7.4.2 Pretraining Data

Learning objectives
Section titled “Learning objectives”- Understand the core quality dimensions of pretraining data
- Understand why “more data” does not always mean “better data”
- Use a runnable example to understand the meaning of cleaning, deduplication, and data mixture ratios
- Build awareness of the risks of contamination, duplication, and low-quality corpora
How this lesson connects to the earlier LLM / pretraining path
Section titled “How this lesson connects to the earlier LLM / pretraining path”If you have already accepted the idea that “pretraining determines the model’s foundation,” then the most natural follow-up here is:
- Earlier, you learned that model capability comes from pretraining
- In this lesson, we ask a more specific question: what data actually feeds those capabilities?
So the real goal here is not the empty phrase “data matters,” but to answer:
- What does pretraining data actually determine?
- Why does data engineering directly affect the model ceiling?
Why does pretraining data determine the model foundation?
Section titled “Why does pretraining data determine the model foundation?”First, a story: two model pipelines read different data
Section titled “First, a story: two model pipelines read different data”Imagine two model pipelines that use the same architecture and training setup.
The first pipeline trains on high-quality technical docs, papers, verified product guides, and well-edited long-form articles. The second trains on repeated ads, clickbait, copied webpages, and messy comments. After enough training steps, their expression quality, factual reliability, and problem-analysis habits will likely look very different.
Pretraining data affects a model in exactly this way. Architecture is the processing machinery, compute is the training budget, and data is the material flowing through the pipeline. Different material leads to different capabilities in the end.
What the model learns is not only knowledge, but also language habits and the world distribution
Section titled “What the model learns is not only knowledge, but also language habits and the world distribution”During pretraining, the model does not automatically distinguish between:
- content that is more trustworthy
- text that is just noise
- expressions that are worth imitating
It tries to fit whatever it sees.
So pretraining data affects not only:
- knowledge coverage
but also:
- language style
- factual reliability
- bias distribution
- safety risks
An analogy: foundation quality sets the ceiling for all later renovation
Section titled “An analogy: foundation quality sets the ceiling for all later renovation”You can think of pretraining data as the foundation.
- Fine-tuning is like renovation
- Alignment is like guardrails and rules
If the foundation itself is messy, then no matter how much you fine-tune later, you are mostly just patching an already-set base.
Why doesn’t “the internet is huge” mean “we can just train on it directly”?
Section titled “Why doesn’t “the internet is huge” mean “we can just train on it directly”?”Because real-world text contains many problems:
- duplicated content
- low-quality copies
- ads and spam pages
- template-like SEO text
- illegal or sensitive content
- evaluation set contamination
The real challenge of large models is not that data is unavailable, but rather:
How do you turn massive raw text into a high-quality, controllable, reusable data foundation?
When learning pretraining data for the first time, what should you grasp first?
Section titled “When learning pretraining data for the first time, what should you grasp first?”What you should grasp first is not specific corpus names, but this sentence:
During pretraining, the model cannot automatically tell what is worth learning, so data governance is the first round of value filtering on behalf of the model.
Once this idea is stable, then later when you see:
- deduplication
- filtering
- mixture ratios
- contamination control
you will understand that these are not just engineering details — they directly shape the model foundation.
Put the pretraining data pipeline in one picture first
Section titled “Put the pretraining data pipeline in one picture first”flowchart LR A["Raw data<br/>web / books / code / forums"] --> B["Cleaning<br/>remove ads / remove garbled text / filter low-quality data"] B --> C["Deduplication<br/>exact / near duplicate"] C --> D["Risk control<br/>privacy / copyright / contamination"] D --> E["Data mixture<br/>web / book / code / chat"] E --> F["Training corpus version"] F --> G["Pretrained model foundation"]This pipeline helps make “data matters” concrete: every step changes what the model can learn, what it leans toward, and what mistakes it is likely to make.
