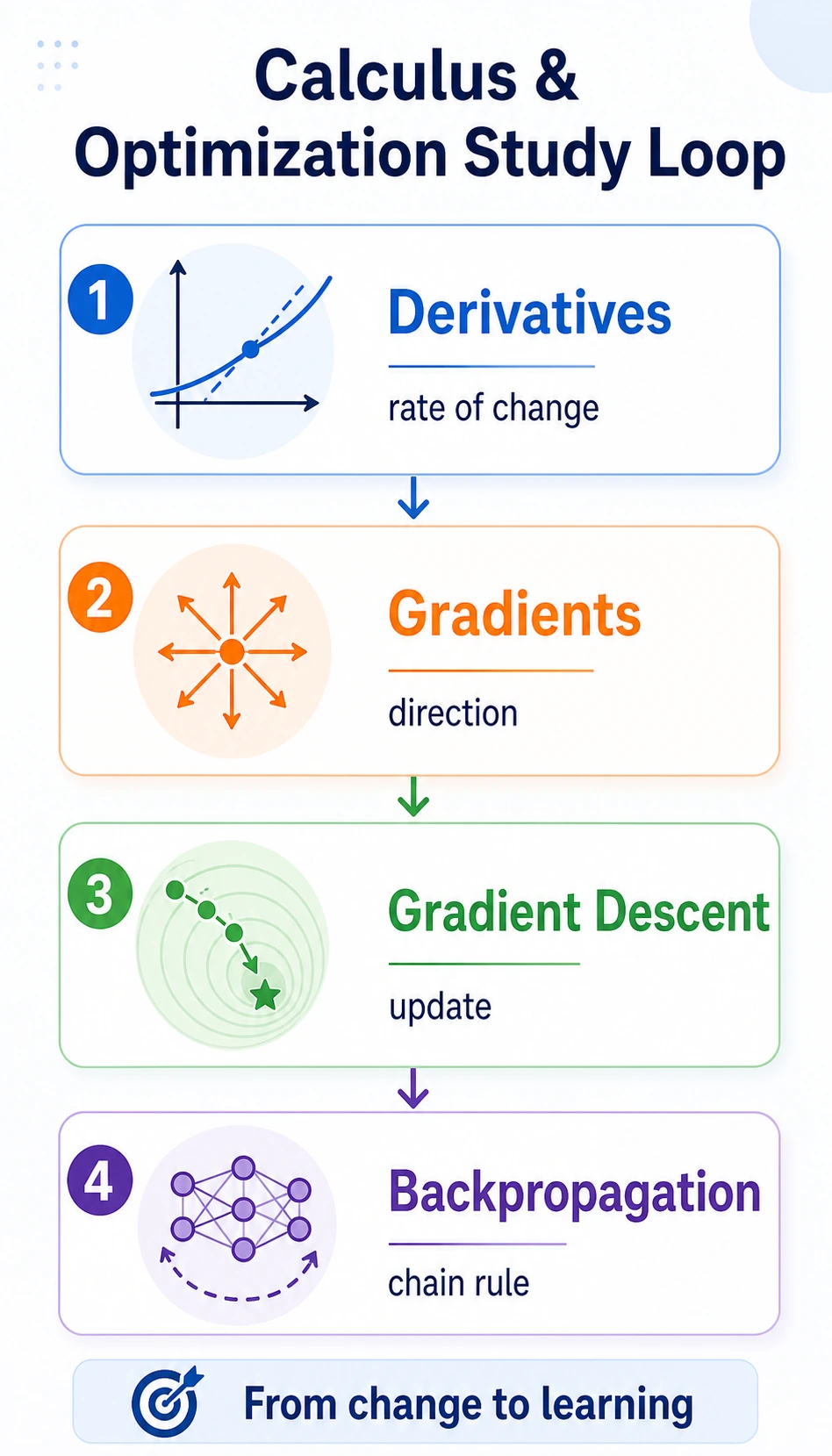
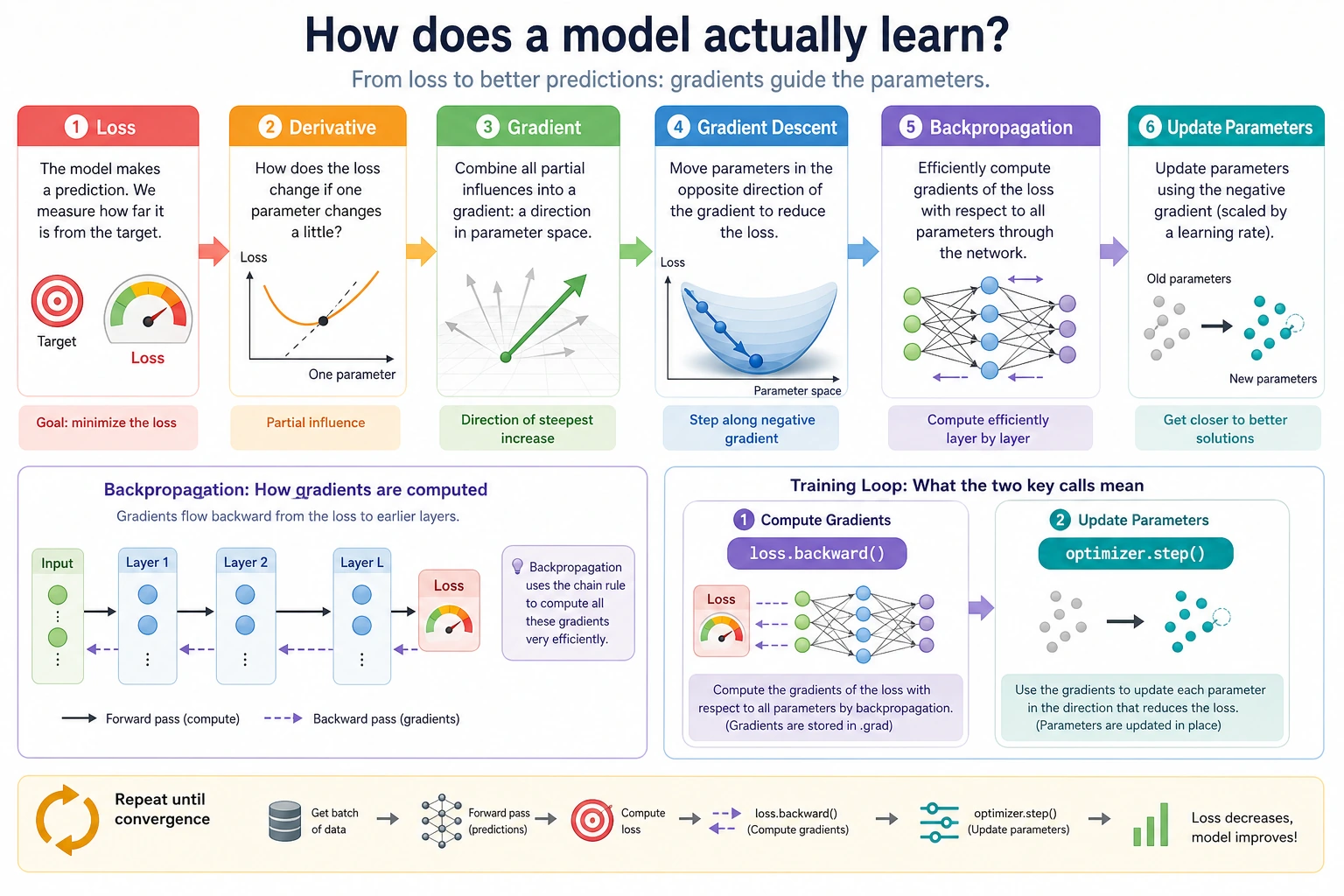
The training flow is:
| Idea | First meaning in AI |
|---|---|
| derivative | how fast one value changes |
| gradient | how many parameters should change together |
| gradient descent | update parameters toward lower loss |
| chain rule | connect changes across steps |
| backpropagation | compute many gradients efficiently |
When you later see loss.backward() and optimizer.step(), this chapter is the background.
Run the Smallest Loop
Section titled “Run the Smallest Loop”Create gradient_descent_first_loop.py. It finds a number close to 3 by reducing (w - 3)^2.
w = 0.0learning_rate = 0.2
for step in range(1, 7): gradient = 2 * (w - 3) w = w - learning_rate * gradient loss = (w - 3) ** 2 print(step, "w=", round(w, 3), "loss=", round(loss, 3))Expected output:
1 w= 1.2 loss= 3.242 w= 1.92 loss= 1.1663 w= 2.352 loss= 0.424 w= 2.611 loss= 0.1515 w= 2.767 loss= 0.0546 w= 2.86 loss= 0.02The number moves toward 3, and the loss gets smaller. That is the training idea before the neural network becomes large.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to focus on first |
|---|---|---|
| 1 | 4.3.2 Derivatives | rate of change |
| 2 | 4.3.3 Partial Derivatives and Gradients | many parameters changing together |
| 3 | 4.3.4 Gradient Descent | update loop, learning rate, loss curve |
| 4 | 4.3.5 Backpropagation | chain rule, loss.backward() intuition |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Function
- objective, loss, derivative, gradient, or chain-rule expression
- Calculation
- numeric derivative, gradient step, or backprop trace
- Output
- slope, gradient vector, updated parameter, or loss change
- Failure Check
- sign error, learning rate too large, local slope misunderstanding, or broken chain
- Expected Output
- calculation trace showing how a parameter changes
Pass Check
Section titled “Pass Check”You pass this roadmap when you can explain why gradient descent repeats “compute loss -> compute gradient -> update parameter,” and why a learning rate that is too large can make training unstable.
Check reasoning and explanation
- The calculus route is passed when you can explain derivative as local change, gradient as multi-parameter direction, and gradient descent as repeated loss-reducing updates.
- Keep a derivative plot, one gradient vector, one loss curve, and one manual-versus-autograd comparison as evidence.
- The safest habit is to always ask: if the parameter moves a little in this direction, does the loss go up or down?