11.6.4 GPT Series
Learning Objectives
Section titled “Learning Objectives”- Understand why GPT’s core training objective is “predict the next token”
- Understand the key differences between GPT and BERT in structure and tasks
- Understand why causal masking is necessary
- Experience autoregressive generation through a minimal bigram language model
- Understand the evolution logic of the GPT series from “completion models” to “conversational assistants”
Historical Background: How Did the GPT Line Emerge?
Section titled “Historical Background: How Did the GPT Line Emerge?”GPT is easier to understand as a sequence of milestones rather than focusing on just one model:
| Year | Milestone | Representative paper | Main contribution |
|---|---|---|---|
| 2018 | GPT-1 | Improving Language Understanding by Generative Pre-Training | Brought the decoder-only pretraining path into the mainstream |
| 2019 | GPT-2 | Language Models are Unsupervised Multitask Learners | Showed strong generation ability and zero-shot potential at larger scale |
| 2020 | GPT-3 | Language Models are Few-Shot Learners | Brought in-context learning / few-shot behavior into the mainstream |
For beginners, the most important thing to remember first is:
GPT did not suddenly become “chatty”; instead, it kept scaling up and improving along the “predict the next token” path.
The conversational assistants, instruction following, and Agent capabilities we use later were all built by continuing to evolve this generation-centered line.
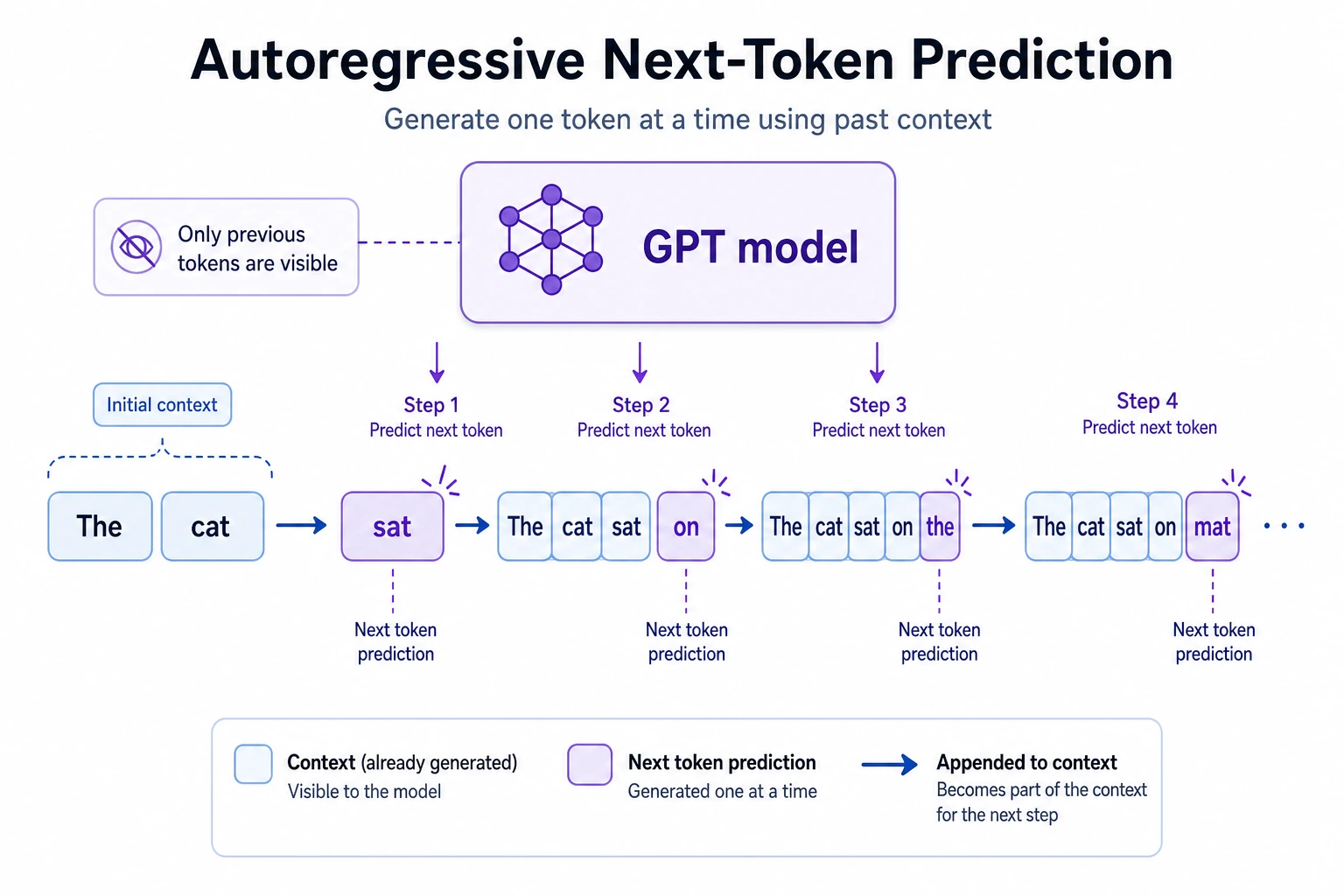
What Exactly Is GPT Doing?
