5.2.1 Supervised Learning Roadmap: Learn From Labeled Examples
Supervised learning answers one question: when examples already have labels, how do we learn a model that predicts labels for new examples?
Look at the Model Choice Map First
Section titled “Look at the Model Choice Map First”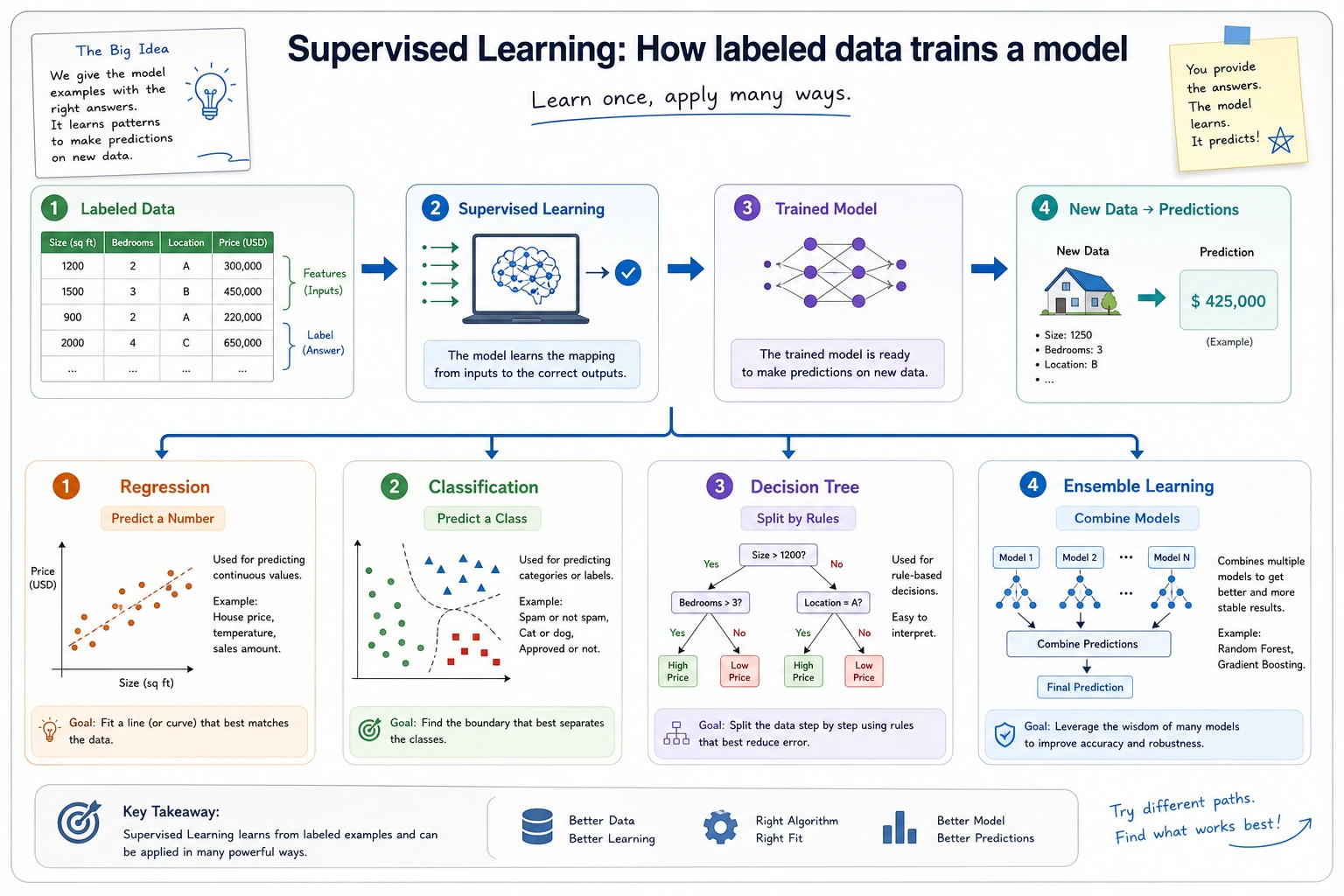
| Model family | First use |
|---|---|
| linear regression | predict a continuous number |
| logistic regression | classify with a simple probability model |
| decision tree | split data with readable rules |
| ensemble models | combine many models for stronger tabular baselines |
| SVM | learn a stable boundary with margin intuition |
Run One Regression Baseline
Section titled “Run One Regression Baseline”Create supervised_first_loop.py and run it after installing scikit-learn.
from sklearn.datasets import load_diabetesfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import r2_scorefrom sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = LinearRegression().fit(X_train, y_train)predictions = model.predict(X_test)
print("task: regression")print("r2:", round(r2_score(y_test, predictions), 3))print("first_prediction:", round(predictions[0], 1))Expected output:
task: regressionr2: 0.485first_prediction: 137.9The score is not perfect, and that is useful. A baseline tells you where later models or feature work must improve.
