8.5.5 Project: Knowledge Base-Driven SOP Document Assistant
Learning Objectives
Section titled “Learning Objectives”- Learn how to organize “incident topic -> policy retrieval -> case extraction -> SOP draft” into a complete workflow
- Learn how to define the minimum project boundary for a knowledge base-driven SOP document system
- Learn how to design internal policy retrieval and external support-note supplementation separately
- Learn how to turn this project into a portfolio-quality system with a product feel
Beginner Terminology Bridge
Section titled “Beginner Terminology Bridge”This project crosses document processing, retrieval, generation, and export. Clarify these terms first:
| Term | Beginner meaning | Role in this project |
|---|---|---|
ingestion | Bringing files into the system and preparing them for processing | PDF / Word / PPT policy materials enter the pipeline here |
policy and case extraction | Identifying policy clauses, decision rules, handled cases, and review checklists from documents | SOP drafts need operational evidence, not just paragraphs |
schema | A stable data structure that defines the SOP output | Keeps retrieval, generation, and template export aligned |
template rendering | Filling structured content into a Word or PPT template | Separates content generation from document formatting |
source_refs | Source references kept with each generated section or item | Lets the final Word draft explain where the content came from |
internal vs external materials | Internal materials are trusted company policy; external materials are supplements | Prevents external notes from overriding official policy |
The core judgment is: the model should not directly “write a Word file.” It should help build a structured SOP object that the template layer can render reliably.
First, Build a Map
Section titled “First, Build a Map”This project is best understood as “knowledge ingestion -> retrieval -> structured generation -> template export”:
flowchart LR A["PDF / Word / PPT policy materials"] --> B["Document parsing and knowledge extraction"] B --> C["Knowledge base / retrieval"] D["External support notes"] --> C C --> E["Generate SOP structure"] E --> F["Export with Word template"]So what this project really wants to solve is:
- When the user only provides an incident topic, how does the system automatically find policy materials, extract cases and checklists, and then write them out according to a template?
How Should We Narrow the Project Scope?
Section titled “How Should We Narrow the Project Scope?”A very solid starting point is usually:
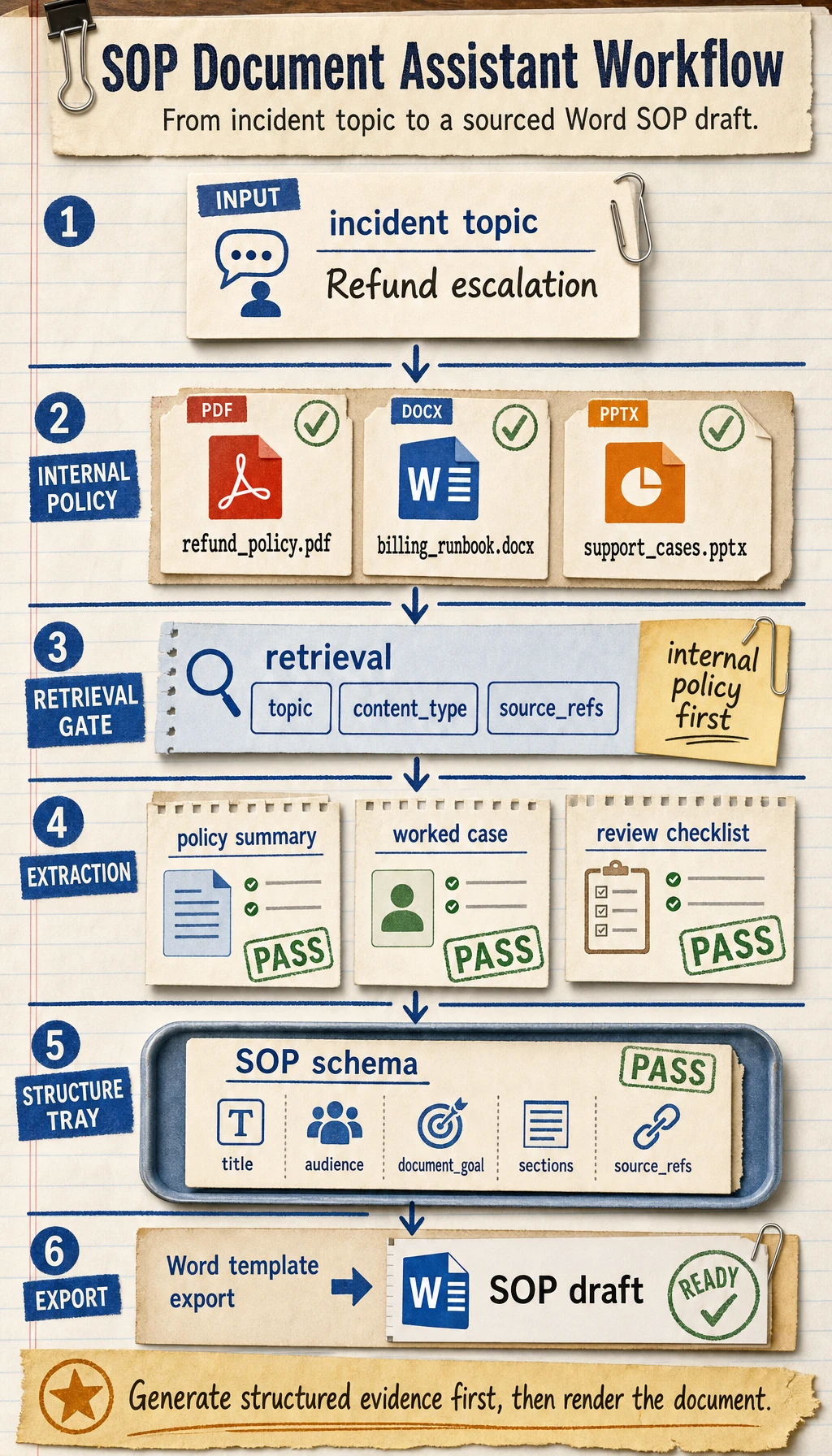
Build a knowledge base-driven support SOP assistant that takes an incident topic as input and automatically generates a Word draft containing policy summary, worked cases, review checklist, and source notes.
Why is this scope a good fit?
- The topic is clear
- The material format is clear
- Policy clauses, handled cases, and checklist items can be extracted from documents
- The Word output target is explicit
It is not recommended to start with:
- All departments
- Every policy area at once
