5.4.3 Cross-Validation
What You Will Build
Section titled “What You Will Build”This lesson shows:
- why one train-test split can be noisy;
- how to use
StratifiedKFoldfor classification; - how to evaluate several metrics with
cross_validate; - why preprocessing must stay inside
Pipeline; - when random K-Fold is wrong, especially for time series.
python -m pip install -U scikit-learn numpyRun the Complete Lab
Section titled “Run the Complete Lab”Create cv_lab.py:
import numpy as npfrom sklearn.datasets import load_breast_cancerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import StratifiedKFold, cross_validate, train_test_splitfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScaler
X, y = load_breast_cancer(return_X_y=True)
print("single_split_variance")for seed in [1, 2, 3, 4, 5]: X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=seed, stratify=y ) model = Pipeline([ ("scale", StandardScaler()), ("clf", LogisticRegression(max_iter=2000, random_state=42)), ]) model.fit(X_train, y_train) print(f"seed={seed} accuracy={accuracy_score(y_test, model.predict(X_test)):.3f}")
print("cross_validation_lab")cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)model = Pipeline([ ("scale", StandardScaler()), ("clf", LogisticRegression(max_iter=2000, random_state=42)),])result = cross_validate( model, X, y, cv=cv, scoring=["accuracy", "precision", "recall", "f1"],)for i, score in enumerate(result["test_accuracy"], start=1): print(f"fold={i} accuracy={score:.3f}")print( "summary " f"accuracy={np.mean(result['test_accuracy']):.3f}+/-{np.std(result['test_accuracy']):.3f} " f"precision={np.mean(result['test_precision']):.3f} " f"recall={np.mean(result['test_recall']):.3f} " f"f1={np.mean(result['test_f1']):.3f}")Run it:
python cv_lab.pyExpected output:
