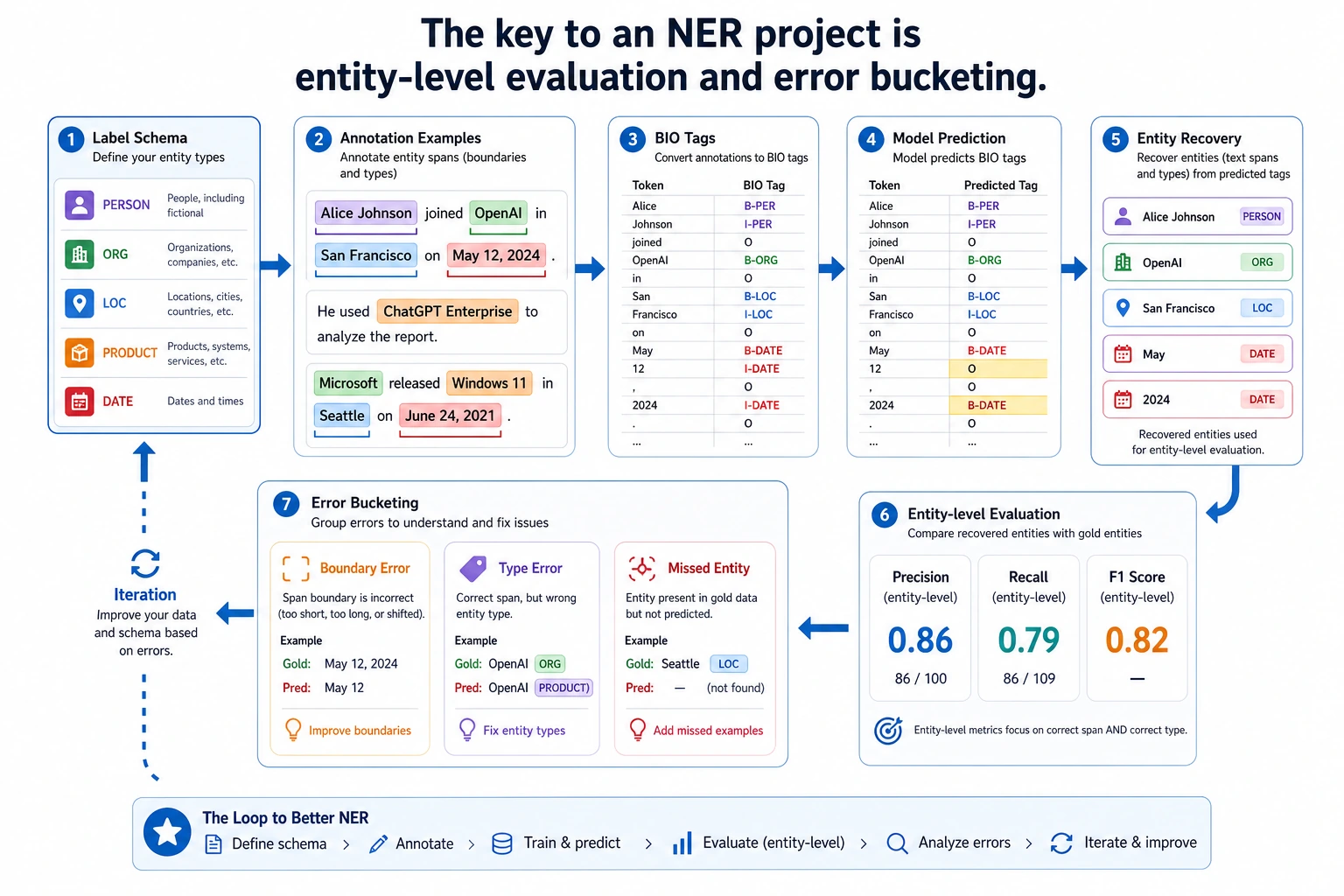
11.4.5 NER Practice
Learning goals
Section titled “Learning goals”- Learn how to define the boundary of a minimal NER project
- Learn how to recover entities from token labels
- Learn how to do entity-level error analysis
- Build a project skeleton for information extraction through a runnable example
First, build a map
Section titled “First, build a map”NER practice is easier to understand in the order of “labels -> entities -> evaluation -> iteration”:
flowchart LR A["Define entity types"] --> B["Design BIO labels"] B --> C["Model outputs label sequence"] C --> D["Recover entity span"] D --> E["Do entity-level evaluation and error analysis"]So the real questions this section wants to solve are:
- Why is an NER project not just “label prediction”?