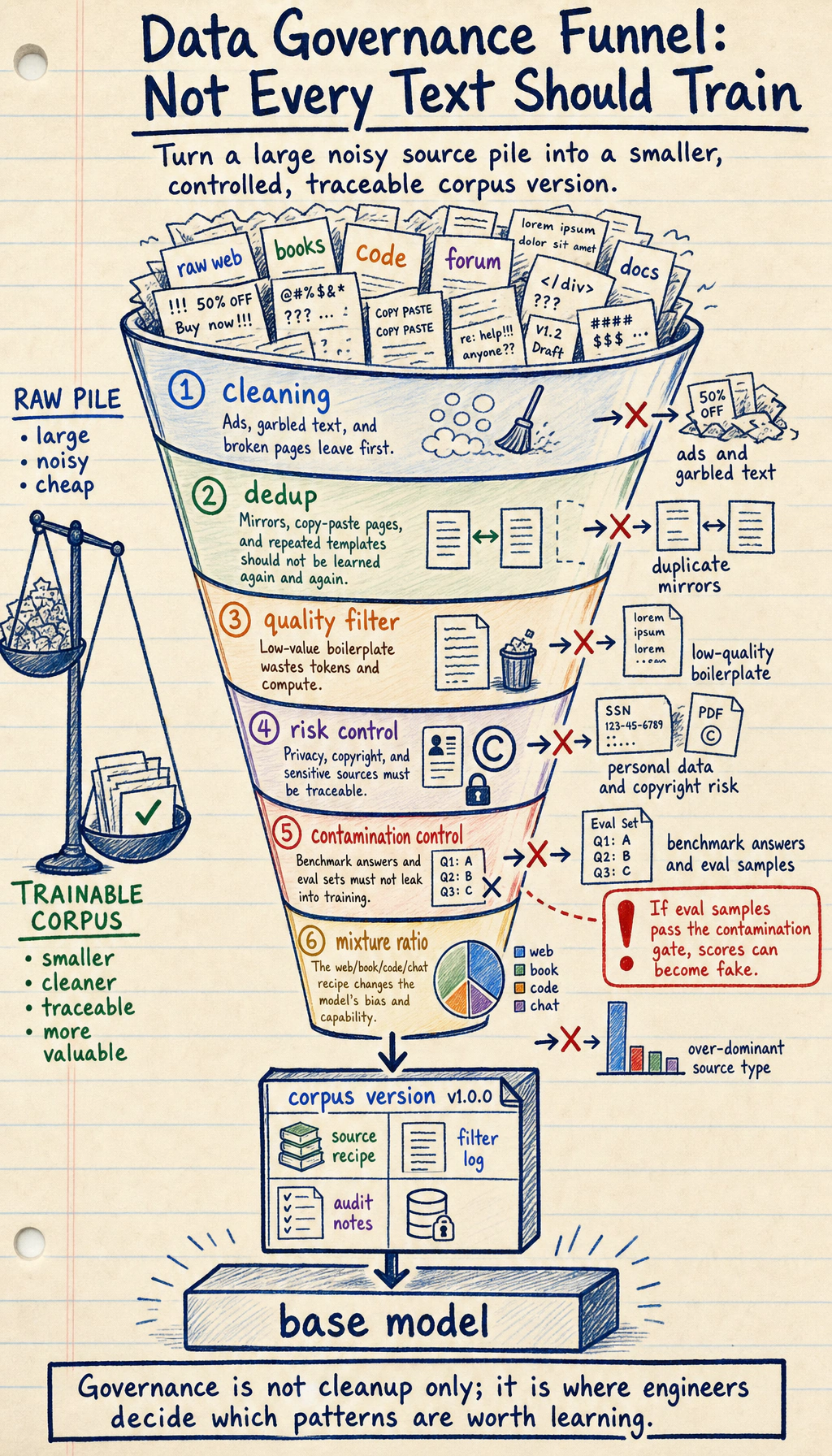
Which dimensions should we look at for pretraining data?
Section titled “Which dimensions should we look at for pretraining data?”Coverage: how many types of language and knowledge can the model access?
