10.3.5 Detection Practice
Learning objectives
Section titled “Learning objectives”- Learn how to define a minimal object detection project
- Understand the logic of annotation, box matching, and evaluation in detection projects
- Build an IoU-driven evaluation intuition through a runnable example
- Set up a presentation scaffold for a detection project
First, build a map
Section titled “First, build a map”If you just finished the detection overview, classic detectors, and YOLO, the most natural continuation here is:
- You already know what detection tasks are solving
- Now we ask, “If we turn this into a real project, where should we start?”
So the truly important part of this section is not a new model, but:
- Class definition
- Annotation standards
- Evaluation criteria
- Error analysis
For beginners, the best order to understand detection practice is not “train a model first,” but to first see the project loop clearly:
flowchart LR A["Define classes and boundaries"] --> B["Unify annotation standards"] B --> C["Build a baseline first"] C --> D["Evaluate with IoU / mAP"] D --> E["Analyze missed detections and false detections"]So what this section really wants to solve is:
- How a detection project should move forward
- Which parts are more likely to go wrong than the model structure itself
What should be defined first in a detection project?
Section titled “What should be defined first in a detection project?”Class boundaries
Section titled “Class boundaries”For example, in a security scenario you might only start with:
- person
- helmet
instead of trying to cover every possible target from the beginning.
Annotation standards
Section titled “Annotation standards”You must first make it clear:
- How tight the box should be
- How to label occlusion
- How to handle small objects
Evaluation criteria
Section titled “Evaluation criteria”At minimum, you need to clarify:
- IoU threshold
- Recall / precision
When a beginner builds a detection project for the first time, how should they choose the task to make it more stable?
Section titled “When a beginner builds a detection project for the first time, how should they choose the task to make it more stable?”A more stable task usually has these characteristics:
- Not too many classes
- Clear target definitions
- False detections and missed detections that can be understood with the naked eye
So when you do your first project, “fewer classes, stronger definitions, easier explanation” is usually more important than “a cooler task.”
Why is this step more important than “choosing a model first”?
Section titled “Why is this step more important than “choosing a model first”?”Because if these things are not settled well at the start:
- Class boundaries
- Annotation rules
- Box conventions
- IoU threshold
Then no matter how many model comparisons you do later, you may still be spinning in circles on top of messy standards.
Run a minimal matching evaluation example first
Section titled “Run a minimal matching evaluation example first”ground_truth = [ {"label": "person", "box": (10, 10, 30, 50)}, {"label": "helmet", "box": (14, 8, 24, 18)},]
predictions = [ {"label": "person", "box": (11, 12, 31, 48), "score": 0.92}, {"label": "helmet", "box": (15, 9, 23, 17), "score": 0.81}, {"label": "helmet", "box": (40, 40, 50, 50), "score": 0.30},]
def iou(box_a, box_b): ax1, ay1, ax2, ay2 = box_a bx1, by1, bx2, by2 = box_b
inter_x1 = max(ax1, bx1) inter_y1 = max(ay1, by1) inter_x2 = min(ax2, bx2) inter_y2 = min(ay2, by2)
inter_w = max(0, inter_x2 - inter_x1) inter_h = max(0, inter_y2 - inter_y1) inter_area = inter_w * inter_h
area_a = (ax2 - ax1) * (ay2 - ay1) area_b = (bx2 - bx1) * (by2 - by1) union = area_a + area_b - inter_area return inter_area / union if union else 0.0
matches = []for pred in predictions: best_iou = 0.0 best_gt = None for gt in ground_truth: if gt["label"] != pred["label"]: continue cur_iou = iou(pred["box"], gt["box"]) if cur_iou > best_iou: best_iou = cur_iou best_gt = gt matches.append( { "label": pred["label"], "score": pred["score"], "best_iou": round(best_iou, 4), "matched": best_iou >= 0.5, } )
print(matches)Expected output:
[{'label': 'person', 'score': 0.92, 'best_iou': 0.8182, 'matched': True}, {'label': 'helmet', 'score': 0.81, 'best_iou': 0.64, 'matched': True}, {'label': 'helmet', 'score': 0.3, 'best_iou': 0.0, 'matched': False}]Read this output row by row: the first two predictions match a ground-truth box with IoU above 0.5; the last helmet prediction has no matching helmet box, so it is a false detection.