- Why do entity recovery and error analysis feel more like a real project?
First, define the project problem clearly
Section titled “First, define the project problem clearly”Scenario
Section titled “Scenario”Input:
- A resume or candidate profile text
Output:
- Name
- School
- Skill
Why is this more suitable for practice than “just extracting some entities”?
Section titled “Why is this more suitable for practice than “just extracting some entities”?”Because the boundaries are clear:
- Not too many categories
- Entity types are explicit
- The results are easy to explain from a business perspective
The first key point is not the model, but the label scheme
Section titled “The first key point is not the model, but the label scheme”For example:
Zhang San->B-NAMETsinghua University->B-SCHOOL I-SCHOOL ...Python->B-SKILL
If this step is vague, the model and evaluation will both become messy later.
A better analogy for beginners
Section titled “A better analogy for beginners”You can think of NER as:
- using a highlighter to mark important information in a piece of text
The hard part is not only “marking it,” but also:
- where to start marking
- where to stop
- what category this span belongs to
Once you understand it this way, it becomes much more natural why NER often gets stuck on boundary issues.
First build a runnable annotation and decoding loop
Section titled “First build a runnable annotation and decoding loop”The example below does three things:
- Prepare a small sample
- Decode BIO labels into entities
- Do a simple prediction comparison and error analysis
samples = [ { "tokens": ["Zhang San", "graduated from", "Tsinghua University", ",", "familiar with", "Python", "and", "PyTorch"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL", "O", "B-SKILL"], }, { "tokens": ["Li Si", "is from", "Peking University", ",", "knows", "Java"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "O", "O", "O", "B-SKILL"], },]
def decode_entities(tokens, tags): entities = [] current_tokens = [] current_type = None
for token, tag in zip(tokens, tags): if tag == "O": if current_tokens: entities.append((" ".join(current_tokens), current_type)) current_tokens = [] current_type = None continue
prefix, entity_type = tag.split("-", 1)
if prefix == "B": if current_tokens: entities.append((" ".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type elif prefix == "I" and current_type == entity_type: current_tokens.append(token) else: if current_tokens: entities.append((" ".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type
if current_tokens: entities.append((" ".join(current_tokens), current_type))
return entities
for sample in samples: gold_entities = decode_entities(sample["tokens"], sample["gold_tags"]) pred_entities = decode_entities(sample["tokens"], sample["pred_tags"])
print("tokens:", sample["tokens"]) print("gold :", gold_entities) print("pred :", pred_entities) print("miss :", [x for x in gold_entities if x not in pred_entities]) print()Expected output:
tokens: ['Zhang San', 'graduated from', 'Tsinghua University', ',', 'familiar with', 'Python', 'and', 'PyTorch']gold : [('Zhang San', 'NAME'), ('Tsinghua University', 'SCHOOL'), ('Python', 'SKILL'), ('PyTorch', 'SKILL')]pred : [('Zhang San', 'NAME'), ('Tsinghua University', 'SCHOOL'), ('Python', 'SKILL'), ('PyTorch', 'SKILL')]miss : []
tokens: ['Li Si', 'is from', 'Peking University', ',', 'knows', 'Java']gold : [('Li Si', 'NAME'), ('Peking University', 'SCHOOL'), ('Java', 'SKILL')]pred : [('Li Si', 'NAME'), ('Java', 'SKILL')]miss : [('Peking University', 'SCHOOL')]
The second sample misses the school entity. That is exactly why NER projects should inspect recovered entities, not only token-level labels.