Section titled “Coverage: how many types of language and knowledge can the model access?”Common sources may include:
- webpages
- books
- code
- academic papers
- Q&A forums
- conversational corpora
Insufficient coverage can make the model clearly weak in some scenarios. For example:
- If code is underrepresented, coding ability will be weak
- If long-form writing is rare, long-document organization will be poor
Quality: not every token is equally valuable
Section titled “Quality: not every token is equally valuable”A very practical rule of thumb is:
- The value of high-quality tokens often far exceeds simply stacking more low-quality tokens
If the corpus contains lots of:
- repeated sentence patterns
- mechanical concatenation
- marketing ads
- typos and broken grammar
then the model wastes compute on patterns that are not worth learning.
Diversity: the model should not only know one style of speaking
Section titled “Diversity: the model should not only know one style of speaking”If all data comes from the same kind of source, the model will likely become biased.
For example, if it is all forum-style casual language, then:
- style may become unstable
- formal writing ability may be weak
If it is all encyclopedia-style writing, then:
- conversational feel may be lacking
- instruction following may feel unnatural
Safety and compliance: some content should not be handled with “just train on it first”
Section titled “Safety and compliance: some content should not be handled with “just train on it first””Data governance must also consider:
- copyright risks
- privacy information
- sensitive or harmful content
- compliance boundaries
This is not something you can fully fix later with a safety fine-tune.
When first learning data governance, which four words are most worth remembering?
Section titled “When first learning data governance, which four words are most worth remembering?”You can start with these four words:
- coverage
- quality
- diversity
- risk
These four words are basically the smallest framework for almost all later data discussions.
First run a truly useful data cleaning example
Section titled “First run a truly useful data cleaning example”The code below simulates a very small pretraining data pipeline:
- Text normalization
- Deduplication
- Low-quality filtering
- Statistics on the proportion kept from each source
from collections import Counter
