8.2.1 Deployment Roadmap: Local Model, Service, Unified API
Deployment turns a model from a notebook experiment into a reusable capability. The application should call a stable interface, even when the model, provider, hardware, or cost policy changes.
See the Serving Decision First
Section titled “See the Serving Decision First”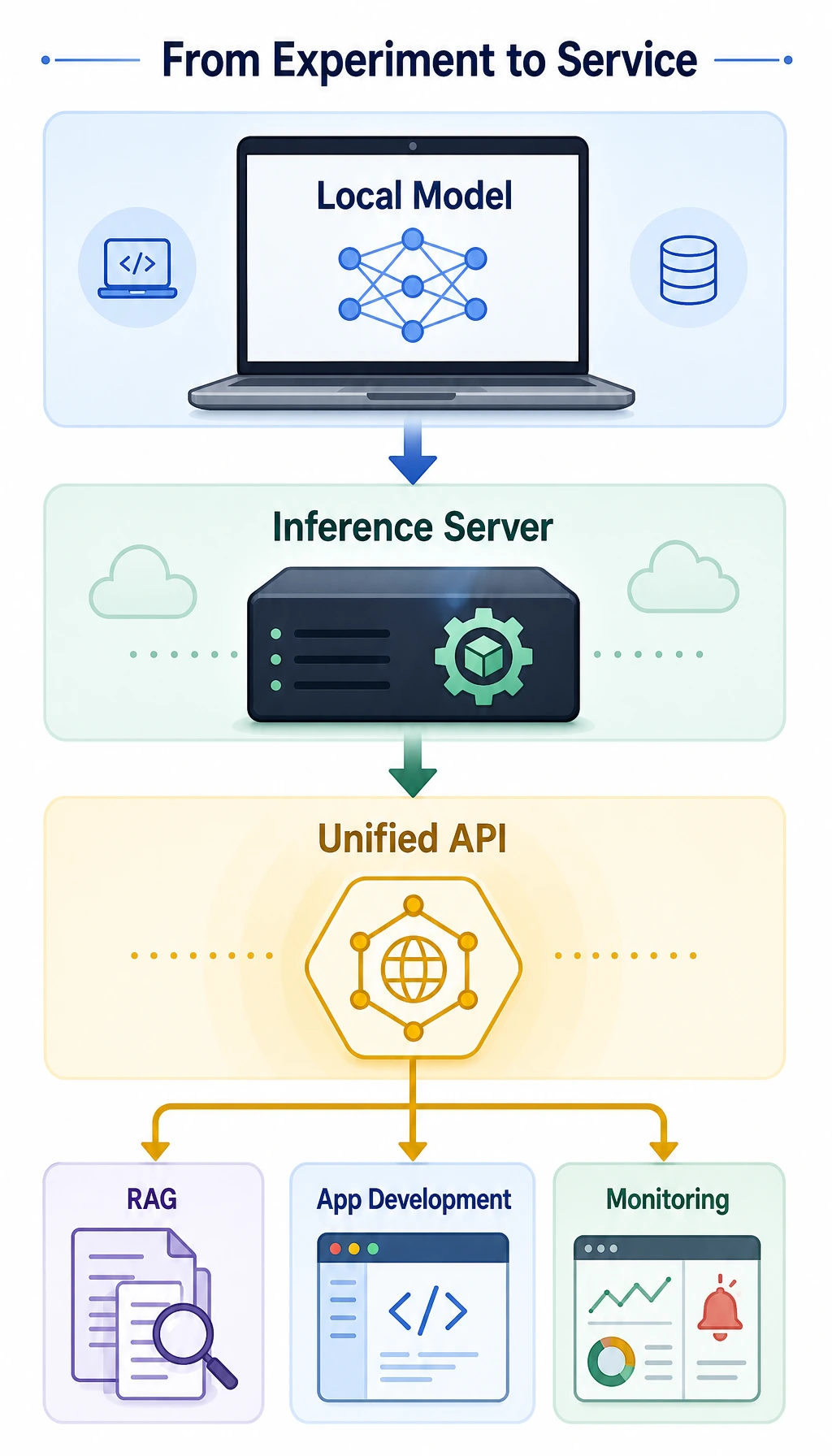
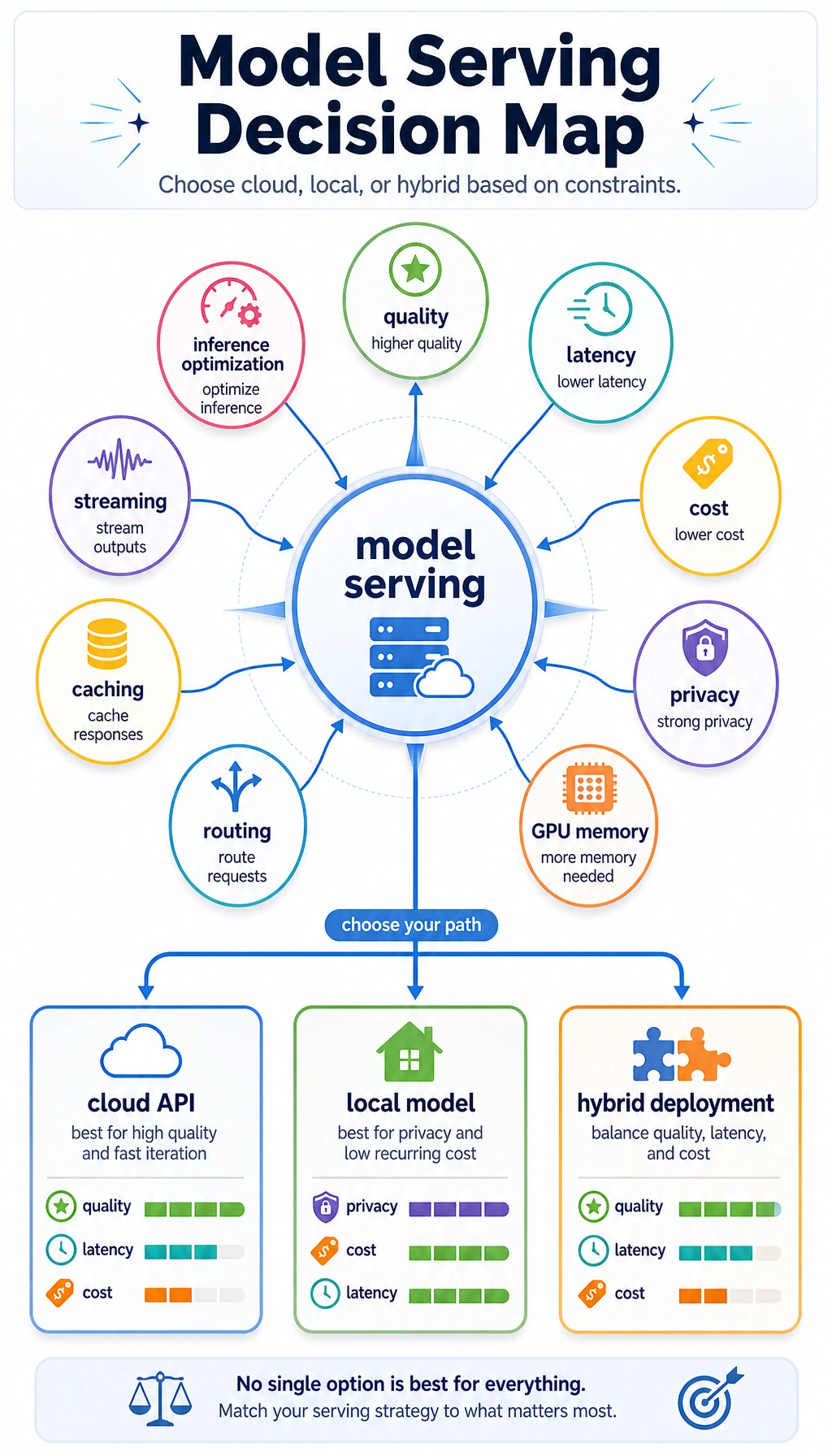

Deployment choices balance quality, latency, cost, privacy, and operational complexity. The strongest model is not always the model you should call.
Run a Model Route Check
Section titled “Run a Model Route Check”Use this as a mental model before setting up real serving tools. It turns deployment into an explicit routing decision.
request = { "privacy": "high", "latency_ms": 800, "quality_need": "medium", "budget": "low",}
if request["privacy"] == "high": route = "local model or private endpoint"elif request["quality_need"] == "high": route = "frontier cloud model"else: route = "small hosted model"
print("route:", route)print("contract:", "/v1/chat/completions")print("watch:", "latency, cost, errors")Expected output:
route: local model or private endpointcontract: /v1/chat/completionswatch: latency, cost, errorsThe route can change, but the application contract should stay stable.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | Local models | Load or call one local/private model and record limits |
| 2 | Inference servers | Expose model calls through a service endpoint |
| 3 | Unified API | Keep one application interface for multiple providers |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Runtime Choice
- local model, inference server, or unified API
- Request Contract
- endpoint, payload, output format, and error shape
- Latency Or Cost
- one measured or estimated number
- Failure Check
- timeout, memory pressure, model mismatch, or version drift
- Rollback Plan
- fallback model, retry policy, or traffic switch
Pass Check
Section titled “Pass Check”You pass this chapter when you can explain where the model runs, how the app calls it, what can fail, and what metrics you watch: latency, cost, errors, rate limits, and fallback behavior.
The exit mini project is a small model gateway note or script that routes one request to a chosen model endpoint and records the decision reason.
Check reasoning and explanation
- A passing answer traces the full path from query to chunks, retrieval scores, cited evidence, answer, and fallback behavior.
- The evidence should include retrieved passages, source metadata, a cited answer, and at least one empty-retrieval or wrong-retrieval case.
- A good self-check explains whether a failure came from chunking, retrieval, ranking, prompt assembly, missing sources, or unsupported generation.