Section titled “What Exactly Is GPT Doing?”The simplest one-sentence answer
Section titled “The simplest one-sentence answer”The most fundamental goal of the GPT line is:
Given the previous context, predict the next token.
For example:
Input:
“Beijing is China’s”
The model will tend to predict:
“capital”
This looks simple, but if you repeat this action many times:
- Predict one token
- Append it to the context
- Predict the next token again
You can generate a complete text step by step.
Why is this path so powerful?
Section titled “Why is this path so powerful?”Because the “predict the next token” objective is very general:
- It can learn language patterns
- It can learn knowledge patterns
- It can learn code structure
- It can learn reasoning traces
So GPT is powerful not because it was born knowing how to chat, but because:
It first learned large-scale language generation patterns.
A more beginner-friendly analogy
Section titled “A more beginner-friendly analogy”You can think of GPT as:
- someone who is very good at “continuing to write from what came before”
It may not be best at:
- strict structured understanding tasks at the beginning
But it is very good at:
- continuing to generate reasonable content based on the context already given
That is why the GPT path naturally grows into:
- dialogue
- writing
- code completion
The Fundamental Difference Between GPT and BERT
Section titled “The Fundamental Difference Between GPT and BERT”Remember this table first
Section titled “Remember this table first”| Model line | Core approach | What it is better at |
|---|---|---|
| BERT | Bidirectional context viewing | Understanding, matching, extraction |
| GPT | Left-to-right history only, autoregressive generation | Completion, dialogue, generation |
Why can’t GPT peek at the right side?
Section titled “Why can’t GPT peek at the right side?”Because training must match generation.
During generation, future content has not appeared yet, so training also cannot secretly look at future tokens. This is the causal / autoregressive constraint.
Why Is Causal Masking So Important for GPT?
Section titled “Why Is Causal Masking So Important for GPT?”An intuitive explanation
Section titled “An intuitive explanation”In GPT, when the model is predicting the token at position t:
- it can look at
1 ~ t-1 - it cannot look at anything after
t
It is like a cloze test:
- you can only see the text that has already been filled in
- you cannot peek at the answer key
A minimal mask example
Section titled “A minimal mask example”import numpy as np
seq_len = 5mask = np.tril(np.ones((seq_len, seq_len), dtype=int))
print(mask)The output will be a lower triangular matrix:
[[1 0 0 0 0] [1 1 0 0 0] [1 1 1 0 0] [1 1 1 1 0] [1 1 1 1 1]]It means:
- the 1st position can only see itself
- the 2nd position can see the first two
- the 5th position can see the first five
This is the source of consistency between GPT training and generation.
A very beginner-friendly comparison table
Section titled “A very beginner-friendly comparison table”| Question | GPT’s answer style |
|---|---|
| Can it see future tokens during training? | No |
| Can it see future tokens during generation? | No |
| Why is it designed this way? | To keep training and generation consistent |
This table is good for beginners because it turns “causal mask” from a technical term back into a very simple constraint:
- do not peek at the answer that comes later
A Truly Educational Minimal GPT Example: a Bigram Language Model
Section titled “A Truly Educational Minimal GPT Example: a Bigram Language Model”Why start with bigram?