raw_docs = [ {"source": "web", "text": "Click to claim a coupon!!! Click to claim a coupon!!!"}, {"source": "web", "text": "Python is a programming language. Python is widely used."}, {"source": "book", "text": "The transformer architecture uses self-attention to model token interactions."}, {"source": "web", "text": "python is a programming language. python is widely used."}, {"source": "forum", "text": "I forgot my password, and customer service said I could reset it by SMS."}, {"source": "forum", "text": "hahahahaha"},]
def normalize(text): return " ".join(text.lower().replace("!", "!").split())
def repeated_char_ratio(text): if len(text) < 2: return 0.0 repeats = sum(text[i] == text[i - 1] for i in range(1, len(text))) return repeats / (len(text) - 1)
def quality_ok(text): if len(text.split()) < 4 and len(text) < 12: return False if "coupon" in text or "click to claim" in text: return False if repeated_char_ratio(text) > 0.6: return False return True
seen = set()clean_docs = []for doc in raw_docs: normalized = normalize(doc["text"]) if normalized in seen: continue if not quality_ok(normalized): continue seen.add(normalized) clean_docs.append({"source": doc["source"], "text": normalized})
print("kept docs:")for doc in clean_docs: print(doc)
print("\nsource mix:", Counter(doc["source"] for doc in clean_docs))Expected output:
kept docs:{'source': 'web', 'text': 'python is a programming language. python is widely used.'}{'source': 'book', 'text': 'the transformer architecture uses self-attention to model token interactions.'}{'source': 'forum', 'text': 'i forgot my password, and customer service said i could reset it by sms.'}
source mix: Counter({'web': 1, 'book': 1, 'forum': 1})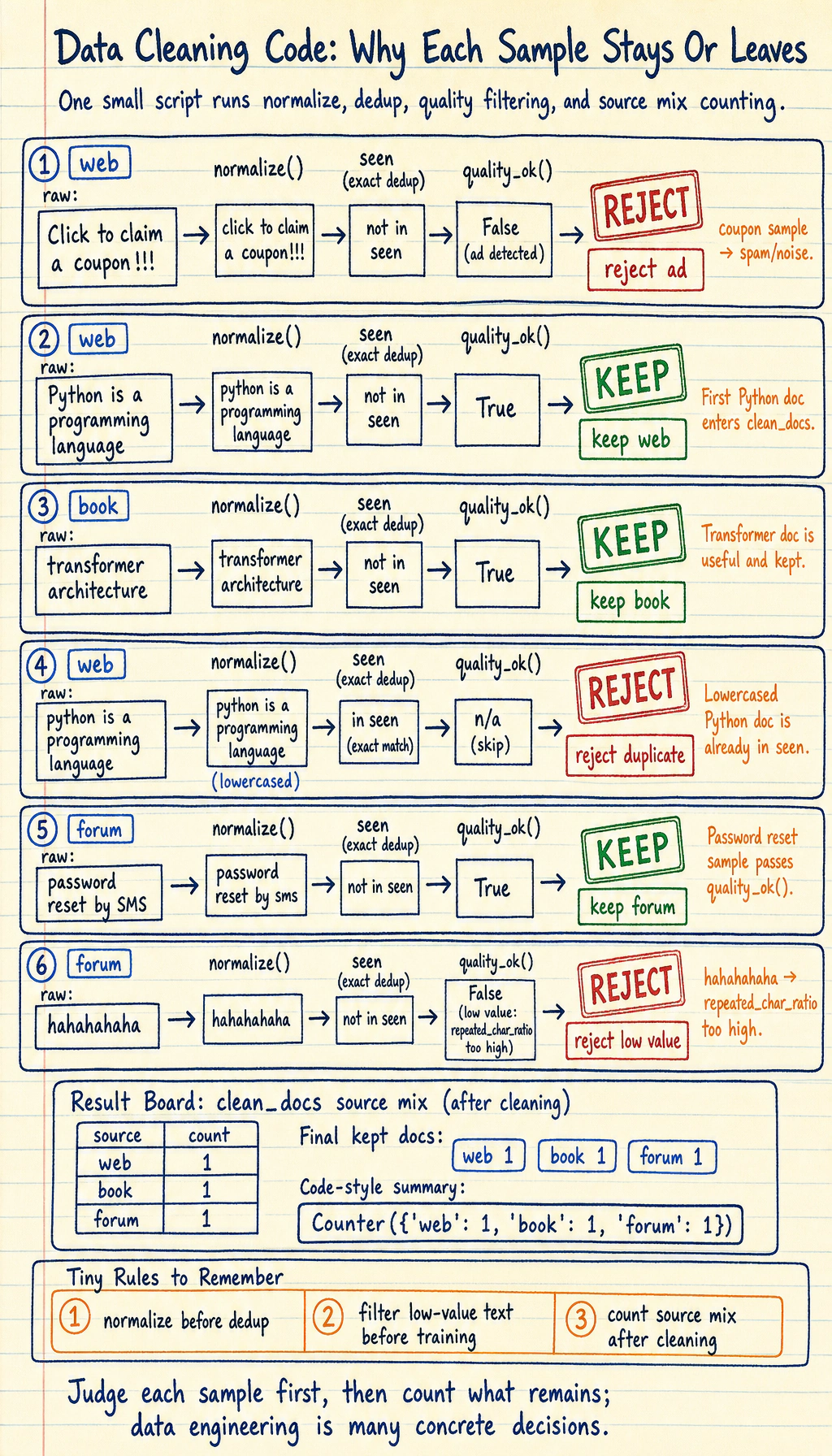
What steps in real engineering does this code correspond to?
Section titled “What steps in real engineering does this code correspond to?”Although it is very small, it corresponds to the most common actions in a pretraining pipeline:
- text normalization
- exact deduplication
- low-quality sample filtering
- source distribution statistics
This is not optional preprocessing, but the basic foundation of large-model data engineering.
Why is deduplication especially important?
Section titled “Why is deduplication especially important?”Because duplicate text makes the model see the same content again and again. This creates two problems:
- Training tokens are wasted
- Certain patterns are over-amplified
This is especially common in web data, where reposts, mirrors, and template pages are everywhere.
