6.7.2 Hyperparameter Tuning Strategy
Learning Objectives
Section titled “Learning Objectives”- Tune in a stable order instead of changing everything at once.
- Run a small learning-rate sweep in PyTorch.
- Read validation loss, validation accuracy, and training stability together.
- Record experiment evidence in a reusable table.
- Decide when to tune learning rate, batch size, regularization, or early stopping.
Use the Route First
Section titled “Use the Route First”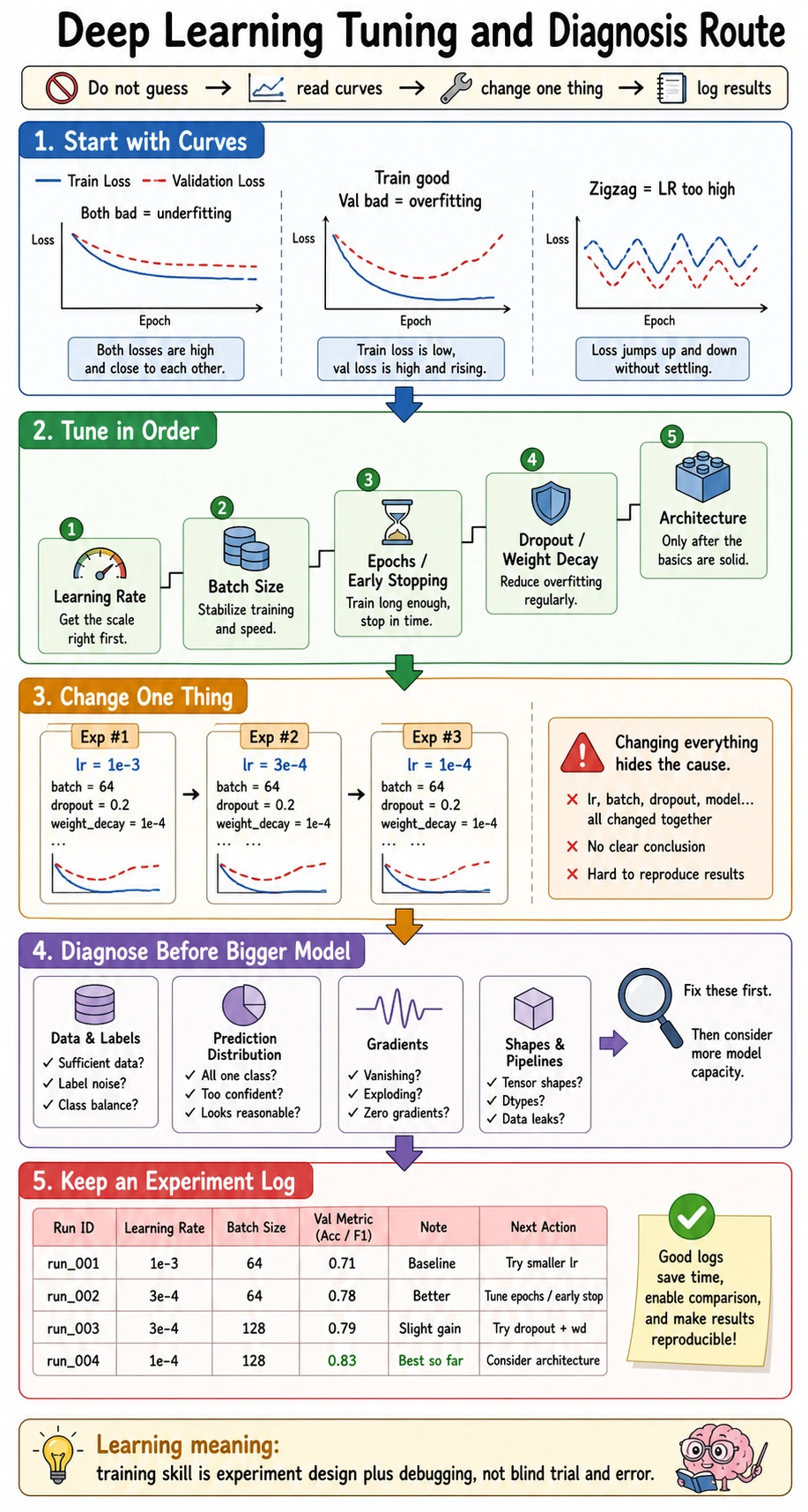
The practical order:
make training runtune learning ratecheck validationcontrol overfittingrefine locally
Do not start by tuning every knob. A useful tuning run should answer one question.
| Question | Parameter to try first | What to watch |
|---|---|---|
| Does the model learn at all? | learning rate | train loss trend |
| Is training unstable? | learning rate, gradient clipping, batch size | spikes or divergence |
| Is validation worse than training? | weight decay, dropout, augmentation, early stopping | generalization gap |
| Is training too slow? | batch size, model size, precision | time and memory |
| Is deployment too heavy? | architecture, pruning, quantization | latency and size |
Lab: Run a Learning-Rate Sweep
Section titled “Lab: Run a Learning-Rate Sweep”This toy classification task is small enough to run quickly, but it shows the workflow.
