6.8.1 Deep Learning Projects Roadmap: Train, Inspect, Package
This chapter is the exit point of Chapter 6. A deep learning project is not just a training script. It needs data evidence, shape checks, loss logs, prediction samples, failure cases, and a README.
Look at the Project Loop First
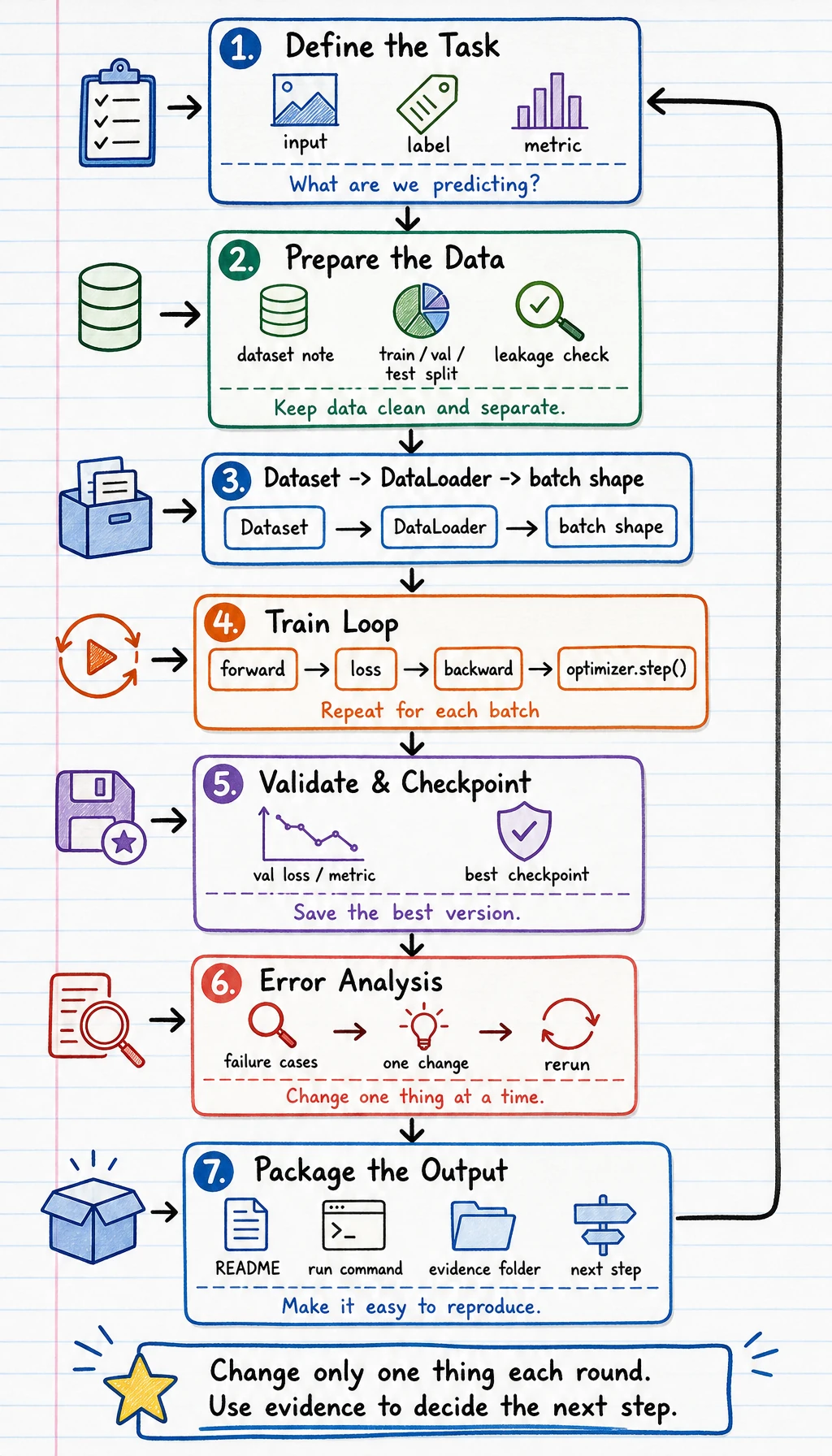
Section titled “Look at the Project Loop First”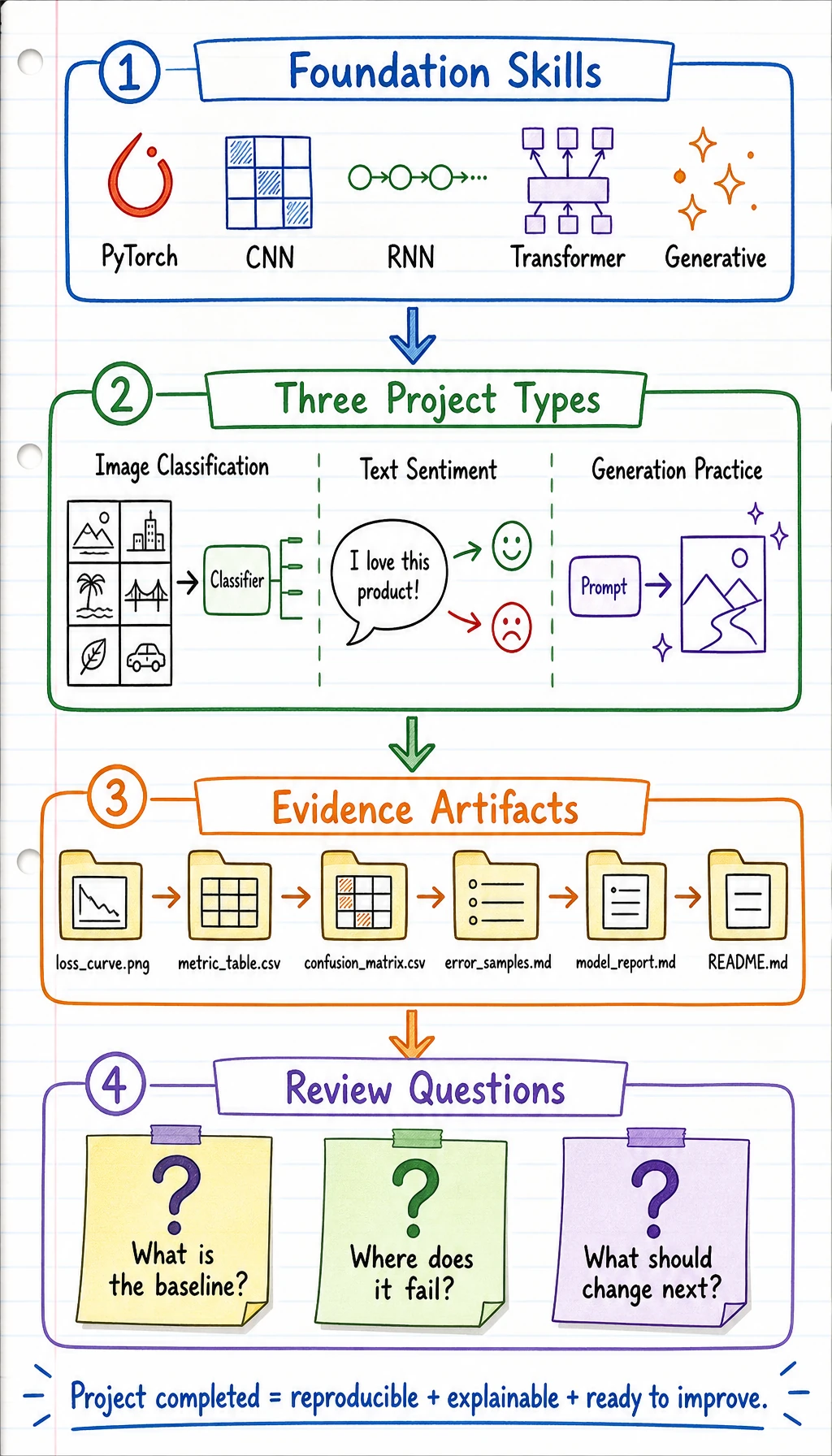
Keep One Evidence Record
Section titled “Keep One Evidence Record”Create dl_project_evidence_first_loop.py.
evidence = { "task": "image classification", "baseline_accuracy": 0.71, "current_accuracy": 0.82, "failure_case_count": 5, "next_step": "inspect confused classes and add augmentation",}
print("task:", evidence["task"])print("improvement:", round(evidence["current_accuracy"] - evidence["baseline_accuracy"], 3))print("failure_case_count:", evidence["failure_case_count"])print("next_step:", evidence["next_step"])Expected output:
task: image classificationimprovement: 0.11failure_case_count: 5next_step: inspect confused classes and add augmentation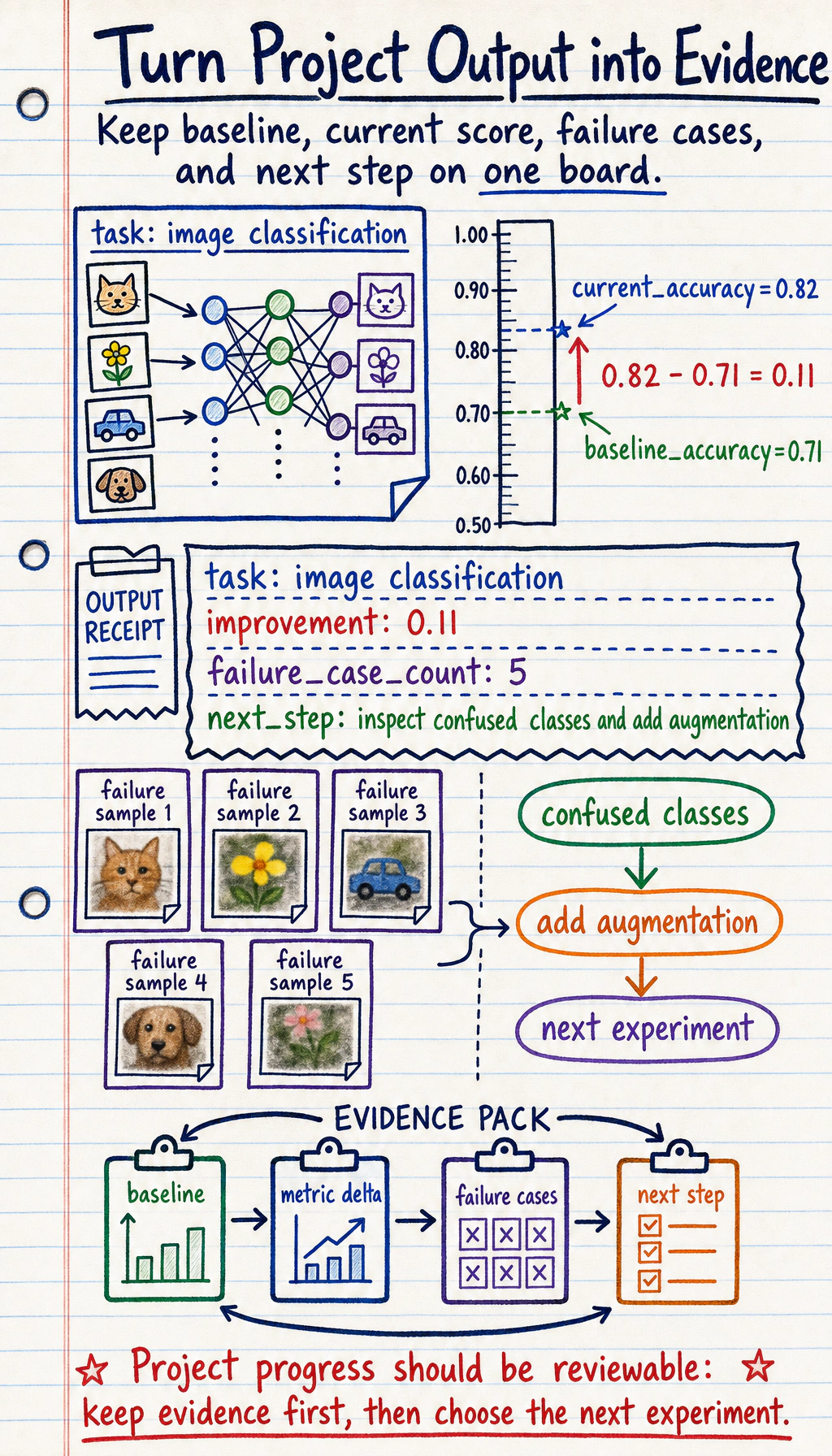
This is the project habit: every improvement needs a baseline, metric, failure evidence, and next step.