Why should a sample like “hahahahaha” be filtered out?
Section titled “Why should a sample like “hahahahaha” be filtered out?”Because although this is real language, it has almost no value for improving general capability, and it may also skew the distribution.
So pretraining data is not about being as raw as possible, but about judging “training value.”
Why is this small example especially worth studying again and again?
Section titled “Why is this small example especially worth studying again and again?”Because it shows you:
- data engineering does not start from abstract ideas
- it starts from many very concrete judgments
For example:
- Is this sample duplicated?
- Is this sample noise?
- Is the proportion from this source too imbalanced?
These judgments accumulate into differences in model capability.
Why does data mixture directly affect model style?
Section titled “Why does data mixture directly affect model style?”Tokens from different sources shape different capabilities
Section titled “Tokens from different sources shape different capabilities”A rough but practical understanding is:
- Web: broad coverage, but quality varies a lot
- Books: complete structure, more stable language
- Code: strengthens program patterns and formal language ability
- Forum dialogue: improves conversational style and interactivity
So the final data mixture ratio directly affects whether the model feels more like:
- an encyclopedia
- an assistant
- a programmer
What happens if the mixture ratio is unreasonable?
Section titled “What happens if the mixture ratio is unreasonable?”For example:
- If code accounts for too little, coding ability becomes weak
- If forum data is too dominant, formal writing may become too casual
- If low-quality web pages are too common, the model may sound vague and template-like
That is also why before training, people often need to design:
- source mix
A simple example of mixture-based sampling
Section titled “A simple example of mixture-based sampling”import randomfrom pprint import pprint
random.seed(42)
datasets = { "web": ["web_1", "web_2", "web_3"], "book": ["book_1", "book_2"], "code": ["code_1", "code_2"],}