What is the most important part of this code?
Section titled “What is the most important part of this code?”It shows you that detection evaluation is not:
- “The class is correct, so it’s fine”
Instead, it is:
- The class must be correct
- The box must also be accurate enough
Why is this the core judgment in many detection projects?
Section titled “Why is this the core judgment in many detection projects?”Because in real detection results, the final quality is often reflected in:
- Matching threshold
- Box quality
Why do detection projects especially need a “false detection / missed detection” perspective?
Section titled “Why do detection projects especially need a “false detection / missed detection” perspective?”Because detection systems rarely have only two outcomes: “correct” or “incorrect.” More often, you’ll see:
- The box is off
- The target was missed
- An extra box was reported
That is why, when presenting a detection project, it’s best not to show only a few success cases.
When doing a detection project for the first time, what types of errors are most worth separating first?
Section titled “When doing a detection project for the first time, what types of errors are most worth separating first?”A very practical way to categorize errors is:
-
Missed detection There is clearly a target, but the system did not report it.
-
False detection The system reported a target even though there was none.
-
Poor localization The class is correct, but the box deviation is too large.
Once you separate these three, many of your next iteration directions become much clearer immediately.
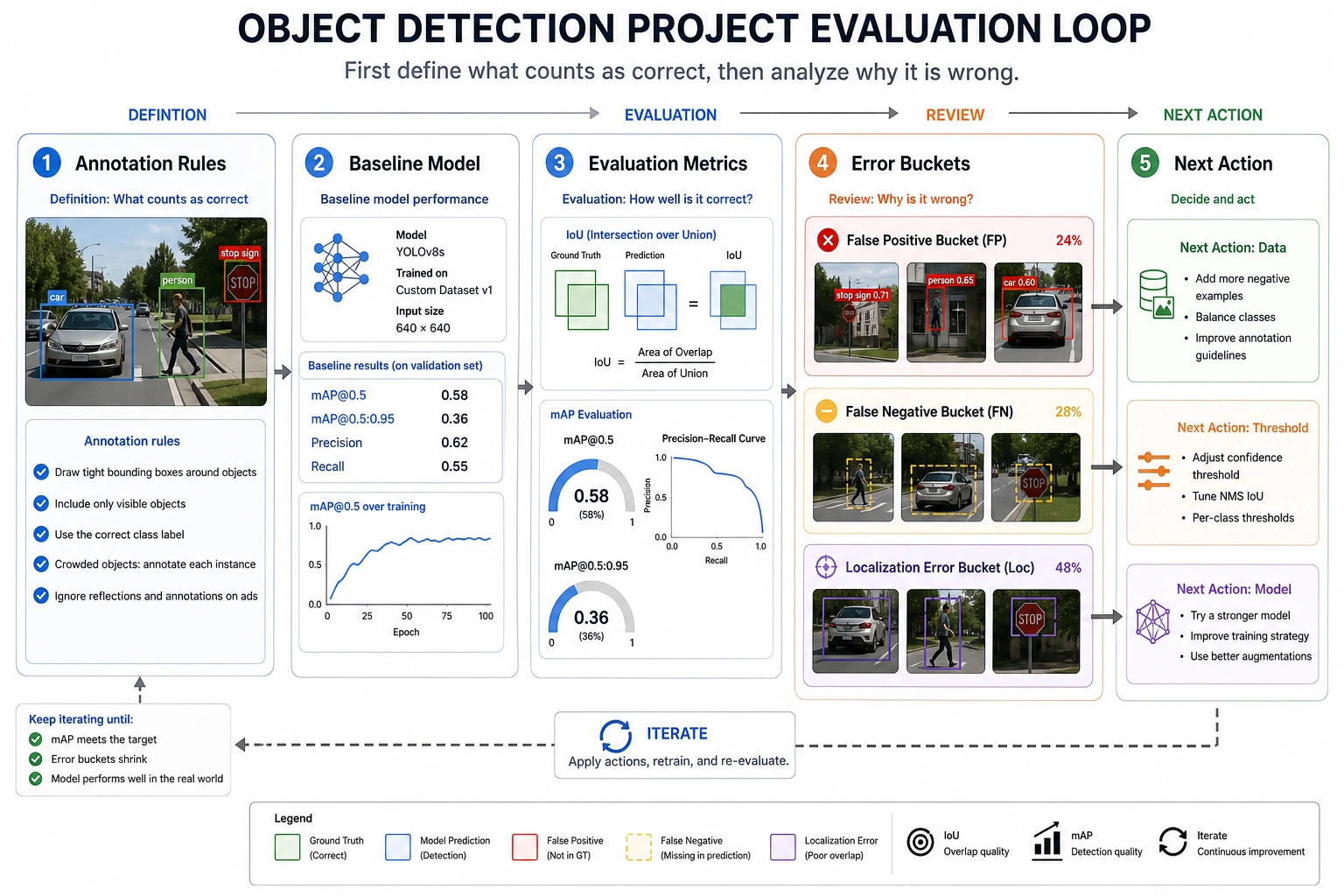
The most common pitfalls in detection projects
Section titled “The most common pitfalls in detection projects”Inconsistent annotation standards
Section titled “Inconsistent annotation standards”This will directly mess up both training and evaluation.
Small objects and occlusion are not analyzed separately
Section titled “Small objects and occlusion are not analyzed separately”Many systems show a clear drop in performance in these scenarios.
Only showing one or two pretty images
Section titled “Only showing one or two pretty images”A real project should also show:
- Which situations are likely to cause missed detections
- Which situations are likely to cause false detections
A progress order that beginners can directly follow
Section titled “A progress order that beginners can directly follow”A better approach is:
- Define the classes and annotation rules first
- Then sample and check annotation quality
- Build a minimal baseline first
- Unify the IoU / mAP evaluation criteria
- Finally, pick typical missed detections / false detections for analysis
If you turn it into a portfolio project, what is most worth showing?
