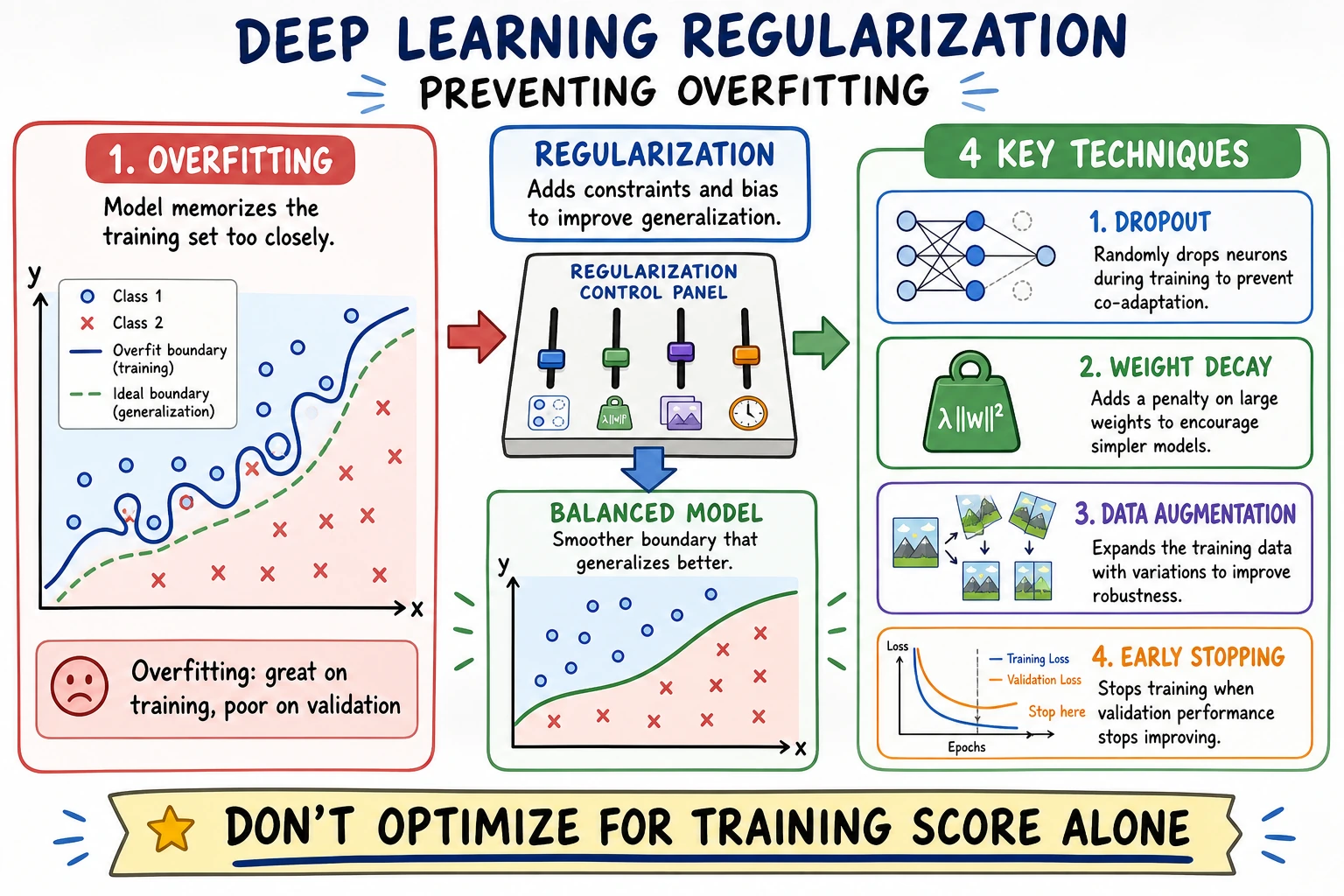
6.1.6 Regularization
What You Will Build
Section titled “What You Will Build”This lesson runs one PyTorch lab that compares:
- no regularization;
- dropout;
- weight decay;
- dropout plus weight decay;
- early stopping behavior through
best_epoch.