- Automatically generating Word + PPT + Slack replies + approval tickets
That will easily distract from the main project line.
A Better Analogy for Beginners
Section titled “A Better Analogy for Beginners”You can think of this system as:
- An operations analyst that first reads policy materials, then organizes a handoff outline, and finally drafts the SOP for you
It does not write blindly out of thin air. Instead, it:
- First checks internal policies
- Then supplements with external support notes when needed
- Then selects policy clauses, handled cases, and checklist items from the materials
- Finally writes them into an SOP document in a fixed format
This analogy matters, because it helps beginners avoid thinking of the project as:
- “Just ask the model to write a Word document directly”
What Does the Minimum System Loop Look Like?
Section titled “What Does the Minimum System Loop Look Like?”- Ingest documents
- Parse body text, headings, tables, and decision rules
- User enters an incident topic
- The system retrieves internal knowledge chunks
- Supplement with external support notes if needed
- Generate a structured SOP object
- Export Word via a template
As long as these 7 steps run smoothly, the project already feels very close to a real product.
Let’s First Run a Minimal Workflow Example
Section titled “Let’s First Run a Minimal Workflow Example”knowledge_base = [ { "topic": "Refund escalation", "content_type": "policy", "text": "Escalate refund requests when eligibility or payment status is unclear.", }, { "topic": "Refund escalation", "content_type": "case", "text": "A card-paid order older than 7 days should go to billing review before promising a refund.", }, { "topic": "Refund escalation", "content_type": "checklist", "text": "Check order age, payment status, usage evidence, and previous support notes.", },]
def retrieve_internal(topic): return [item for item in knowledge_base if item["topic"] == topic]
def retrieve_external(topic): # Minimal simulation only return [{"topic": topic, "content_type": "note", "text": f"External supplement: recent support-process notes for {topic}."}]
def build_sop_document(topic): internal = retrieve_internal(topic) external = retrieve_external(topic) all_items = internal + external return { "title": topic, "policies": [x["text"] for x in all_items if x["content_type"] == "policy"], "cases": [x["text"] for x in all_items if x["content_type"] == "case"], "checklists": [x["text"] for x in all_items if x["content_type"] == "checklist"], "notes": [x["text"] for x in all_items if x["content_type"] == "note"], }
print(build_sop_document("Refund escalation"))Expected output:
{'title': 'Refund escalation', 'policies': ['Escalate refund requests when eligibility or payment status is unclear.'], 'cases': ['A card-paid order older than 7 days should go to billing review before promising a refund.'], 'checklists': ['Check order age, payment status, usage evidence, and previous support notes.'], 'notes': ['External supplement: recent support-process notes for Refund escalation.']}What Is the Most Important Value of This Example?