Section titled “Why start with bigram?”Because it is very simple, yet it already lets you see with your own eyes:
- what it means to “predict the next word from the previous context”
- what autoregressive generation means
Runnable example
Section titled “Runnable example”from collections import defaultdict, Counterimport random
random.seed(7)
corpus = [ "I love AI", "I love Python", "You love AI", "We love learning"]
transitions = defaultdict(Counter)
for sentence in corpus: tokens = sentence.split() for a, b in zip(tokens[:-1], tokens[1:]): transitions[a][b] += 1
def sample_next(token): candidates = transitions[token] if not candidates: return None words = list(candidates.keys()) weights = list(candidates.values()) return random.choices(words, weights=weights, k=1)[0]
def generate(start, max_steps=5): tokens = [start] current = start for _ in range(max_steps): nxt = sample_next(current) if nxt is None: break tokens.append(nxt) current = nxt return " ".join(tokens)
for _ in range(5): print(generate("I"))Expected output:
I love AII love AII love AII love PythonI love AIThe fixed random seed makes the sampling result reproducible. The important behavior is the loop: every generated word is appended to the context, then the next word is sampled from the transition table again.
What is this code teaching exactly?
Section titled “What is this code teaching exactly?”It teaches you the smallest skeleton of GPT:
- Decide the next-word distribution based on the previous context
- Sample from that distribution
- Append the sampled result back
- Keep generating
This is already the minimal prototype of “autoregressive generation.”
Of course, real GPT is far more complex than this, but the main idea is the same.
The safest order for a first-time GPT learner
Section titled “The safest order for a first-time GPT learner”A more stable learning order is usually:
- First understand the sentence “predict the next token”
- Then see why causal masking is necessary
- Then use a minimal model like bigram to build autoregressive intuition
- Finally look at the scale evolution of GPT-1 / 2 / 3
This is easier to understand than jumping straight into parameter counts and release dates.
Why Is GPT Decoder-Only?
Section titled “Why Is GPT Decoder-Only?”Because its core task is step-by-step generation
Section titled “Because its core task is step-by-step generation”GPT series are usually based on a decoder-only Transformer:
- each position only sees the left side
- causal masking prevents peeking into the future
- each step outputs the distribution of the next token
The biggest difference from encoder-only models (such as BERT) is:
GPT’s architecture is naturally built for “completion and generation.”
A small offline randomly initialized GPT shape example
Section titled “A small offline randomly initialized GPT shape example”If you want to feel more intuitively what a “decoder-only LM” outputs, you can use a locally randomly initialized small model without downloading weights:
import torchfrom transformers import GPT2Config, GPT2LMHeadModel
config = GPT2Config( vocab_size=100, n_positions=16, n_ctx=16, n_embd=32, n_layer=2, n_head=4)
model = GPT2LMHeadModel(config)
input_ids = torch.tensor([ [1, 7, 9, 12, 5], [1, 3, 4, 8, 0]])
outputs = model(input_ids=input_ids)logits = outputs.logits
print("input_ids shape:", input_ids.shape)print("logits shape :", logits.shape)Expected output:
input_ids shape: torch.Size([2, 5])logits shape : torch.Size([2, 5, 100])The last dimension is vocab_size=100: for each sample and each position, the model returns 100 raw scores, one for each possible next token in the toy vocabulary.
Here logits.shape will be:
[batch, seq_len, vocab_size]
This means:
For each position, the model is predicting the distribution of the “next token.”
What Is In-Context Learning?
Section titled “What Is In-Context Learning?”Why does GPT increasingly look like it can learn rules on the spot?
Section titled “Why does GPT increasingly look like it can learn rules on the spot?”As models grow larger, the GPT line gradually shows an important ability:
Without changing parameters, it can temporarily learn to do something just from examples in the context.
For example:
Input: Apples are very tastyOutput: positive
Input: This class is so messyOutput: negative
Input: The teacher explains very clearlyOutput:The model might then continue with:
positiveThat is the feel of in-context learning.