python -m pip install -U torch scikit-learnRun the Complete Lab
Section titled “Run the Complete Lab”Create regularization_lab.py:
import torchimport torch.nn as nnfrom sklearn.datasets import make_moonsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler
def make_data(): X, y = make_moons(n_samples=500, noise=0.28, random_state=42) X = StandardScaler().fit_transform(X) X_train, X_val, y_train, y_val = train_test_split( X, y, test_size=0.35, random_state=42, stratify=y ) return ( torch.tensor(X_train, dtype=torch.float32), torch.tensor(y_train.reshape(-1, 1), dtype=torch.float32), torch.tensor(X_val, dtype=torch.float32), torch.tensor(y_val.reshape(-1, 1), dtype=torch.float32), )
class MLP(nn.Module): def __init__(self, dropout=0.0): super().__init__() self.net = nn.Sequential( nn.Linear(2, 32), nn.ReLU(), nn.Dropout(dropout), nn.Linear(32, 32), nn.ReLU(), nn.Dropout(dropout), nn.Linear(32, 1), )
def forward(self, x): return self.net(x)
def accuracy(logits, y): pred = (torch.sigmoid(logits) >= 0.5).float() return (pred == y).float().mean().item()
def train_case(name, dropout=0.0, weight_decay=0.0, epochs=120): torch.manual_seed(42) X_train, y_train, X_val, y_val = make_data() model = MLP(dropout=dropout) loss_fn = nn.BCEWithLogitsLoss() optimizer = torch.optim.AdamW(model.parameters(), lr=0.01, weight_decay=weight_decay) best_val = 10**9 patience = 0 best_epoch = 0 for epoch in range(1, epochs + 1): model.train() loss = loss_fn(model(X_train), y_train) optimizer.zero_grad() loss.backward() optimizer.step()
model.eval() with torch.no_grad(): val_loss = loss_fn(model(X_val), y_val).item() if val_loss < best_val: best_val = val_loss best_epoch = epoch patience = 0 else: patience += 1 if patience >= 20: break
model.eval() with torch.no_grad(): train_loss = loss_fn(model(X_train), y_train).item() val_loss = loss_fn(model(X_val), y_val).item() train_acc = accuracy(model(X_train), y_train) val_acc = accuracy(model(X_val), y_val) print( f"{name:<14} epochs={epoch:<3} best_epoch={best_epoch:<3} " f"train_loss={train_loss:.3f} val_loss={val_loss:.3f} " f"train_acc={train_acc:.3f} val_acc={val_acc:.3f}" )
print("regularization_lab")train_case("plain", dropout=0.0, weight_decay=0.0)train_case("dropout", dropout=0.25, weight_decay=0.0)train_case("weight_decay", dropout=0.0, weight_decay=0.05)train_case("both", dropout=0.25, weight_decay=0.05)Run it:
python regularization_lab.pyExpected output:
regularization_labplain epochs=87 best_epoch=67 train_loss=0.141 val_loss=0.155 train_acc=0.945 val_acc=0.931dropout epochs=101 best_epoch=81 train_loss=0.158 val_loss=0.162 train_acc=0.945 val_acc=0.943weight_decay epochs=87 best_epoch=67 train_loss=0.141 val_loss=0.154 train_acc=0.948 val_acc=0.931both epochs=101 best_epoch=81 train_loss=0.159 val_loss=0.162 train_acc=0.942 val_acc=0.949
Read the Result
Section titled “Read the Result”The plain model has lower training loss:
plain train_loss=0.141 val_acc=0.931But the combined regularized model has better validation accuracy:
both train_loss=0.159 val_acc=0.949That is the point of regularization. You may accept a slightly worse training fit to get better generalization.
Evidence to Keep
Section titled “Evidence to Keep”For regularization, do not save only the lowest training loss. Save the tradeoff:
- Plain
- lower train_loss, lower validation accuracy
- Regularized
- slightly higher train_loss, better validation accuracy
- Decision
- choose the model with better validation behavior
- Next Probe