single_split_varianceseed=1 accuracy=0.965seed=2 accuracy=0.972seed=3 accuracy=0.986seed=4 accuracy=0.972seed=5 accuracy=0.979cross_validation_labfold=1 accuracy=0.974fold=2 accuracy=0.947fold=3 accuracy=0.965fold=4 accuracy=0.991fold=5 accuracy=0.991summary accuracy=0.974+/-0.017 precision=0.968 recall=0.992 f1=0.979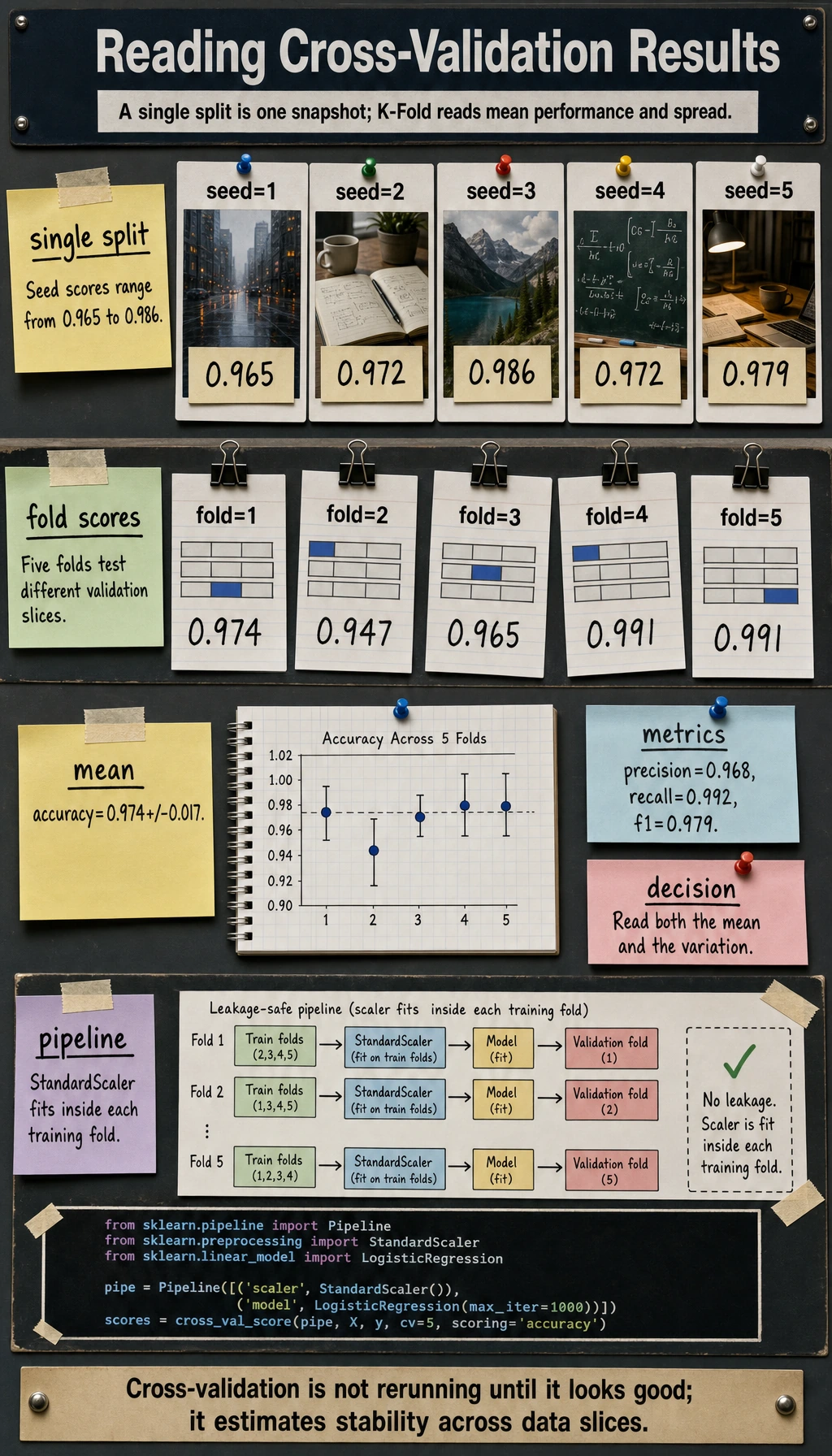
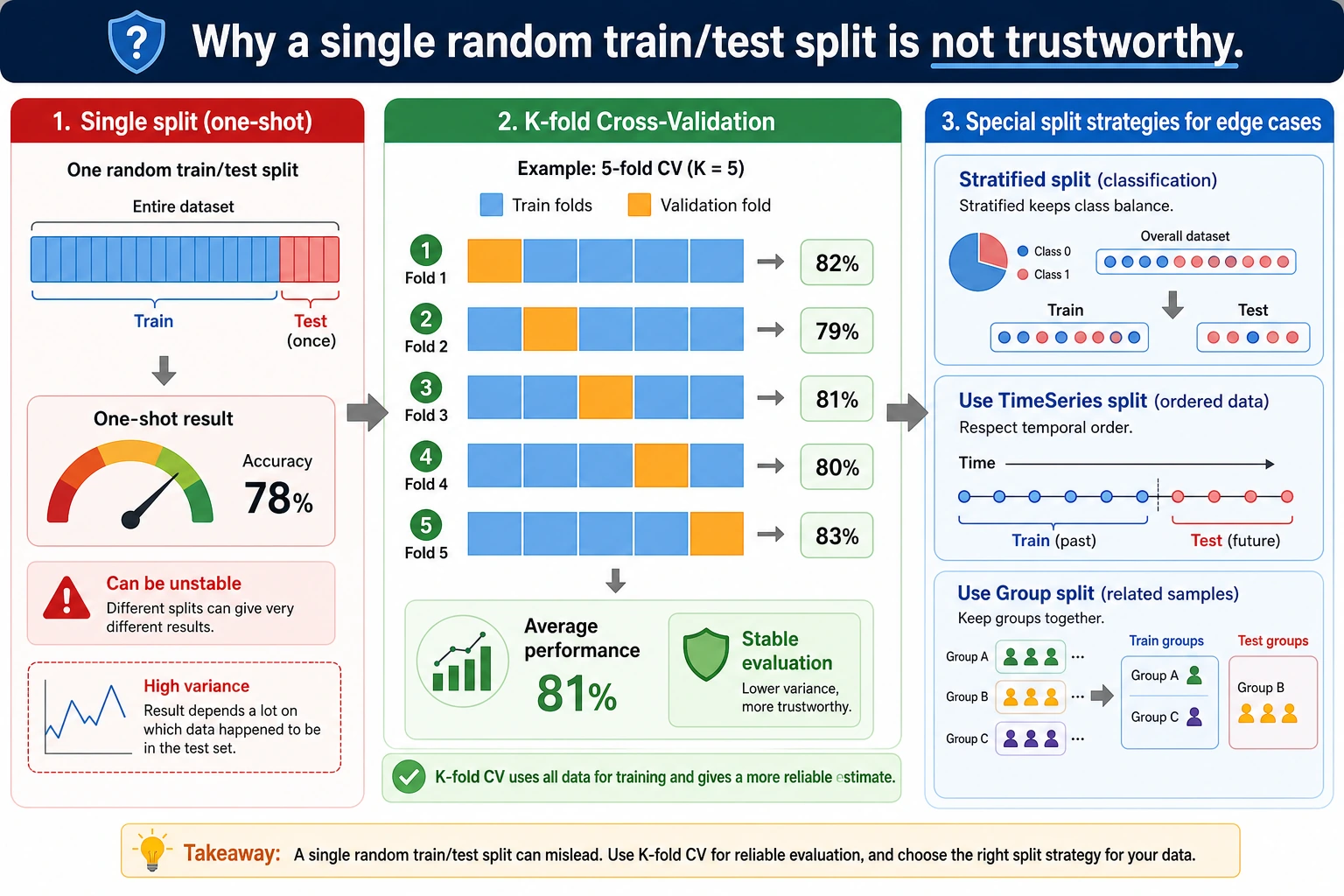
Why One Split Is Not Enough
Section titled “Why One Split Is Not Enough”The same model gets different scores with different random splits:
seed=1 accuracy=0.965seed=3 accuracy=0.986Neither number is fake. They are just different snapshots. Cross-validation asks: “Across several snapshots, what is the average performance and how much does it vary?”
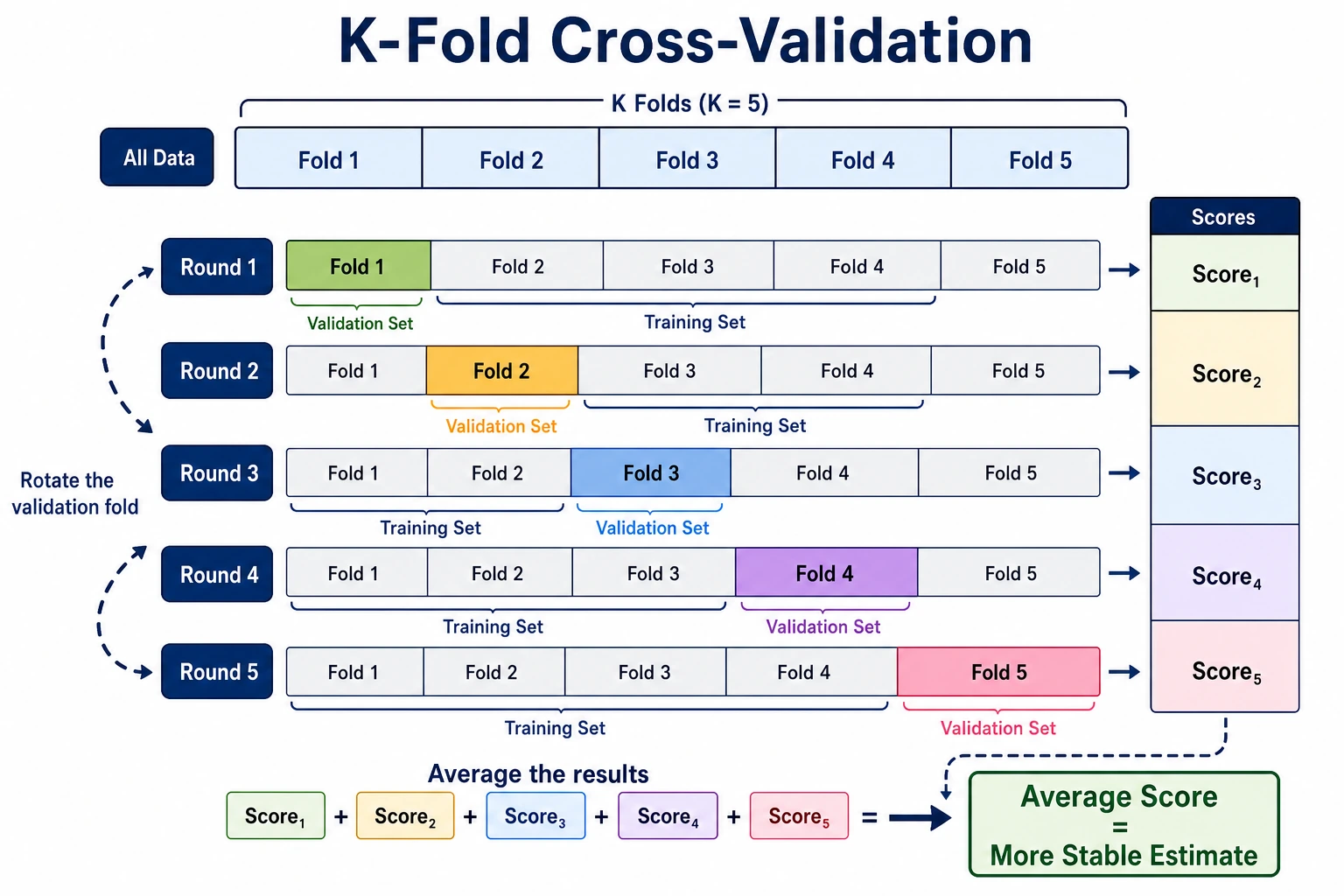
Stratified K-Fold
Section titled “Stratified K-Fold”For classification, use StratifiedKFold first. It keeps the class ratio similar in each fold, which is especially important for imbalanced datasets.