Why is this code the “minimal project loop”?
Section titled “Why is this code the “minimal project loop”?”Because it already includes:
- data representation
- prediction results
- entity recovery
- error analysis
This is much closer to the shape of a real project than printing a string of labels.
Why compare by entity here instead of only by token?
Section titled “Why compare by entity here instead of only by token?”Because what the business usually cares about is:
- whether the entity was extracted
- whether the type is correct
Not whether a single token was labeled correctly.
Another minimal “entity log” example
Section titled “Another minimal “entity log” example”sample = { "tokens": ["Li Si", "is from", "Peking University", ",", "knows", "Java"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "O", "O", "O", "B-SKILL"],}
def decode_entities(tokens, tags): entities = [] current_tokens = [] current_type = None
for token, tag in zip(tokens, tags): if tag == "O": if current_tokens: entities.append((" ".join(current_tokens), current_type)) current_tokens = [] current_type = None continue
prefix, entity_type = tag.split("-", 1) if prefix == "B": if current_tokens: entities.append((" ".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type elif prefix == "I" and current_type == entity_type: current_tokens.append(token)
if current_tokens: entities.append((" ".join(current_tokens), current_type))
return entities
gold_entities = decode_entities(sample["tokens"], sample["gold_tags"])pred_entities = decode_entities(sample["tokens"], sample["pred_tags"])
print( { "text": " ".join(sample["tokens"]).replace(" ,", ","), "gold_entities": gold_entities, "pred_entities": pred_entities, })Expected output:
{'text': 'Li Si is from Peking University, knows Java', 'gold_entities': [('Li Si', 'NAME'), ('Peking University', 'SCHOOL'), ('Java', 'SKILL')], 'pred_entities': [('Li Si', 'NAME'), ('Java', 'SKILL')]}This kind of log is especially good for beginners because it turns an abstract labeling task into a more realistic project output:
- What is the original text?
- What are the correct entities?
- What exactly did the system miss?
What metrics should an NER project look at first?
Section titled “What metrics should an NER project look at first?”Entity-level Precision / Recall / F1
Section titled “Entity-level Precision / Recall / F1”This is the most common and most meaningful set of metrics.
Why is token accuracy not enough?
Section titled “Why is token accuracy not enough?”Because most positions in a sequence are often:
O
If you only look at token accuracy, it can easily seem “very high,” but the actual entity extraction performance may still be poor.
A minimal entity recall example
Section titled “A minimal entity recall example”samples = [ { "tokens": ["Zhang San", "graduated from", "Tsinghua University", ",", "familiar with", "Python", "and", "PyTorch"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL", "O", "B-SKILL"], }, { "tokens": ["Li Si", "is from", "Peking University", ",", "knows", "Java"], "gold_tags": ["B-NAME", "O", "B-SCHOOL", "O", "O", "B-SKILL"], "pred_tags": ["B-NAME", "O", "O", "O", "O", "B-SKILL"], },]
def decode_entities(tokens, tags): entities = [] current_tokens = [] current_type = None
for token, tag in zip(tokens, tags): if tag == "O": if current_tokens: entities.append((" ".join(current_tokens), current_type)) current_tokens = [] current_type = None continue
prefix, entity_type = tag.split("-", 1) if prefix == "B": if current_tokens: entities.append((" ".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type elif prefix == "I" and current_type == entity_type: current_tokens.append(token)
if current_tokens: entities.append((" ".join(current_tokens), current_type))
return entities
def entity_recall(gold_entities, pred_entities): if not gold_entities: return 1.0 hit = sum(entity in pred_entities for entity in gold_entities) return hit / len(gold_entities)
for sample in samples: gold_entities = decode_entities(sample["tokens"], sample["gold_tags"]) pred_entities = decode_entities(sample["tokens"], sample["pred_tags"]) print(entity_recall(gold_entities, pred_entities))Expected output:
1.00.6666666666666666The first sample recovers all entities. The second recovers 2 of 3 entities, so entity-level recall drops even though many O tokens were still correct.