- change dropout or weight_decay one at a time
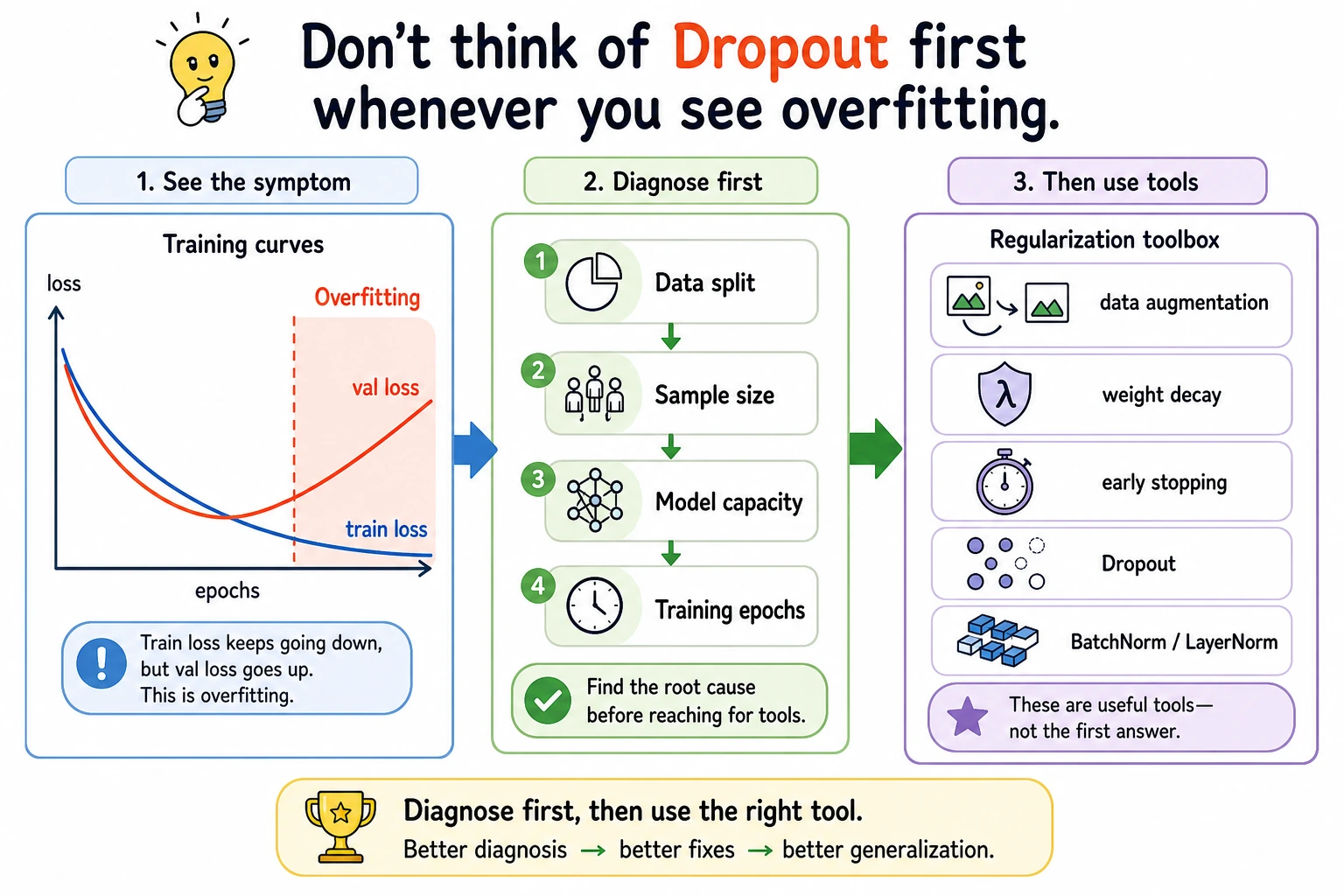
The important mental turn is this: deep learning optimization is not “make train loss smallest.” It is “make future performance more reliable.”
Dropout
Section titled “Dropout”nn.Dropout(0.25) randomly drops activations during training:
nn.Linear(2, 32), nn.ReLU(), nn.Dropout(dropout)It makes the network less dependent on any single hidden unit. Use it mainly in hidden layers. During model.eval(), dropout is disabled automatically.
Weight Decay
Section titled “Weight Decay”Weight decay is L2-style regularization applied by the optimizer:
torch.optim.AdamW(model.parameters(), lr=0.01, weight_decay=0.05)It discourages overly large weights. In modern PyTorch work, AdamW is often preferred over older Adam-with-L2 behavior because weight decay is decoupled from the adaptive gradient update.
Early Stopping
Section titled “Early Stopping”The lab tracks:
best_epoch=67Early stopping means: keep the best validation checkpoint and stop after validation loss fails to improve for a while. It prevents you from training long past the point where validation performance stopped improving.
What to Try First
Section titled “What to Try First”| Problem | First action |
|---|---|
| training loss low, validation loss high | add weight decay or dropout |
| validation improves then worsens | early stopping |
| model underfits both train and validation | reduce regularization or improve model |
| validation is noisy | lower LR, use more data, average across folds |
Practical Debugging Checklist
Section titled “Practical Debugging Checklist”| Symptom | Likely cause | Fix |
|---|---|---|
| dropout hurts training badly | dropout too high or model too small | lower dropout |
| train and validation both poor | underfitting | reduce regularization |
| validation best epoch much earlier | training too long | save best checkpoint |
| weight decay has no effect | value too small or model already simple | increase gradually |
| eval results change randomly | forgot model.eval() | switch eval mode before validation |
Practice
Section titled “Practice”- Change dropout to
0.1,0.5, and0.7. - Change weight decay to
0.001,0.01, and0.1. - Print train and validation loss every 20 epochs.
- Save the best model state when
val_lossimproves. - Remove
model.eval()during validation and explain what changes.
Reference implementation and walkthrough
dropout=0.1is mild,0.5is strong but common, and0.7may underfit because too much signal is removed during training.- Small weight decay can improve validation loss; too much weight decay can force weights toward zero and hurt both train and validation performance.
- If train loss falls while validation loss rises, you are likely seeing overfitting. If both stay high, the model is probably underfitting or optimization is failing.
- The best checkpoint should be selected by validation loss, not by the last epoch. This protects you from keeping a model after it has started to overfit.
- Without
model.eval(), dropout and some normalization layers keep training behavior during validation, making validation results noisy or biased.
Pass Check
Section titled “Pass Check”You are done when you can explain:
- regularization aims at validation performance, not only training loss;
- dropout randomly disables hidden activations during training;
- weight decay discourages large weights;
- early stopping keeps the best validation point;
- too much regularization can cause underfitting.