mix = {"web": 0.5, "book": 0.2, "code": 0.3}
def sample_source(mix_config): r = random.random() cumulative = 0.0 for source, prob in mix_config.items(): cumulative += prob if r <= cumulative: return source return source
draws = []for _ in range(20): source = sample_source(mix) item = random.choice(datasets[source]) draws.append((source, item))
pprint(draws)Expected output:
[('book', 'book_1'), ('code', 'code_1'), ('web', 'web_3'), ('web', 'web_3'), ('code', 'code_1'), ('book', 'book_1'), ('web', 'web_1'), ('web', 'web_3'), ('web', 'web_1'), ('code', 'code_2'), ('web', 'web_3'), ('web', 'web_1'), ('code', 'code_1'), ('book', 'book_2'), ('web', 'web_1'), ('code', 'code_2'), ('web', 'web_2'), ('web', 'web_2'), ('book', 'book_1'), ('code', 'code_1')]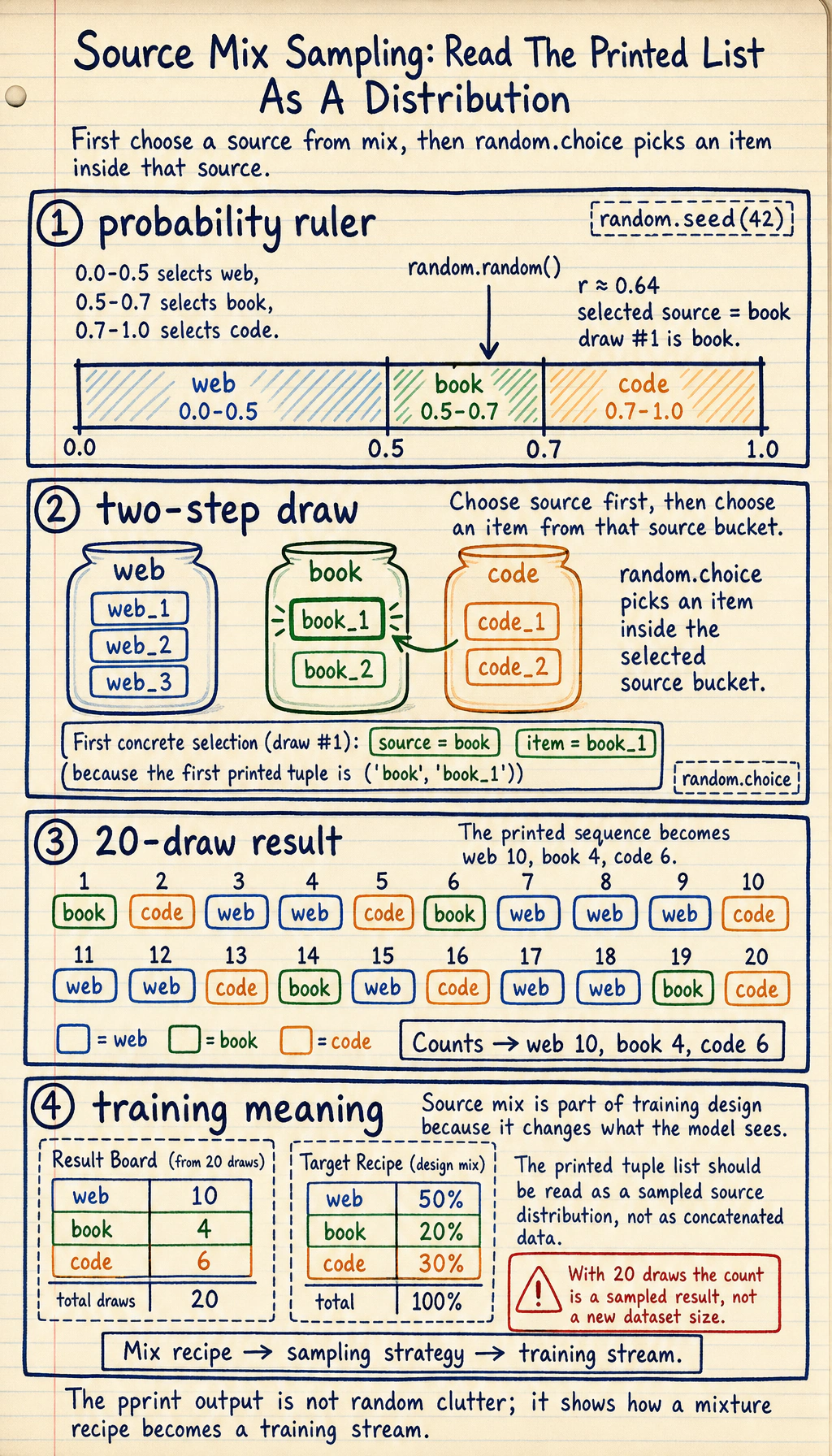
This code is reminding you that:
- data mixing is not “just throw everything in”
- the sampling strategy itself is part of training design
Why are contamination and evaluation leakage so dangerous?
Section titled “Why are contamination and evaluation leakage so dangerous?”What is data contamination?
Section titled “What is data contamination?”A very common form is:
- evaluation questions, reference answers, or close variants get mixed into the training data
Then the model looks strong during evaluation, but that is not generalization — it is more like having already seen the original question.
Why is this more serious than ordinary duplication?
Section titled “Why is this more serious than ordinary duplication?”Because it directly distorts your judgment of model ability. You may think:
- the model is better at reasoning
- the model knows more
But in reality it may just be:
- the test samples leaked into the training data
How can we reduce this risk in practice?
Section titled “How can we reduce this risk in practice?”Common approaches include:
- near-duplicate detection based on hashes or n-grams
- explicit filtering of public benchmarks
- strict tracking of data sources and versions
This is also why data governance must have version awareness.