The safest default order when doing an NER project for the first time
Section titled “The safest default order when doing an NER project for the first time”A more stable order is usually:
- Narrow down the entity types first
- Write the labeling standard clearly first
- Do entity recovery and entity-level evaluation first
- Then switch to a stronger model
This is easier to keep the project stable than rushing to BERT from the start.
The most common failure points in NER projects
Section titled “The most common failure points in NER projects”Wrong entity boundary
Section titled “Wrong entity boundary”For example, only half of a school name is extracted.
Wrong type
Section titled “Wrong type”For example, a skill is recognized as a school.
Missing entity
Section titled “Missing entity”For example, in sample 2, Peking University is missed.
Why is this so suitable for error analysis?
Section titled “Why is this so suitable for error analysis?”Because NER errors are usually very concrete, which makes them easy to inspect one by one and fix category by category.
A very useful error-bucketing method for beginners
Section titled “A very useful error-bucketing method for beginners”When doing error analysis for the first time, the most valuable buckets are usually:
- Boundary error
- Type error
- Missing entity
These three are already enough to help you judge:
- Is it a data annotation problem?
- Is it a model representation problem?
- Or are the post-processing rules not strong enough?
What should the next step be in a real project?
Section titled “What should the next step be in a real project?”Expand the data
Section titled “Expand the data”Especially:
- long entities
- rare entities
- easily confused types
Upgrade from rules / classic models to stronger models
Section titled “Upgrade from rules / classic models to stronger models”For example:
- BiLSTM + CRF
- BERT token classification
Add post-processing rules
Section titled “Add post-processing rules”In many business projects, reasonable post-processing rules can significantly improve entity quality.
If you turn this into a project, what is most worth showing?
Section titled “If you turn this into a project, what is most worth showing?”What is usually most worth showing is not:
- a string of label prediction results
but:
- Original text
- Gold entities
- Predicted entities
- Missed and false extraction cases
- Which type of error you plan to fix first
This makes it much easier for others to feel that:
- you built an information extraction project
- not just trained a sequence labeling model
The most common misconceptions
Section titled “The most common misconceptions”Misconception 1: Only look at token-level metrics
Section titled “Misconception 1: Only look at token-level metrics”NER should pay more attention to entity-level performance.
Misconception 2: Try to cover all entity types from the start
Section titled “Misconception 2: Try to cover all entity types from the start”A more stable approach is usually:
- first choose 2~4 core entity types and make them solid
Misconception 3: Do not define the label scheme clearly at the beginning
Section titled “Misconception 3: Do not define the label scheme clearly at the beginning”If the label boundaries are unclear, both the data and the evaluation will drift.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Schema
- entity types, BIO tags, or sequence-label rules
- Prediction
- token-level labels and extracted spans
- Metric
- entity precision/recall/F1 and boundary cases
- Failure Check
- span boundary, nested entity, unknown word, or inconsistent annotation
- Expected Output
- gold-vs-predicted span table with at least one miss
Summary
Section titled “Summary”The most important thing in this section is to build a practical habit:
When doing an NER project, first make the entity types, label scheme, entity recovery, and entity-level error analysis solid, and only then pursue more complex models.
In that way, what you leave behind is a truly explainable and improvable information extraction project, not just a half-finished script that can run training.
Exercises
Section titled “Exercises”- Add an
ORGorTITLEentity type to the example and expand the samples. - Think about why NER projects are more suitable for entity-level metrics than token accuracy.
- If the system often extracts only half of a long school name, would you prioritize changing the data, changing the model, or adding post-processing? Why?
- How would you further expand this resume extraction project into a portfolio presentation?
Project reference and review notes
- When adding
ORGorTITLE, define boundary rules first: what counts as the organization name, job title, or surrounding modifier. - NER should use entity-level metrics because the user receives extracted entities, not isolated token labels.
- For half-extracted long school names, first inspect annotation consistency, then add examples or post-processing; change the model only after the target is clear.
- A strong portfolio presentation should show label schema, examples, entity-level metrics, error buckets, fixes, and a small before/after improvement log.