Section titled “If you turn it into a portfolio project, what is most worth showing?”Compared with only showing one “prediction result” image, what is more valuable is:
- Class definitions and annotation rules
- The baseline IoU / mAP
- A set of typical false detection and missed detection cases
- How you explain these failures
- What you would improve first next: data, thresholds, or model
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Input Image
- detection sample with ground-truth or expected objects
- Prediction
- boxes, labels, confidence scores, IoU, and threshold settings
- Metric
- precision/recall, mAP, false positives, and false negatives
- Failure Check
- small object, overlap, NMS, poor labels, or confidence threshold
- Expected Output
- annotated image plus detection metrics or error buckets
Summary
Section titled “Summary”The most important thing in this section is to build a project mindset:
The key to a detection project is not just the model name, but whether the class definitions, annotation standards, and box-level evaluation methods are clear.
What you should take away from this section
Section titled “What you should take away from this section”- A detection project is first an annotation and evaluation project, and only then a model project
- The IoU threshold and annotation conventions directly affect how you judge whether a detection is correct
- False detection / missed detection analysis is one of the most valuable parts of a detection project to present
If we compress it into one sentence, it is:
The real difficulty in a detection project is often not getting the model to run, but clearly defining what counts as a correct detection.
Exercises
Section titled “Exercises”- Change the IoU threshold to
0.7and see how the matching result changes. - Think about why detection projects depend more on clear annotation standards than classification projects do.
- If a project keeps missing small objects, would you check the data, input resolution, or model structure first?
- How would you package this detection project into a portfolio piece?
Project reference and review notes
- Changing the IoU threshold to
0.7makes matching stricter. Boxes that counted as true positives at0.5may become false positives or false negatives. - Detection depends heavily on annotation standards because the box itself is part of the label. Small differences in box rules can change IoU and mAP.
- For repeated small-object misses, check data and annotation quality plus input resolution first. If the object is absent, mislabeled, or downsampled away, changing the model will not fix the root cause.
- A portfolio version should include class definitions, annotation examples, baseline metrics, typical false positives/misses, and a clear next-improvement plan.