Learn in This Order
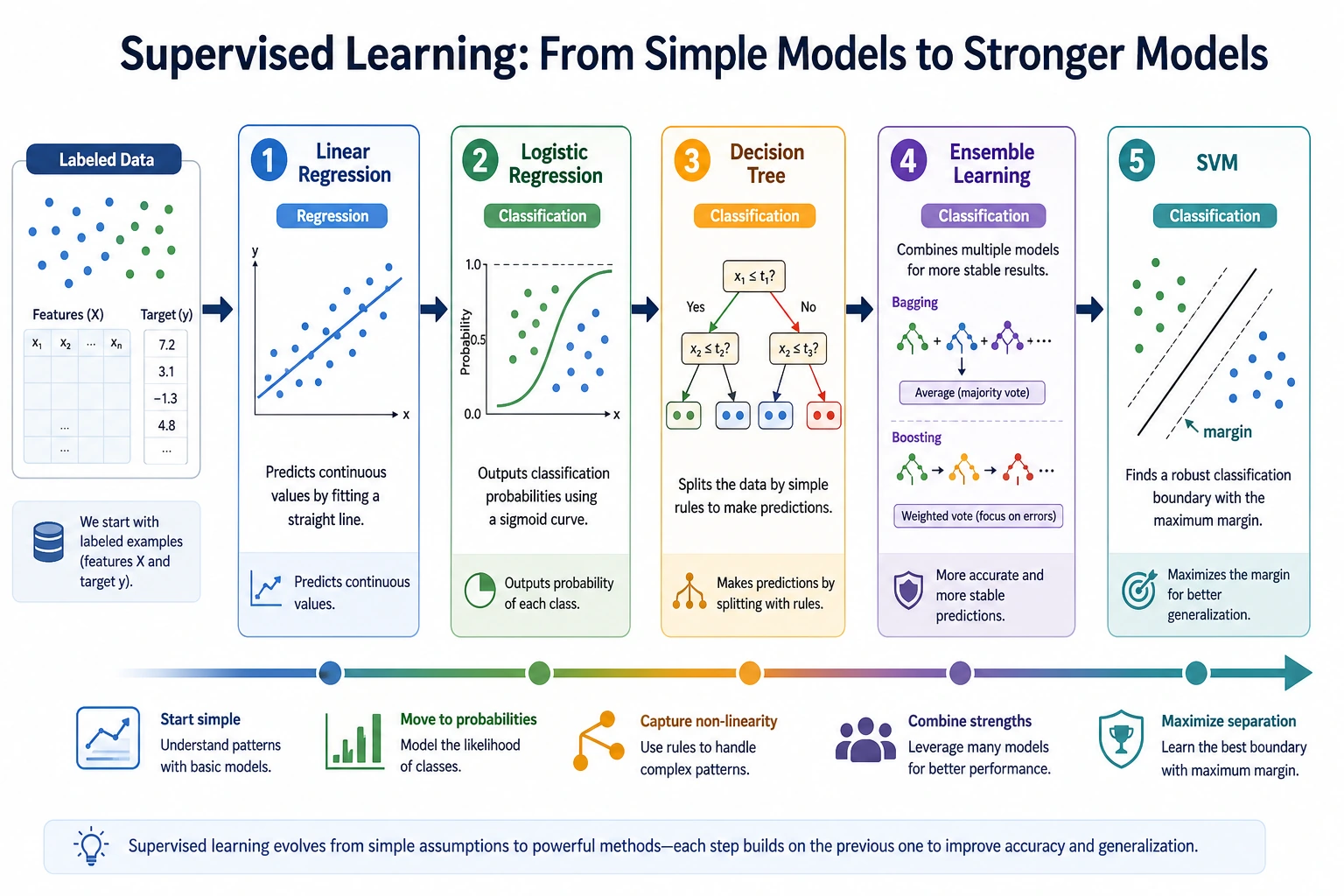
Section titled “Learn in This Order”| Order | Read | What to compare |
|---|---|---|
| 1 | 5.2.2 Linear Regression | simple numeric prediction |
| 2 | 5.2.3 Logistic Regression | classification probability |
| 3 | 5.2.4 Decision Trees | rules, nonlinearity, overfitting |
| 4 | 5.2.5 Ensemble Learning | bagging, boosting, stronger tabular models |
| 5 | 5.2.6 Support Vector Machines | margin, boundary, classic classifier intuition |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Task
- regression or classification problem with target definition
- Model
- linear/logistic/tree/ensemble/SVM configuration and train/test split
- Metric
- regression error, accuracy/F1, threshold curve, or confusion matrix
- Failure Check
- overfitting, underfitting, feature scaling, threshold choice, or class imbalance
- Expected Output
- model result plus error samples or residual review
Pass Check
Section titled “Pass Check”You pass this roadmap when you can decide whether a labeled task is regression or classification, run one baseline, and explain one reason the model may fail.
Check reasoning and explanation
- If the label is a continuous value, start with regression. If it is a class, start with classification.
- The baseline can be a simple linear/logistic model or a dummy rule. Its purpose is to define the score a more complex model must beat.
- Common failure reasons include weak features, target leakage, class imbalance, poor scaling, overfitting, and choosing a metric that does not match the real goal.