Section titled “What Is the Most Important Value of This Example?”It shows that the real value of this system is not just that it can:
- Retrieve
But that it can reorganize what it retrieved into:
- The section structure needed by an SOP document
Add a Quick Structure Check
Section titled “Add a Quick Structure Check”Before exporting Word, check whether each required slot has content. This prevents a template renderer from producing a beautiful but empty document.
sop_doc = build_sop_document("Refund escalation")required_slots = ["policies", "cases", "checklists", "notes"]
for slot in required_slots: count = len(sop_doc[slot]) print(f"{slot}: {count} item(s)", "OK" if count else "CHECK")Expected output:
policies: 1 item(s) OKcases: 1 item(s) OKchecklists: 1 item(s) OKnotes: 1 item(s) OKA System Layering Diagram That Looks More Like a Real Project
Section titled “A System Layering Diagram That Looks More Like a Real Project”When beginners build this kind of project, the easiest mistake is mixing “knowledge base, retrieval, generation, and export” together.
A safer approach is to separate the layers first:
flowchart TD A["Document ingestion layer"] --> B["Knowledge processing layer"] B --> C["Retrieval layer"] C --> D["SOP structure generation layer"] D --> E["Template export layer"]You can simply understand it as:
- Ingestion layer: read materials in
- Processing layer: turn materials into knowledge chunks
- Retrieval layer: find relevant policies and cases
- Generation layer: reorganize materials into an SOP document structure
- Export layer: turn the structure into Word
What Capabilities Does This Project Need Most?
Section titled “What Capabilities Does This Project Need Most?”Viewed by system layers, the core capabilities are:
Document Parsing
Section titled “Document Parsing”- PDF / DOCX / PPTX reading
- OCR for scanned documents
- Heading hierarchy, tables, and decision-rule recognition
Related courses:
- 8.3.8 Document Parsing and Knowledge Extraction
- 8.1.3 Document Processing
- 10.5.4 OCR Text Recognition
Knowledge Base and Retrieval
Section titled “Knowledge Base and Retrieval”- Chunking
- Metadata
- Topic retrieval
- Policy and case recall
Related courses:
Structured Output and Template Generation
Section titled “Structured Output and Template Generation”- Generate an outline first
- Then generate policy summary / worked cases / review checklist
- Then export Word using a template
Related courses:
Tool Calling and Workflows
Section titled “Tool Calling and Workflows”- Internal knowledge base retrieval
- External support-note supplementation
- Template rendering
- File export
Related courses:
- 8.3.4 Function Calling Practice
- 8.3.6 Dialogue Systems and Multi-Turn Management
- 9.2.5 Plan-and-Execute
Why Not Let the Model Directly Generate a Word File?
Section titled “Why Not Let the Model Directly Generate a Word File?”Direct generation looks fast in a demo, but it makes the system hard to debug. When the final document is wrong, you cannot easily tell whether the problem came from:
- The document parser
- The retriever
- The prompt
- The output schema
- The Word template
The better project architecture is:
Each intermediate result is inspectable. That is what makes the system product-like instead of just a prompt demo.
What Should the Minimal Fixed-Format SOP Schema Look Like?
Section titled “What Should the Minimal Fixed-Format SOP Schema Look Like?”The schema does not need to be complicated at first. The important point is that it should describe “what the SOP document should look like.”
For example:
sop_schema = { "title": "SOP Name", "audience": "Support Team", "document_goal": ["Goal 1", "Goal 2"], "sections": [ {"type": "policy", "heading": "Policy Summary", "items": []}, {"type": "case", "heading": "Worked Cases", "items": []}, {"type": "checklist", "heading": "Review Checklist", "items": []}, ], "source_refs": [{"doc_id": "policy_001", "page_or_slide": 3}],}This schema gives every layer a clear contract:
- Retrieval knows what evidence to search for
- Generation knows what structure to fill
- Template rendering knows where to place each block
- Evaluation knows what to check
How Should Internal and External Materials Be Combined?