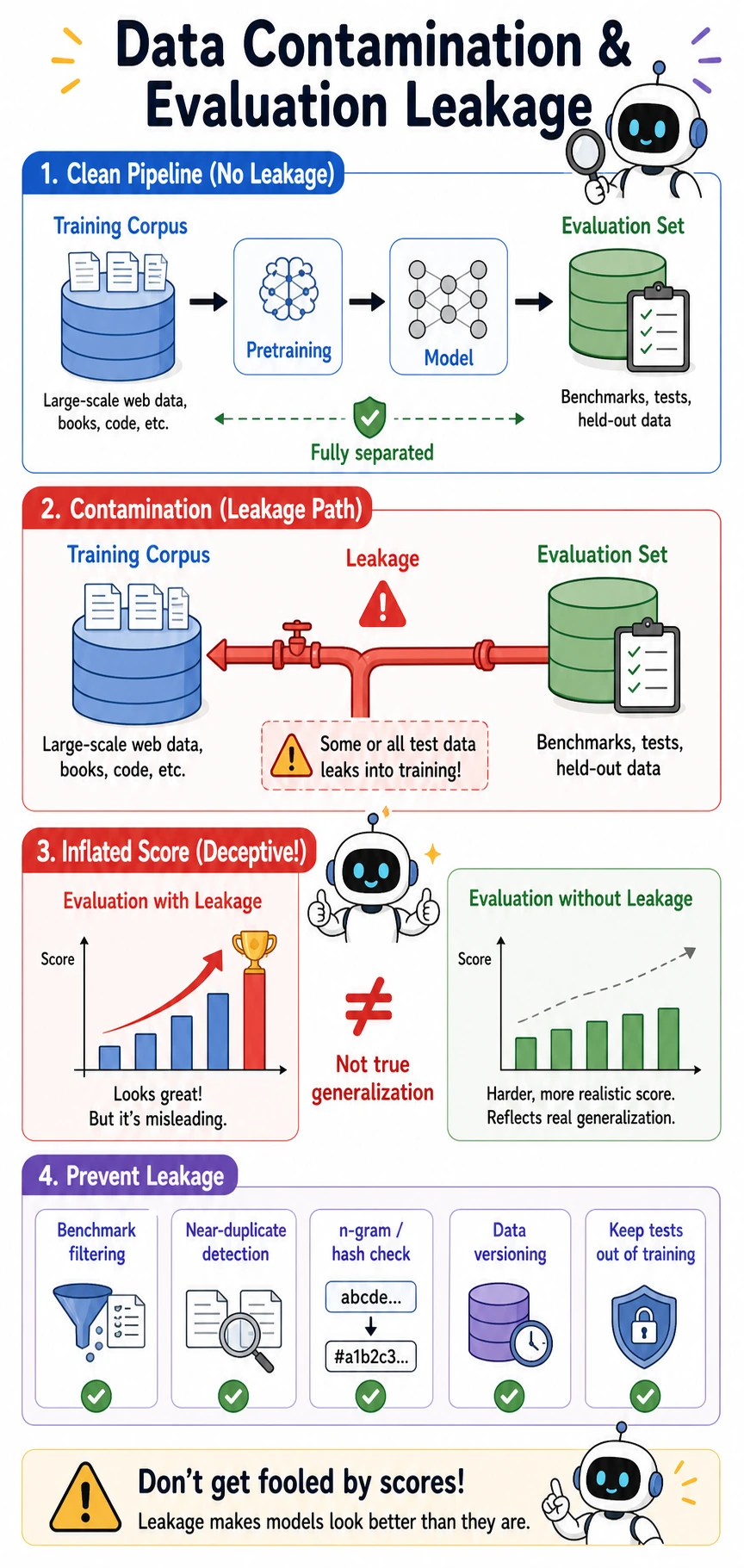
Terms worth distinguishing
Section titled “Terms worth distinguishing”- Data contamination: test data, answers, or near-duplicates enter the training corpus. The risk is that the model memorizes benchmark patterns instead of learning transferable ability.
- Evaluation leakage: evaluation information influences training or prompt design. Scores stop reflecting real unseen performance.
- Benchmark: a standard test set used to compare models. Public benchmarks are useful, but they are also easier to leak into web-scale corpora.
