9.3.8 Code Generation and Execution Agent
Learning Objectives
Section titled “Learning Objectives”- Understand the fundamental difference between a code Agent and ordinary code generation
- Understand the minimal working loop of a code Agent
- Use a runnable example to understand why “read-edit-run-verify” must form a loop
- Understand why sandboxing, tests, and rollback are critical in a code Agent
What is the real difference between a code Agent and “letting the model write code”?
Section titled “What is the real difference between a code Agent and “letting the model write code”?”Ordinary code generation is more like a one-time output
Section titled “Ordinary code generation is more like a one-time output”For example:
- “Help me write quicksort”
After the model outputs a piece of code, the task is usually over.
A code Agent is more like working in a real repository
Section titled “A code Agent is more like working in a real repository”The tasks it faces are more likely to be:
- fixing a bug
- adding tests for a function
- changing configuration
- seeing an error and then fixing it again
In other words, it must handle:
- context
- version state
- runtime feedback
- error recovery
An analogy: writing a sample answer vs. actually fixing a problem in a project
Section titled “An analogy: writing a sample answer vs. actually fixing a problem in a project”“Generating code” is like solving a whiteboard interview problem. A “code Agent” is more like actually entering a repository and doing the work:
- read the project first
- find the files
- make one change
- run tests
- inspect the errors
- fix it again
These are completely different levels of difficulty.
What is the minimal closed loop of a code Agent?
Section titled “What is the minimal closed loop of a code Agent?”Read: read the context first
Section titled “Read: read the context first”It usually needs to know:
- where the relevant files are
- how the current function is written
- how the tests are organized
Plan: form a modification plan
Section titled “Plan: form a modification plan”For example:
- change the implementation
- add tests
- adjust configuration
Act: actually make the changes
Section titled “Act: actually make the changes”This is the part most people immediately think of as “writing code.”
Verify: run verification
Section titled “Verify: run verification”For example:
- run unit tests
- run scripts
- inspect output
Repair: keep fixing based on feedback
Section titled “Repair: keep fixing based on feedback”This is also one of the biggest differences between a code Agent and a normal generator:
- it reads execution feedback and then enters the next round
First, run a minimal “code Agent loop” example
Section titled “First, run a minimal “code Agent loop” example”The example below does not really modify files, but it fully simulates a very important loop:
- detect a bug in a function implementation
- generate a patch function
- run tests
- if the tests pass, accept the change
def buggy_normalize_status(status): # Wrong: returns raw status, so spacing and case stay inconsistent return status
def generate_patch(): def fixed_normalize_status(status): return status.strip().lower()
return fixed_normalize_status
def run_tests(fn): cases = [ ((" OPEN ",), "open"), (("Pending ",), "pending"), ]
failures = [] for args, expected in cases: actual = fn(*args) if actual != expected: failures.append( { "args": args, "expected": expected, "actual": actual, } ) return failures
current_impl = buggy_normalize_statusfailures = run_tests(current_impl)print("before patch failures:", failures)
if failures: candidate_impl = generate_patch() candidate_failures = run_tests(candidate_impl) print("after patch failures:", candidate_failures)
if not candidate_failures: current_impl = candidate_impl print("patch accepted")Expected output:
before patch failures: [{'args': (' OPEN ',), 'expected': 'open', 'actual': ' OPEN '}, {'args': ('Pending ',), 'expected': 'pending', 'actual': 'Pending '}]after patch failures: []patch acceptedWhat does this code correspond to in the real world?
Section titled “What does this code correspond to in the real world?”It corresponds to the most important closed loop in a code Agent:
- it does not just produce code
- it must make the code pass verification
Once this step is missing, the system can easily end up:
- writing code that looks reasonable
- but cannot run at all
Why is run_tests more important than generate_patch?
Section titled “Why is run_tests more important than generate_patch?”Because what pulls the system back to reality is often not generation ability, but verification ability.
Without verification, a code Agent can easily remain stuck at:
- looks right
Why is this an Agent and not just a “function replacement”?
Section titled “Why is this an Agent and not just a “function replacement”?”Because it has:
- current state
- candidate actions
- external feedback
- decision updates
That is already a minimal agentic loop.