Section titled “How Should Internal and External Materials Be Combined?”For SOP generation, internal materials should decide the main document skeleton. External materials can fill gaps, but they should not override company policy.
| Content need | Priority |
|---|---|
| Eligibility rules | Internal policies first |
| Escalation cases | Internal runbooks first |
| Recent exceptions or support-process notes | External notes as supplement |
| Internal gaps | External notes may help draft questions or reminders |
A simple rule is:
- Internal policies define the skeleton
- External notes only supplement missing background or recent operational context
This is especially important in compliance-sensitive workflows.
A More Complete Project Workflow
Section titled “A More Complete Project Workflow”After the minimal loop works, the whole workflow can become:
def generate_sop_document(topic): parsed_docs = load_parsed_documents() internal_hits = retrieve_internal(parsed_docs, topic) external_hits = retrieve_external(topic) selected = merge_and_rank(internal_hits, external_hits) structured = build_sop_schema(topic, selected) return export_word(structured)This function hides many implementation details, but the project boundary is clear:
- Inputs: topic and document library
- Middle products: parsed chunks, retrieval results, structured schema
- Output: Word SOP document
Read the Production Line Diagram
Section titled “Read the Production Line Diagram”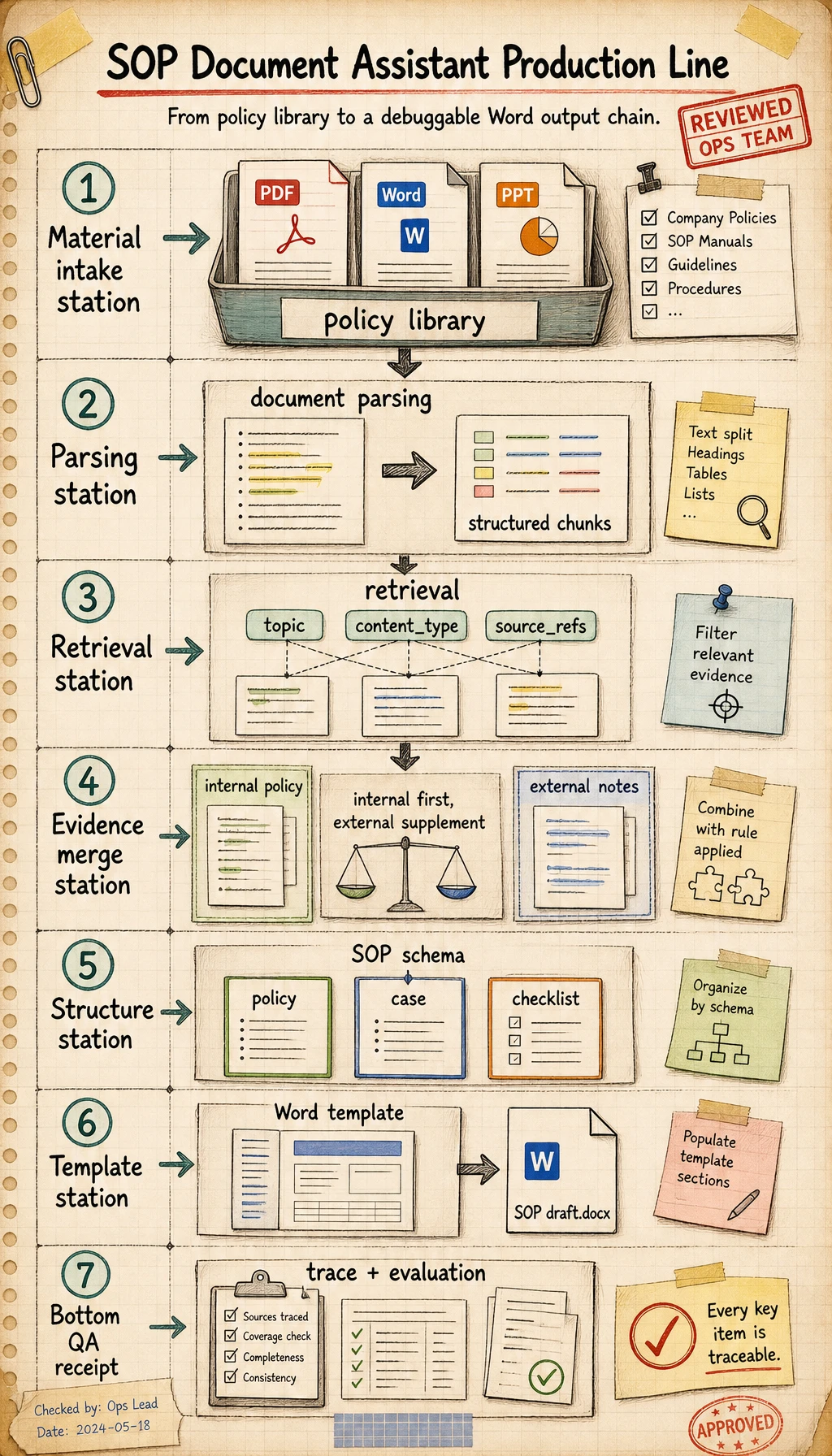
Read this diagram like a production line: materials are ingested, parsed into knowledge chunks, retrieved by topic and content type, converted into an SOP schema, and then rendered into Word. If any layer has no intermediate output, debugging the next layer becomes very difficult.