Create lr_sweep.py:
import torchfrom torch import nn
torch.manual_seed(11)
X = torch.randn(240, 2)y = ((X[:, 0] * 0.8 + X[:, 1] * -0.5) > 0).long()
train_x, val_x = X[:180], X[180:]train_y, val_y = y[:180], y[180:]
def run(lr): torch.manual_seed(123) model = nn.Sequential(nn.Linear(2, 8), nn.ReLU(), nn.Linear(8, 2)) opt = torch.optim.SGD(model.parameters(), lr=lr) loss_fn = nn.CrossEntropyLoss()
for _ in range(40): logits = model(train_x) loss = loss_fn(logits, train_y) opt.zero_grad() loss.backward() opt.step()
with torch.no_grad(): train_loss = loss_fn(model(train_x), train_y).item() val_logits = model(val_x) val_loss = loss_fn(val_logits, val_y).item() val_acc = (val_logits.argmax(dim=1) == val_y).float().mean().item()
return train_loss, val_loss, val_acc
results = []for lr in [1e-3, 1e-2, 1e-1, 1.0, 10.0]: train_loss, val_loss, val_acc = run(lr) results.append((lr, train_loss, val_loss, val_acc))
print("lr_sweep")for lr, train_loss, val_loss, val_acc in results: print( f"lr={lr:g} " f"train_loss={train_loss:.3f} " f"val_loss={val_loss:.3f} " f"val_acc={val_acc:.3f}" )
best = min(results, key=lambda row: row[2])print("best_lr:", best[0])Run it:
python lr_sweep.pyExpected output:
lr_sweeplr=0.001 train_loss=0.763 val_loss=0.733 val_acc=0.450lr=0.01 train_loss=0.675 val_loss=0.663 val_acc=0.533lr=0.1 train_loss=0.340 val_loss=0.373 val_acc=0.967lr=1 train_loss=0.053 val_loss=0.072 val_acc=0.983lr=10 train_loss=0.280 val_loss=0.291 val_acc=0.883best_lr: 1.0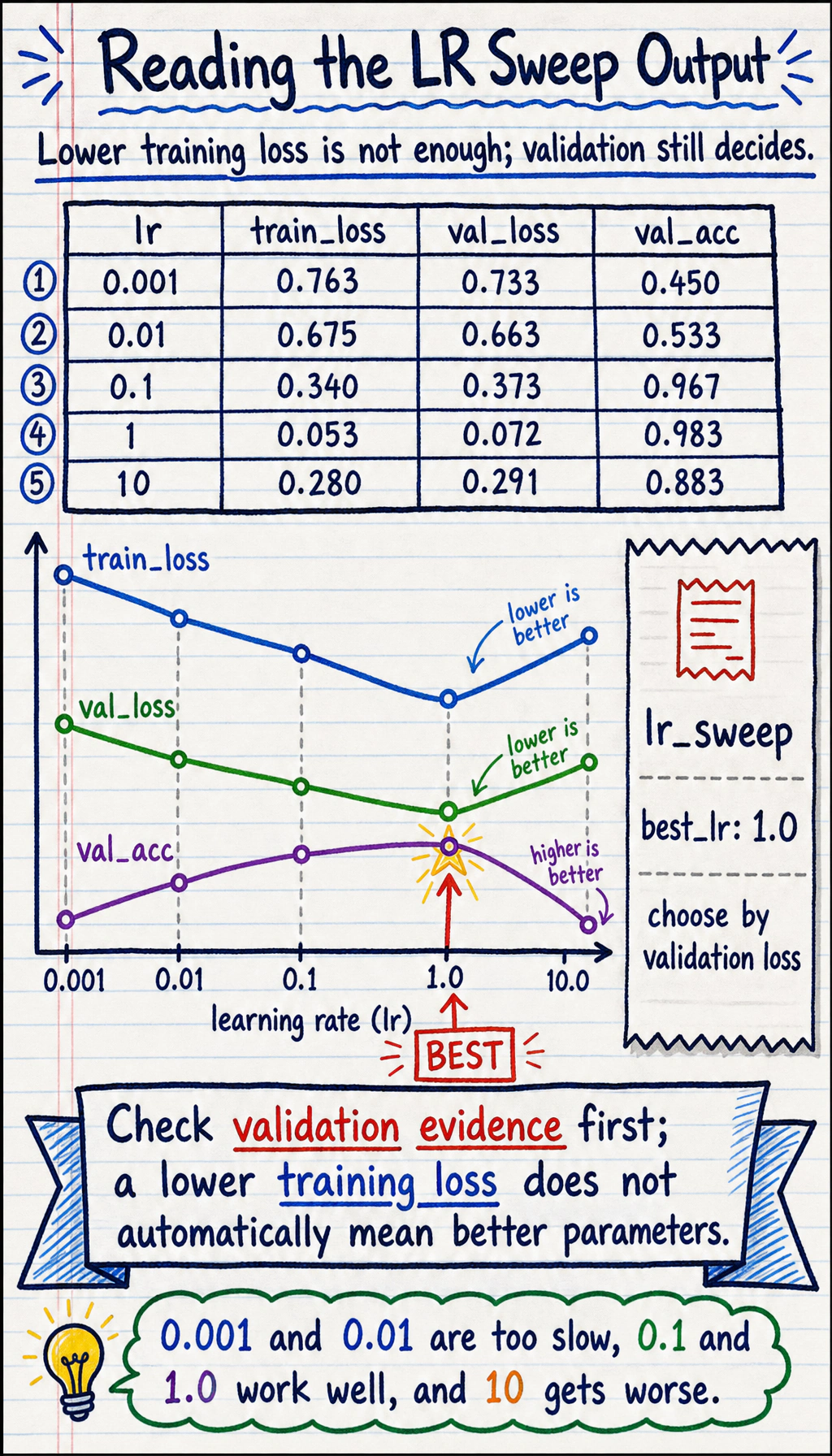
Read it carefully:
0.001and0.01are too slow for this budget.0.1and1.0learn well.10.0is worse even though it still trains, so “larger” is not automatically better.- The best choice is based on validation loss here, not training loss.
What to Tune Next
Section titled “What to Tune Next”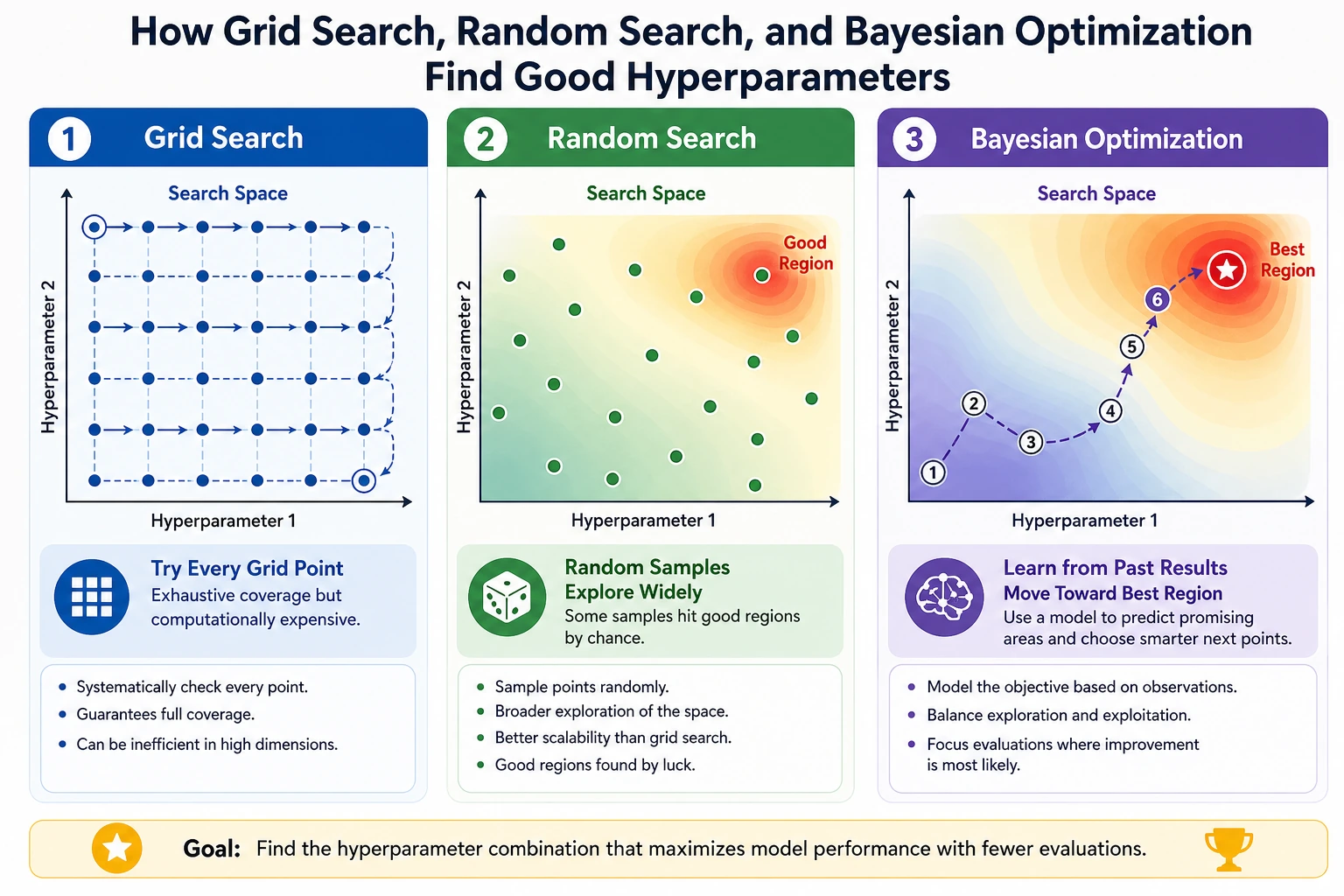
After a reasonable learning rate, tune in this order:
- Batch size: adjust memory use, speed, and gradient noise.