- n-gram / hash check: a way to compare text fragments or fingerprints for overlap. It helps detect exact duplicates and suspiciously similar samples.
- Versioning: a record of the data sources, filters, and rules behind each corpus version. Without it, you cannot explain score changes or reproduce a training run.
Pretraining data quality self-check table
Section titled “Pretraining data quality self-check table”When reviewing a pretraining corpus, you can use the table below for a quick judgment:
| Checkpoint | What should you ask? | What happens if it is done poorly? |
|---|---|---|
| Coverage | Does it cover the language, domain, and formats required by the task? | The model becomes obviously weak in some scenarios |
| Quality | Does it contain a lot of ads, garbled text, or template pages? | The model learns low-value patterns |
| Deduplication | Are there many reposts, mirrors, or repeated templates? | Tokens are wasted, and repeated patterns are amplified |
| Mixture ratio | Do the proportions of web, books, code, and dialogue match the target? | Style and capability become unbalanced |
| Contamination | Have evaluation sets or answers leaked into training? | Evaluation scores become falsely high, and generalization is misjudged |
| Versioning | Are the data sources and processing rules traceable? | Reproducing experiments and troubleshooting becomes difficult |
This table is worth putting into your project notes, because it shows that you do not just know “more data is better,” but can judge whether the data is suitable for training from an engineering perspective.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Data Sources
- source types and mixture rationale
- Cleaning Result
- one before/after cleaning example
- Dedup Check
- duplicate or near-duplicate risk noted
- Contamination Check
- eval leakage risk documented
- Quality Rule
- data quality is part of model capability
The most common pitfalls in pretraining data
Section titled “The most common pitfalls in pretraining data”Mistake 1: More data is always better
Section titled “Mistake 1: More data is always better”If the low-quality proportion is high, simply increasing volume may just waste compute.
Mistake 2: The stricter the cleaning, the safer it is
Section titled “Mistake 2: The stricter the cleaning, the safer it is”Over-cleaning also has a cost:
- diversity decreases
- rare knowledge may be removed by mistake
- language style becomes narrower
So cleaning is not about being as aggressive as possible, but about matching the target capability.
Mistake 3: Since we have fine-tuning later, pretraining data does not need that much attention
Section titled “Mistake 3: Since we have fine-tuning later, pretraining data does not need that much attention”That is not correct. Fine-tuning is more like shaping an already existing foundation in a targeted way, not tearing down and rebuilding the foundation from scratch.
Summary
Section titled “Summary”The most important thing in this lesson is not memorizing a few data source names, but building this judgment:
Pretraining data determines what kind of world the model sees, and the core of a high-quality pretraining pipeline is not just collecting more text, but performing cleaning, deduplication, mixture control, and contamination control.
Once this judgment is in place, then when you later look at pretraining objectives, training engineering, and fine-tuning data, you will know which problems should be solved at the source.
Exercises
Section titled “Exercises”- Based on the code in this section, add a few more samples that you think should be filtered or kept, and see whether the rules are reasonable.
- Why do we say “exact dedup” is only the first step, and real projects also need near-duplicate detection?
- Think about it: if your model is mainly for code scenarios, how should the data mixture ratio be adjusted?
- Explain in your own words: why does evaluation leakage make us overestimate model capability?
Project reference and review notes
- Good added samples should test specific rules: boilerplate pages, repeated ads, malformed text, clean technical prose, and high-value rare examples. If a useful sample is removed or a low-value sample is kept, the rule needs adjustment.
- Exact dedup only catches identical strings or fingerprints. Near-duplicate detection is needed for copied pages with small edits, template variants, translated mirrors, and lightly rewritten benchmark material.
- A code-oriented model should increase code, documentation, issue discussions, API references, tests, and debugging traces while still keeping enough natural language for instructions and explanations. The mixture should follow the intended product behavior, not a generic ratio.
- If evaluation examples appear in training, the model may memorize them or learn their surface patterns. The score then measures exposure, not true generalization to unseen tasks.