How Should This Project Be Evaluated?
Section titled “How Should This Project Be Evaluated?”Do not evaluate it only by asking whether the final Word file “looks good.” Check the full chain:
- Is retrieval correct?
- Are policy, case, and checklist items extracted correctly?
- Does the generated structure match the template?
- Can source references trace back to original materials?
- Can the system handle missing or conflicting evidence?
An evaluation table can look like this:
| Dimension | Checkpoint |
|---|---|
| Retrieval quality | Relevant policy and case materials are found |
| Structural correctness | Policy summary, worked cases, and checklist items are placed correctly |
| Citation traceability | Each important item has a source reference |
| Template quality | Word output has stable headings, tables, and formatting |
| Failure handling | Missing evidence produces a clear follow-up question or warning |
Suggested Version Roadmap
Section titled “Suggested Version Roadmap”Build this project in versions:
| Version | Goal |
|---|---|
| V0 | Manual list of policy chunks plus a fixed SOP schema |
| V1 | Local PDF / Word / PPT parsing |
| V2 | Vector retrieval with metadata filters |
| V3 | External support-note supplementation |
| V4 | Word template export |
| V5 | Evaluation set, failure log, and source trace view |
This is easier than trying to build a fully automated operations-document Agent from the start.
A Portfolio-Quality Demo Should Show These Things
Section titled “A Portfolio-Quality Demo Should Show These Things”If you want this project to feel professional, show:
- The input topic
- Retrieved internal policy chunks
- External supplement notes, if used
- How the final SOP structure was formed
- The exported Word file
- A small evaluation table
This proves not only that the model can generate text, but also that you can build a reliable document-generation workflow.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Project Scope
- incident topic → policy retrieval → SOP schema → Word export
- Intermediate Outputs
- parsed chunks, retrieval hits, structured schema, template payload
- Source Trace
- source_refs for policies, cases, checklist items, and external notes
- Evaluation Gate
- retrieval, structure, citation, template, and failure handling checks
- Expected Output
- SOP draft plus evidence that each layer can be inspected
Common Pitfalls
Section titled “Common Pitfalls”| Pitfall | Why it hurts | Better approach |
|---|---|---|
| Directly asking the model to write the whole document | Hard to trace errors | Generate a structured SOP object first |
| Ignoring source references | Final output cannot be trusted | Keep source_refs with each important item |
| Treating external notes as official policy | Can create incorrect guidance | Make internal policy higher priority |
| Designing the template before the schema | Formatting and content drift apart | Define the schema first, then map it to the template |
| Evaluating only the final Word file | Hides retrieval and parsing errors | Evaluate each layer separately |
Related Project Variants
Section titled “Related Project Variants”After finishing this baseline, you can adapt the same architecture to:
- Customer support handoff notes
- Compliance review summaries
- Incident response runbooks
- Internal onboarding playbooks
- Product release checklist documents
The domain changes, but the core pattern stays the same:
Key Takeaways
Section titled “Key Takeaways”- The core of this project is the complete pipeline of “document knowledge -> structured SOP document -> template export”
- Internal policies should define the main skeleton, while external notes only supplement missing context
- The model should generate structured data first, not directly manipulate Word formatting
- A good project demo shows intermediate evidence, not only the final document
Check reasoning and explanation
- The most important thing in this project is not “document output,” but the whole chain of “document knowledge -> structured SOP document.”
- Internal materials decide the reliable skeleton. External materials can supplement, but should not override official sources.
- A strong portfolio demo should include retrieval evidence, schema output, exported Word file, and evaluation results.