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)Use K=5 as a practical default:
- less noisy than one split;
- cheaper than 10-fold on large data;
- easy to explain to teammates.
Use a Leakage-Safe Pipeline
Section titled “Use a Leakage-Safe Pipeline”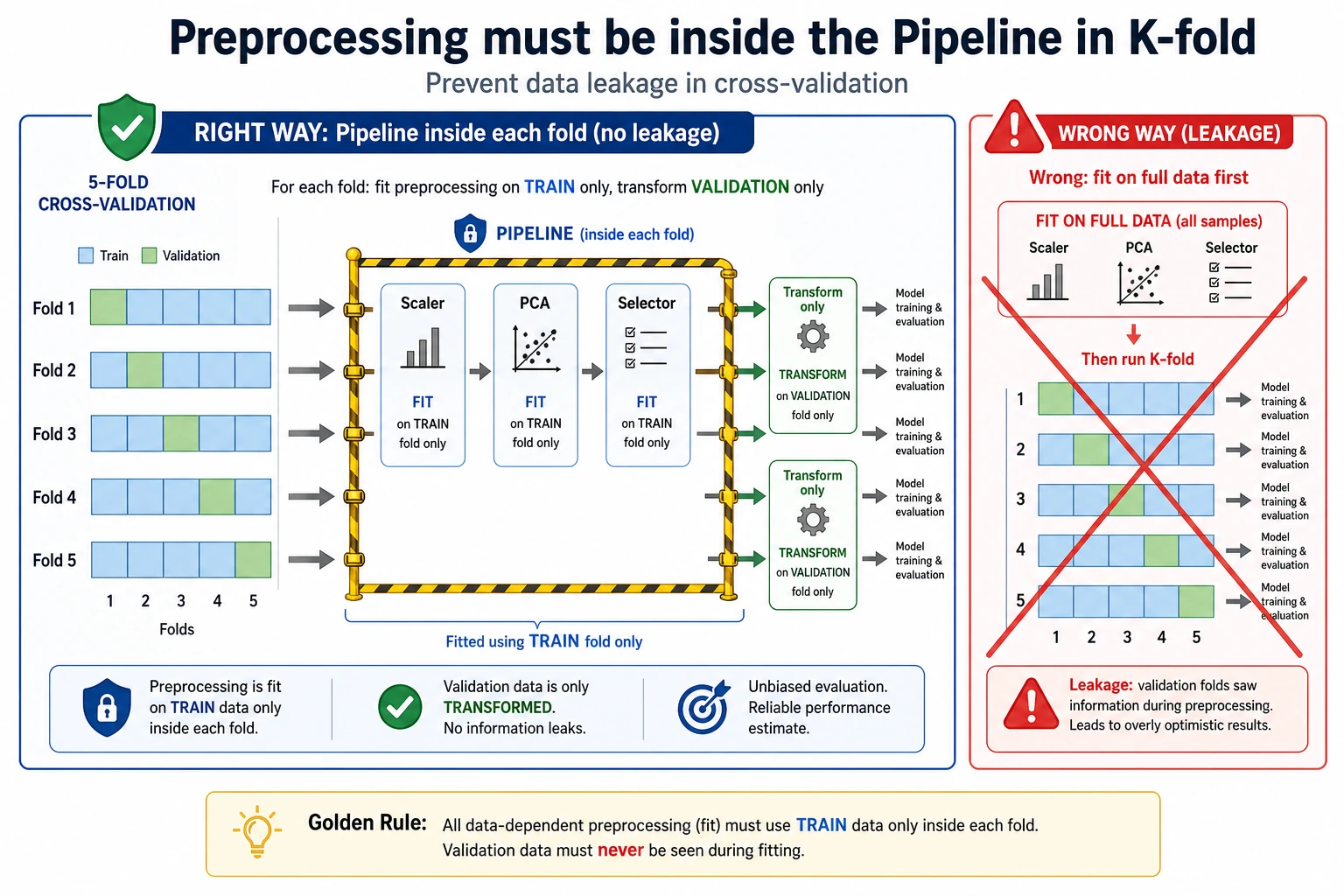
This is the safe pattern:
Pipeline([ ("scale", StandardScaler()), ("clf", LogisticRegression(max_iter=2000, random_state=42)),])During cross-validation, each fold must fit its scaler only on that fold’s training portion. If you scale all data before CV, information from validation folds leaks into training.
