10.4.1 Segmentation Roadmap: Pixel-Level Regions
Segmentation is finer than detection. Instead of a box, it outputs a mask that says which pixels belong to a class or instance.
See the Mask Workflow First
Section titled “See the Mask Workflow First”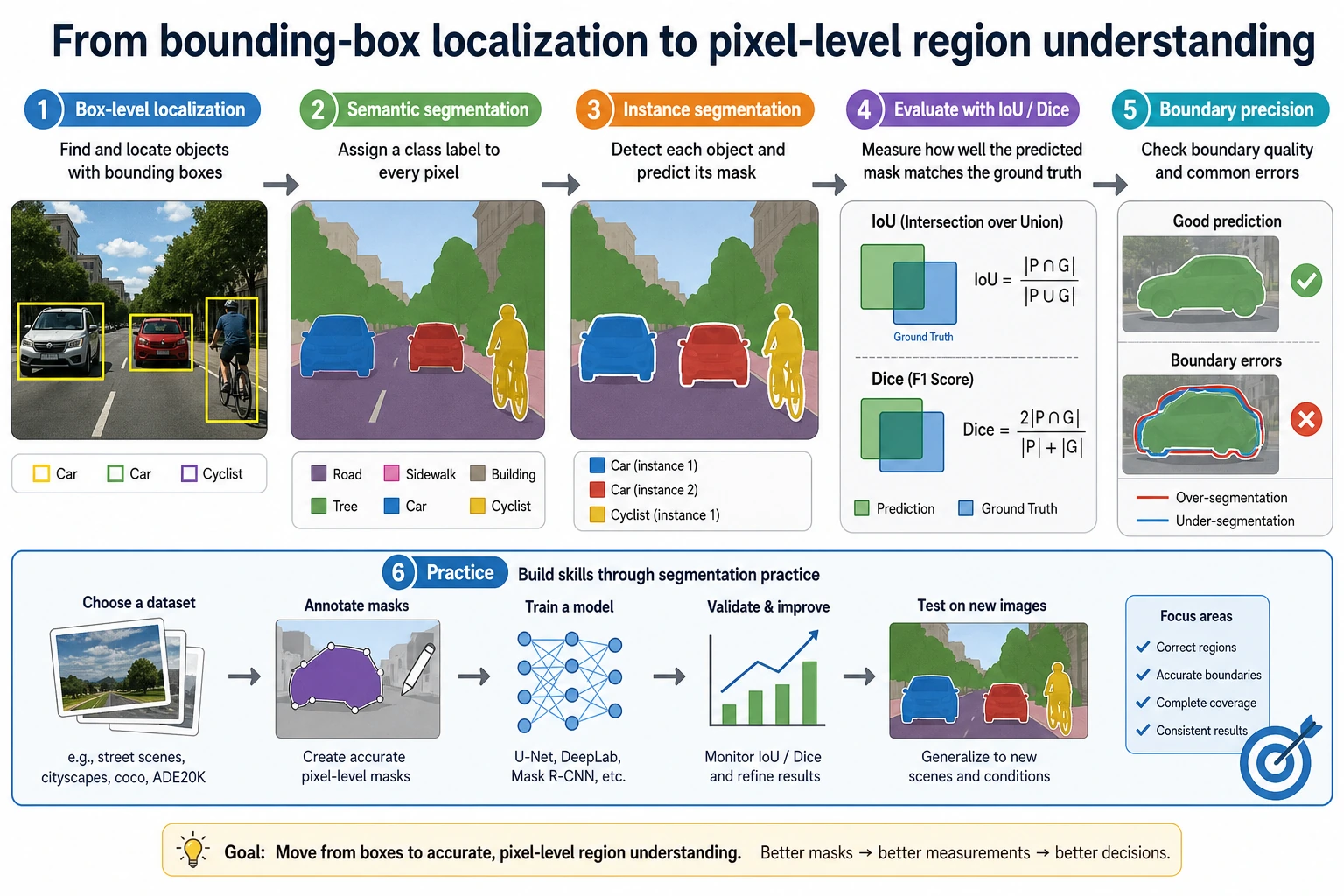
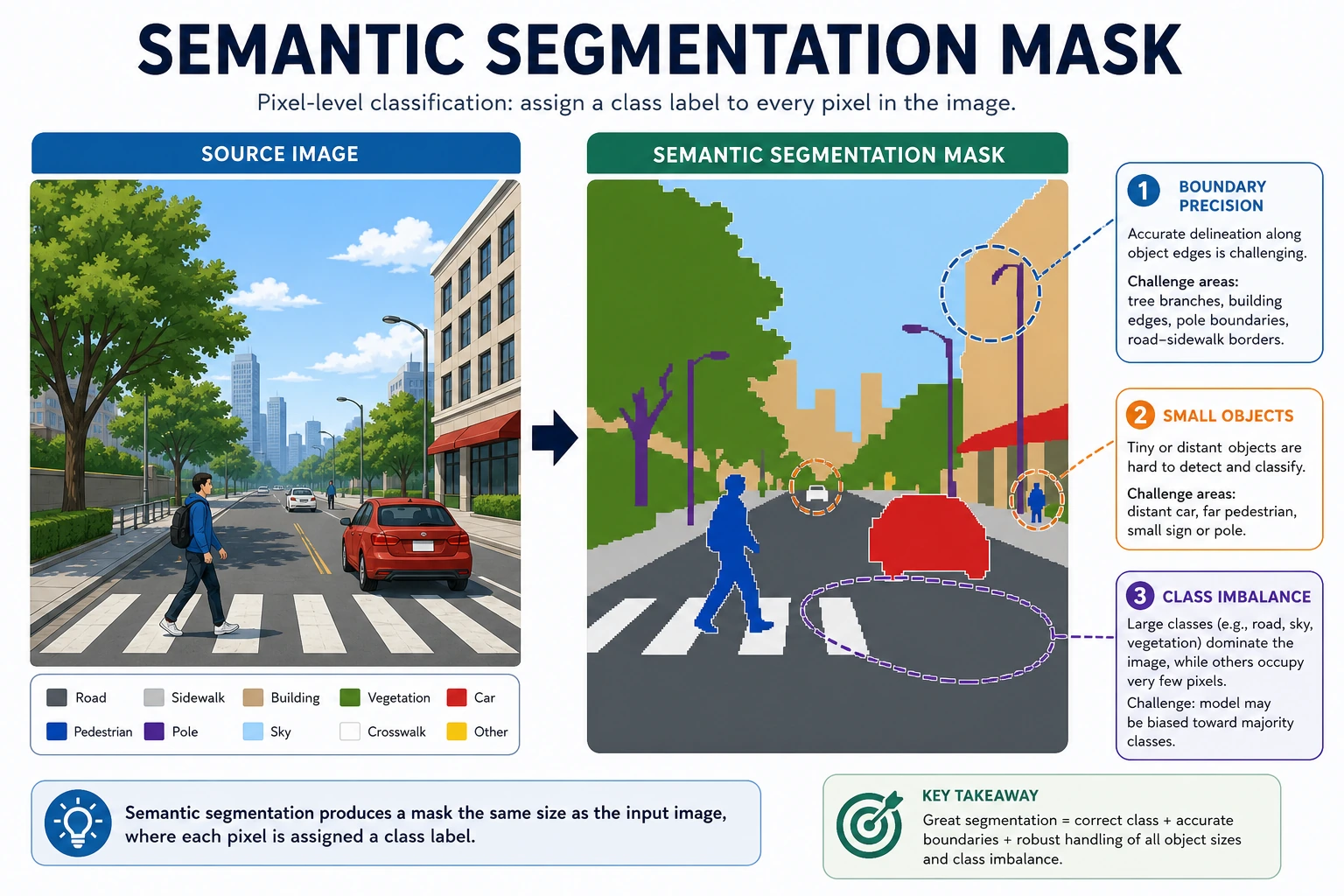
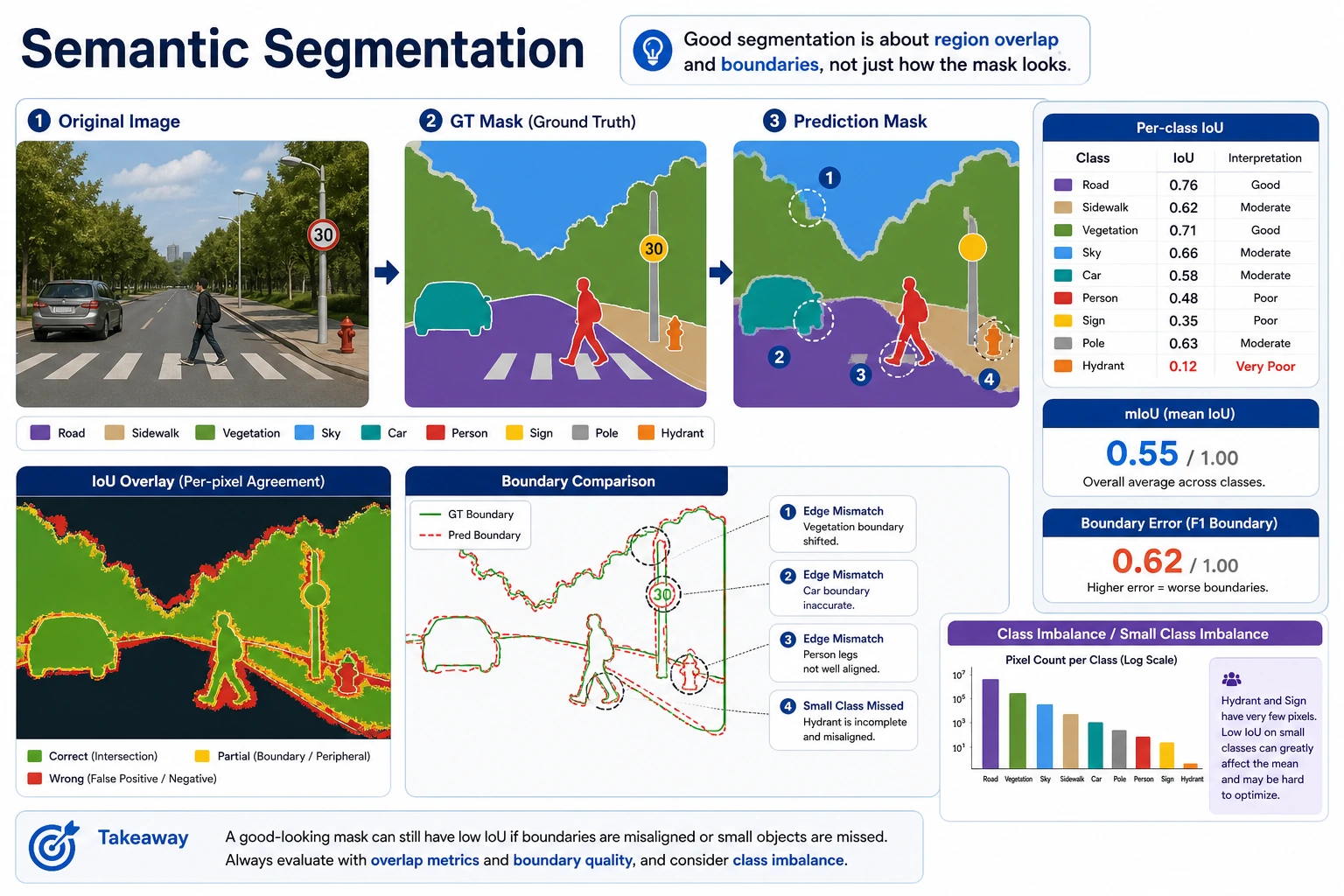
The main object in this chapter is the mask. The main failure is often boundary quality, tiny objects, occlusion, or class confusion.
Run a Mask IoU Check
Section titled “Run a Mask IoU Check”This script compares two tiny binary masks.
truth = [ [1, 1, 0], [1, 0, 0], [0, 0, 0],]
pred = [ [1, 0, 0], [1, 1, 0], [0, 0, 0],]
intersection = 0union = 0for y in range(3): for x in range(3): intersection += truth[y][x] == 1 and pred[y][x] == 1 union += truth[y][x] == 1 or pred[y][x] == 1
print("mask_iou:", round(intersection / union, 3))Expected output:
mask_iou: 0.5Segmentation reports should show masks, metrics, and boundary errors, not only a colored overlay.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | Semantic segmentation | Predict one class for every pixel |
| 2 | Instance segmentation | Separate different objects of the same class |
| 3 | Segmentation practice | Compare masks, IoU/Dice, boundary errors, and failed samples |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Input Image
- original image and target mask or class map
- Prediction
- predicted mask, overlay visualization, and boundary examples
- Metric
- IoU, Dice, per-class score, and boundary failure notes
- Failure Check
- annotation quality, thin boundary, small region, or class confusion
- Expected Output
- mask overlay plus segmentation metric summary
Pass Check
Section titled “Pass Check”You pass this chapter when you can create or inspect a mask, compute a simple overlap metric, and explain one boundary or class-confusion failure.
Check reasoning and explanation
- A passing answer maps the task to the right visual output: class label, bounding box, mask, OCR text, embedding, or video event.
- The evidence should include a rendered visual artifact and one metric or qualitative error note.
- A good self-check names one visual failure mode such as class confusion, missed objects, bad masks, lighting shift, domain shift, or weak annotation quality.