Why is this important?
Section titled “Why is this important?”Because it means:
- not every task needs model retraining
- a Prompt itself can become a temporary task configuration method
This laid a large foundation for later Prompt engineering, Agents, and tool use.
How Has the GPT Series Evolved Step by Step?
Section titled “How Has the GPT Series Evolved Step by Step?”A rough timeline
Section titled “A rough timeline”You can remember this path first:
- Build stronger autoregressive language models
- As models get larger, general generation ability becomes stronger
- Then use instruction tuning, alignment, and preference optimization
- Finally, they become more like “assistants”
From “can complete text” to “can cooperate”
Section titled “From “can complete text” to “can cooperate””Early GPT was more like:
- a powerful text completion model
Later, after:
- instruction tuning
- preference learning
- safety alignment
it gradually became the chat assistant we use today, which is much better at collaborating with people.
In other words:
GPT’s conversational ability does not come only from pretraining; it also comes from later alignment.
What Is GPT Best At? What Is It Not Naturally Good At?
Section titled “What Is GPT Best At? What Is It Not Naturally Good At?”Strengths
Section titled “Strengths”- text generation
- dialogue
- summarization
- rewriting
- code generation
- open-ended completion
Not naturally good at
Section titled “Not naturally good at”- strict factual retrieval
- long-term stable memory
- highly constrained structured execution
So in real systems, GPT is often paired with:
- RAG
- tool calling
- memory systems
- guardrails
If you turn this into notes or a project, what is most worth showing?
Section titled “If you turn this into notes or a project, what is most worth showing?”What is most worth showing is usually not:
- “GPT is powerful”
but rather:
- the main line from next-token prediction to autoregressive generation
- why causal masking keeps training and generation consistent
- the capability evolution represented by GPT-1 / 2 / 3
- why it still needs Prompt, RAG, tools, and alignment systems afterward
That way, others can more easily see:
- you understand the capability skeleton of GPT
- not just that it is popular
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Model Choice
- BERT, GPT, T5, Transformers pipeline, or other pretrained baseline
- Tokenizer Output
- ids, masks, decoded text, or batch shape
- Task Result
- classification, generation, extraction, or text-to-text output
- Failure Check
- wrong model family, token limit, domain mismatch, cost, or latency
- Expected Output
- model call result plus a short choice rationale
Common Pitfalls for Beginners
Section titled “Common Pitfalls for Beginners”Thinking GPT is just a “chatting model”
Section titled “Thinking GPT is just a “chatting model””Chatting is only the surface. The root is autoregressive language modeling.
Thinking GPT can also look bidirectionally during training
Section titled “Thinking GPT can also look bidirectionally during training”No. The key GPT constraint is that it cannot peek at the future.
Only knowing “the model is big,” but not understanding what its output tensor means
Section titled “Only knowing “the model is big,” but not understanding what its output tensor means”What you really need to remember is:
- each position predicts a distribution over the next token
- generation is rolled out step by step
Summary
Section titled “Summary”The most important thing in this section is not remembering the name of a certain GPT version, but grasping this main line:
GPT = decoder-only + causal mask + next-token prediction + autoregressive generation.
Once you understand this line, when you later learn Prompt, Agent, tool calling, and LLM applications, you will know exactly what capabilities they are built on.
Exercises
Section titled “Exercises”- Modify the corpus in the bigram example and observe how the generated results change.
- Explain in your own words: why is causal masking necessary for GPT?
- Understand the
logitsshape in the randomly initialized GPT example — why is it[batch, seq_len, vocab_size]? - Think about this: why can’t GPT’s “ability to chat” be simply reduced to “it only predicts the next word”?
Reference implementation and walkthrough
- Changing the corpus changes the bigram transition table, so generated text should follow the local patterns of your new corpus.
- Causal masking is necessary because GPT must not see future tokens when learning to predict the next token.
[batch, seq_len, vocab_size]means every position in every sequence gets a score distribution over the vocabulary.- Chat ability is not only next-token prediction in isolation; it emerges from scale, training data, instruction tuning, feedback, tools, memory, and context management.