Read Mean and Variance
Section titled “Read Mean and Variance”The summary is more useful than one fold:
summary accuracy=0.974+/-0.017 precision=0.968 recall=0.992 f1=0.979Read it as:
- average accuracy is about
0.974; - fold-to-fold variation is about
0.017; - recall is very high, which matters if missing positives is costly.
If standard deviation is large, the model may be unstable, the dataset may be small, or some folds may contain harder cases.
When K-Fold Is Wrong
Section titled “When K-Fold Is Wrong”Do not shuffle randomly when:
- the data is time series;
- rows from the same user/session/device can appear in both train and validation;
- examples are grouped by patient, customer, document, or experiment;
- future information would leak into the past.
Use a split that matches the real deployment situation: TimeSeriesSplit, group splits, or a chronological holdout.
Practical Choice Guide
Section titled “Practical Choice Guide”| Situation | Use |
|---|---|
| Basic classification | StratifiedKFold(n_splits=5, shuffle=True) |
| Regression | KFold(n_splits=5, shuffle=True) |
| Time series | TimeSeriesSplit or chronological validation |
| Same entity appears many times | group-aware splitting |
| Hyperparameter tuning | nested CV or a final untouched test set |
For experienced readers: after model selection, keep one final holdout set or production-like backtest that was not used during tuning.
Practical Debugging Checklist
Section titled “Practical Debugging Checklist”| Symptom | Likely cause | Fix |
|---|---|---|
| CV score much higher than test score | leakage or over-tuning | put preprocessing in pipeline; keep final holdout |
| Fold scores vary wildly | small data or hard segments | inspect fold composition and segment metrics |
| Classification fold has no positives | non-stratified split | use StratifiedKFold |
| Time-series model looks too good | future data leaked | validate chronologically |
| CV takes too long | too many folds or heavy model | use fewer folds or faster baseline first |
Practice
Section titled “Practice”- Change
n_splitsto3and10. How do mean and standard deviation change? - Remove
stratify=yfrom the single split. Does the score become less stable? - Add
roc_aucto the scoring list. - Move
StandardScaler()outside the pipeline intentionally, then explain why that is unsafe. - Design a validation split for user events where each user has many rows.
Reference implementation and walkthrough
- Fewer folds train on less data per run and may give a rougher estimate. More folds train on more data but cost more; watch both the mean score and the standard deviation.
- Removing stratification can make class proportions drift between train and test, especially with imbalance. That usually makes scores less stable and harder to compare.
roc_aucadds a ranking-oriented view. It is useful when threshold choice is still open, but it should be paired with precision/recall metrics for imbalanced tasks.- Scaling outside the pipeline lets validation data influence the scaler. That is leakage, because the validation fold is no longer truly unseen.
- User-event data should avoid putting rows from the same user in both train and validation. Use a group split by user, and consider time-based validation if deployment predicts future behavior.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Evaluation Setup
- split, cross-validation, metric, baseline, and comparison target
- Result
- score table, curve, confusion matrix, validation result, or search outcome
- Decision
- whether to change data, features, model, threshold, or hyperparameters
- Failure Check
- leakage, unstable validation, wrong metric, or tuning on the test set
- Expected Output
- evaluation record that supports a next modeling decision
Pass Check
Section titled “Pass Check”You are done when you can explain:
- one train-test split is only one snapshot;
- K-Fold estimates average performance and variability;
- classification should usually use stratified folds;
- preprocessing must be inside the pipeline;
- validation strategy must match deployment data flow.