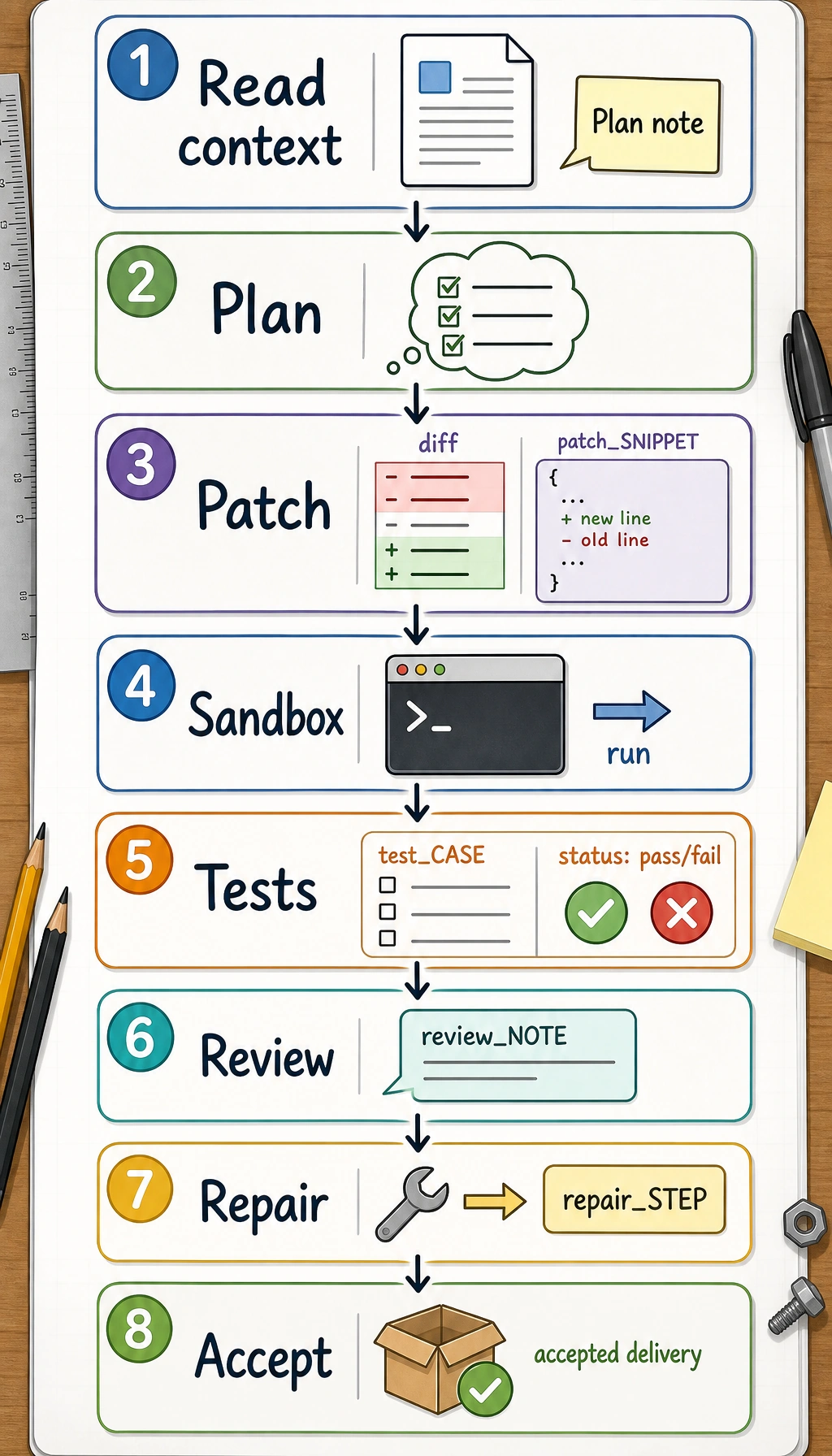
What other key steps does a real code Agent include?
