E.A.1 C++ Programming Basics
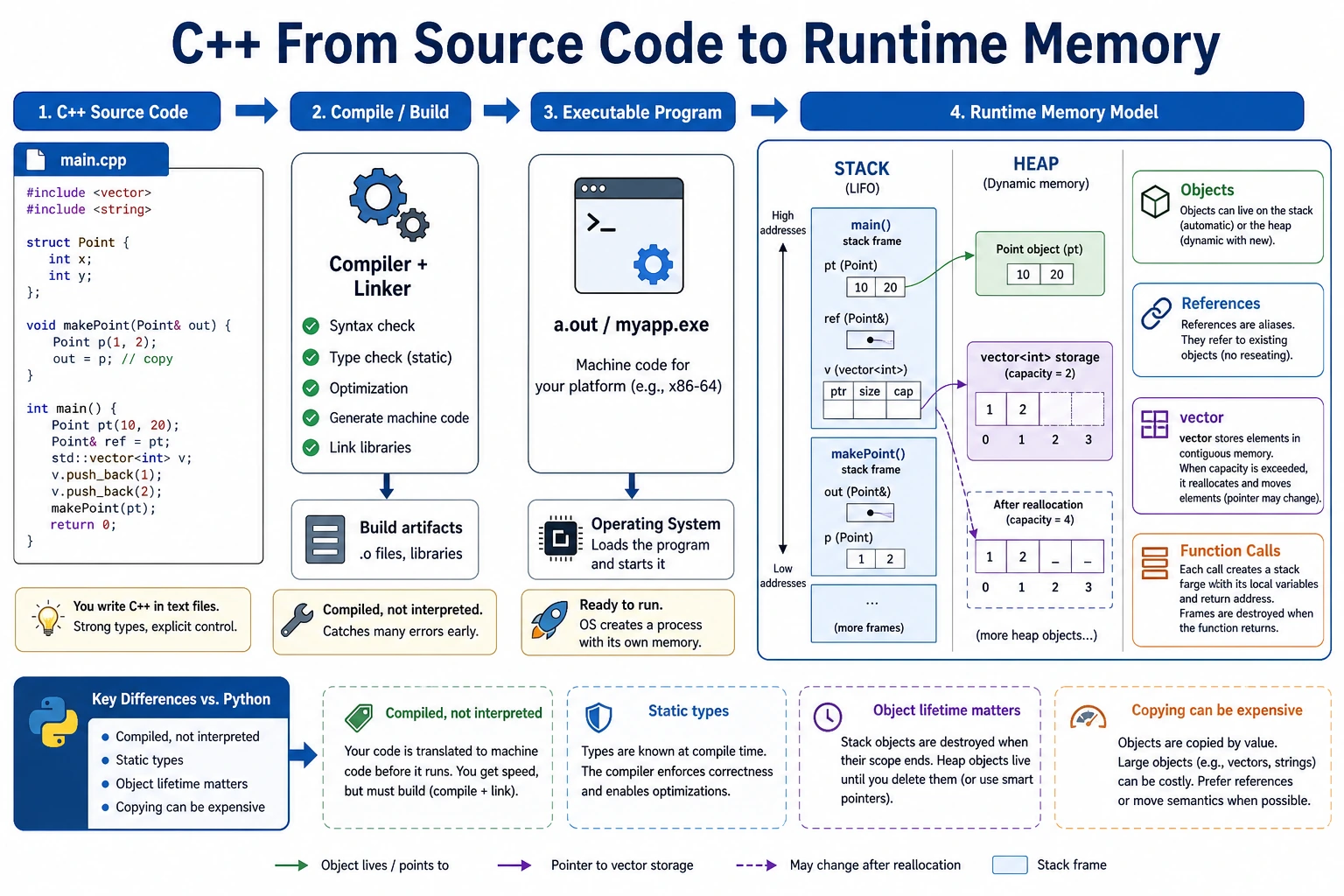
You do not need to become a C++ expert before reading deployment code. First learn the small subset that appears again and again: types, functions, std::vector, references, compilation, and clear output.
Run the smallest inference-style program
Section titled “Run the smallest inference-style program”Create demo.cpp:
#include <iostream>#include <vector>
int main() { std::vector<float> logits = {1.2f, 0.3f, 2.1f}; int best_index = 0;
for (int i = 1; i < static_cast<int>(logits.size()); ++i) { if (logits[i] > logits[best_index]) { best_index = i; } }
std::cout << "best_class=" << best_index << "\n"; std::cout << "score=" << logits[best_index] << "\n"; return 0;}Run it:
c++ -std=c++17 demo.cpp -o demo./demoExpected output:
best_class=2score=2.1What to notice
Section titled “What to notice”| C++ idea | Deployment meaning |
|---|---|
std::vector<float> | A simple tensor-like container |
explicit type float / int | The compiler must know data shapes and value types |
static_cast<int>(...) | Convert types deliberately instead of hoping it works |
| compile then run | Deployment usually produces a binary, not just a script |
| printed result | Every deployment test needs reproducible evidence |
How to Read This Like Deployment Code
Section titled “How to Read This Like Deployment Code”When you see C++ inside an inference runtime, slow down around three things:
- Data container: ask what shape and value type the code is carrying. Here it is a tiny
std::vector<float>, but in real runtimes it may be a tensor buffer. - Boundary between code and evidence: compilation proves the code is valid; printed output proves the runtime path actually ran.
- Failure point: if the result is wrong, check input values, index logic, type conversion, and the final print before changing the whole program.
This small example is not trying to teach all of C++. It teaches a deployment habit: make the input visible, make the decision rule visible, and keep an output that another person can rerun.
Deployment Review
Section titled “Deployment Review”Before moving on, connect the toy program to a real inference review. Ask what the vector represents, where the class names would come from, and how another person would reproduce the same output. In a real project, logits might come from an ONNX model, a TensorRT engine, or a Python-exported test fixture. The C++ code is only trustworthy when the input, decision rule, and printed evidence are all visible.
If the program compiles but the output is wrong, debug in this order: input values, loop bounds, comparison logic, and final label mapping. This order mirrors deployment debugging, where a runtime failure is often a data-shape or post-processing problem rather than a “C++ is broken” problem.
Practice change
Section titled “Practice change”Change the logits to:
std::vector<float> logits = {3.4f, 0.3f, 2.1f};Run again. The expected best_class should become 0.
Operation guide and checkpoints
After the change, the loop should compare 3.4, 0.3, and 2.1, so index 0 becomes the largest score. The useful explanation is not only “the number is bigger”; it is that the inference helper scans the logit vector and returns the position of the maximum value.
Keep this evidence:
- The compile command succeeds.
- The output changes to
best_class=0. - You can say
std::vector<float>is standing in for a small tensor or model-output array.
Pass check
Section titled “Pass check”You pass this lesson when you can compile the file, change the input values, explain why the selected class changed, and say what std::vector<float> represents in an inference program.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Deployment Target
- local inference, edge device, model server, or optimization experiment
- Artifact
- C++ snippet, benchmark, model artifact, serving config, or deployment note
- Metric
- latency, memory, throughput, model size, accuracy drop, or reliability
- Failure Check
- ABI/build issue, hardware mismatch, quantization loss, or serving bottleneck
- Expected Output
- reproducible deployment or optimization evidence, not only theory notes