- Epochs and early stopping: stop when validation stops improving.
- Weight decay and dropout: reduce overfitting.
- Architecture size: change capacity only after the loop is stable.
- Optimizer details: tune betas, scheduler, warmup, or momentum when needed.
The rule:
global search first, local refinement laterA Minimal Experiment Log
Section titled “A Minimal Experiment Log”Use a log even for small projects.
| Group | Fields to record |
|---|---|
| Identity | experiment_id, code_version, data_version, seed |
| Hyperparameters | lr, batch_size, optimizer, weight_decay, dropout, epochs |
| Result | best_val_metric, train_time, decision |
Example decision text:
lr=1.0 gives the best validation loss in the quick sweep.Next: keep lr=1.0 fixed and compare batch_size=32 vs 64.Evidence to Keep
Section titled “Evidence to Keep”Keep one tuning decision card:
- Question
- which single variable was tested?
- Fixed
- data split, seed, model, optimizer family, training budget
- Changed
- learning rate values
- Selection Metric
- validation loss or validation accuracy
- Best Setting
- lr=1.0 in the quick sweep
- Next Experiment
- one local refinement, not many knobs at once
Diagnosis Patterns
Section titled “Diagnosis Patterns”| Pattern | Likely cause | Next experiment |
|---|---|---|
| train loss does not move | LR too low, model too small, bad labels | raise LR, inspect data, try larger model |
| train loss explodes | LR too high, gradients unstable | lower LR, add clipping |
| train good, validation poor | overfitting or leakage | add regularization, check split |
| validation improves then worsens | overfitting after best epoch | early stopping |
| results change a lot by seed | unstable training or small data | run 3 seeds and report mean/std |
Common Mistakes
Section titled “Common Mistakes”| Mistake | Fix |
|---|---|
| changing LR, batch size, optimizer, and model together | change one main variable per experiment |
| choosing by training metric | use validation metric for model selection |
| ignoring runtime | track time and memory, not only accuracy |
| trusting one lucky seed | repeat important runs with multiple seeds |
| tuning before data is clean | inspect labels, leakage, and preprocessing first |
Exercises
Section titled “Exercises”- Add
lr=0.3andlr=3.0to the sweep. Which is closer to the best region? - Change the training budget from
40steps to10steps. Does the best LR change? - Add a
seedcolumn by running each LR with two seeds. - Write a decision line for the next experiment after the LR sweep.
- Explain why tuning is easier when each experiment answers one question.
Reference implementation and walkthrough
lr=0.3may be near a useful high region;lr=3.0is likely too aggressive. The exact answer depends on validation loss and stability.- With only
10steps, a learning rate that starts fast may look best even if it later becomes unstable. Short budgets can bias the sweep. - A seed column reveals whether the result is stable or lucky. If two seeds disagree strongly, repeat before making a major decision.
- A good decision line names one next experiment, such as “refine around
lr=0.1with three seeds and 80 steps.” - One-question experiments are easier to interpret. If you change learning rate, model size, and data at once, you cannot tell which change mattered.
Key Takeaways
Section titled “Key Takeaways”- Tuning is controlled experiment design, not guessing.
- Learning rate is usually the first knob to test.
- Validation evidence should drive decisions.
- Logs make experiments reproducible and interpretable.
- Tune broad settings first, then refine locally.