Section titled “What other key steps does a real code Agent include?”File location and reading
Section titled “File location and reading”In a real repository, the first problem is:
- which file to change
- which part of the implementation to inspect
- which tests are related
Patch-based changes instead of rewriting the whole file
Section titled “Patch-based changes instead of rewriting the whole file”A more stable approach is usually:
- generate a patch
- or a local diff
Because this makes it:
- smaller in scope
- easier to review
- easier to roll back
Execution environment isolation
Section titled “Execution environment isolation”A code Agent often needs to:
- run code
- run tests
- read and write files
This involves:
- sandboxing
- permission boundaries
- timeouts
Rollback and retry
Section titled “Rollback and retry”If a candidate patch fails, the system should ideally be able to:
- keep the original version
- discard the failed changes
- try a different fix
Why does a code Agent depend so heavily on verification?
Section titled “Why does a code Agent depend so heavily on verification?”Because code tasks often have objective feedback
Section titled “Because code tasks often have objective feedback”Compared with pure text tasks, one huge advantage of code tasks is:
- in many cases, you can get a clear result by running them
For example:
- whether tests pass
- whether the program crashes
- whether the output matches expectations
This makes code Agents especially suitable for trial-and-error iteration
Section titled “This makes code Agents especially suitable for trial-and-error iteration”They can:
- make one version first
- run feedback
- fix based on failures
That is also why code Agents are often one of the easiest types of Agent systems to build a strong closed loop around.
But don’t be overly optimistic
Section titled “But don’t be overly optimistic”Because “tests pass” does not necessarily mean:
- there are no regressions
- the logic is truly complete
So verification is powerful, but not magical.
The most common failure points of code Agents
Section titled “The most common failure points of code Agents”Changing code without understanding the context
Section titled “Changing code without understanding the context”This can lead to:
- editing the wrong file
- breaking interface contracts
- conflicting with the existing style
Fixing only the surface error without understanding the root cause
Section titled “Fixing only the surface error without understanding the root cause”Typical signs include:
- adding an
if - suppressing an exception
- making the test “just pass”
But the real problem is still there.
Inadequate verification
Section titled “Inadequate verification”For example, only running a single happy path, without covering:
- edge cases
- regression risk
- related modules
What should a code Agent protect most in engineering practice?
Section titled “What should a code Agent protect most in engineering practice?”Rollback capability
Section titled “Rollback capability”Any automatic change should:
- be reversible
Small-step commits
Section titled “Small-step commits”The smaller the patch, the easier it is to:
- review
- locate problems
- do the next round of fixes
Clear boundaries
Section titled “Clear boundaries”For example:
- only modify a specified directory
- only run certain commands
- high-risk commands must require manual confirmation
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Tool Contract
- name, description, input schema, output schema
- Permission
- what the tool is allowed to read or change
- Call Trace
- arguments, result, error, retry or fallback
- Failure Check
- wrong tool, bad arguments, unsafe action, or missing observation
- Safety Action
- validate, confirm, sandbox, rate-limit, or rollback
Summary
Section titled “Summary”The most important thing in this section is not to understand a code Agent as “a model that can write code,” but to understand its real closed loop:
The core of a code Agent is to form a stable loop between reading, editing, running, verifying, and fixing again within the context of a real repository.
Once this loop is clear, you will also understand what is truly difficult about more complex systems such as:
- automatic bug fixing
- automatic test generation
- automatic refactoring
Exercises
Section titled “Exercises”- Replace
buggy_normalize_statusin the example with your own buggy function, then design a patch version. - Why is a code Agent more dependent on a “feedback loop” than ordinary code generation?
- Think about this: if there are no tests, what other verification methods can a code Agent rely on?
- Why are smaller patches usually more suitable for a code Agent?
Reference implementation and walkthrough
- A good replacement bug is small and testable, such as an off-by-one loop, a missing empty-input check, or a wrong sort key. The patch should change only the failing logic.
- A code Agent needs a feedback loop because code quality is judged by execution, tests, diffs, lint output, and review, not by fluent explanation alone.
- Without tests, it can still use linters, type checks, static analysis, sandbox runs, sample inputs, code review checklists, and manual reproduction steps.
- Smaller patches reduce blast radius, make review easier, preserve user changes, and make it clearer which change fixed the failure.