Evidence to Keep
Section titled “Evidence to Keep”Package the project like another learner will rerun and review it:
- Run Command
- exact command that reproduces the result
- Dataset Note
- where data came from and how it was split
- Baseline
- first simple score or behavior
- Current Result
- current metric plus success samples
- Failure Cases
- at least three wrong or weak examples
- Next Step
- one change justified by the failures
This keeps the project from becoming a one-time demo. A good Chapter 6 project should be rerunnable, inspectable, and improvable.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to deliver |
|---|---|---|
| 1 | 6.8.2 Image Classification | dataset, CNN/transfer baseline, prediction samples |
| 2 | 6.8.3 Sentiment Analysis | text pipeline, training log, error examples |
| 3 | 6.8.4 Generative Practice | generated samples and review notes |
| 4 | 6.8.5 Hands-on DL Workshop | one reproducible PyTorch evidence pack |
Project Deliverable Standards
Section titled “Project Deliverable Standards”Keep at least these files for one project: README.md, run command, dataset note, model summary, loss curve or log, metric table, prediction samples, failure cases, and next-step plan.
Failure Check
Section titled “Failure Check”Before calling a project finished, answer:
- Baseline
- what simple method did this beat?
- Metric
- what number proves improvement?
- Sample Success
- which predictions look correct?
- Sample Failure
- which predictions still fail?
- Debug Next
- what would you change first, and why?
If you cannot show failures, the project is still a demo, not a learning artifact.
Pass Check
Section titled “Pass Check”You pass this roadmap when another learner can run your project, inspect the training evidence, see both success and failure samples, and understand what you would improve next.
Check reasoning and explanation
- A passing answer connects tensors, model layers, loss,
backward(), and optimizer updates into one training loop. - The evidence should include a runnable mini experiment, tensor-shape checks, and a loss or validation curve you can explain.
- A good self-check names one failure mode such as shape mismatch, no loss decrease, overfitting, data leakage, or using Attention/Transformer words without explaining the data flow.