9.9.4 Persistence and Recovery
Learning Objectives
Section titled “Learning Objectives”- Understand the meaning of “persistence” and “recovery” in Agent tasks
- Learn to distinguish between state snapshots and event logs
- Implement a minimal checkpoint + recovery flow with a runnable example
- Understand why idempotency matters in the recovery path
Why do Agents especially need recoverability?
Section titled “Why do Agents especially need recoverability?”Because many tasks are not completed instantly
Section titled “Because many tasks are not completed instantly”For example:
- Research report generation
- Multi-tool approval workflows
- Multi-round background crawling and organization
These tasks often span:
- Multiple calls
- Multiple steps
- Longer time windows
What happens without recovery capability?
Section titled “What happens without recovery capability?”- If the task is interrupted, everything starts over
- Already executed actions may be repeated
- Users cannot tell the current progress
An analogy
Section titled “An analogy”An Agent without persistence is like a workstation that “forgets everything when the power goes out.” A production-ready system is more like an IDE with auto-save and restore points.
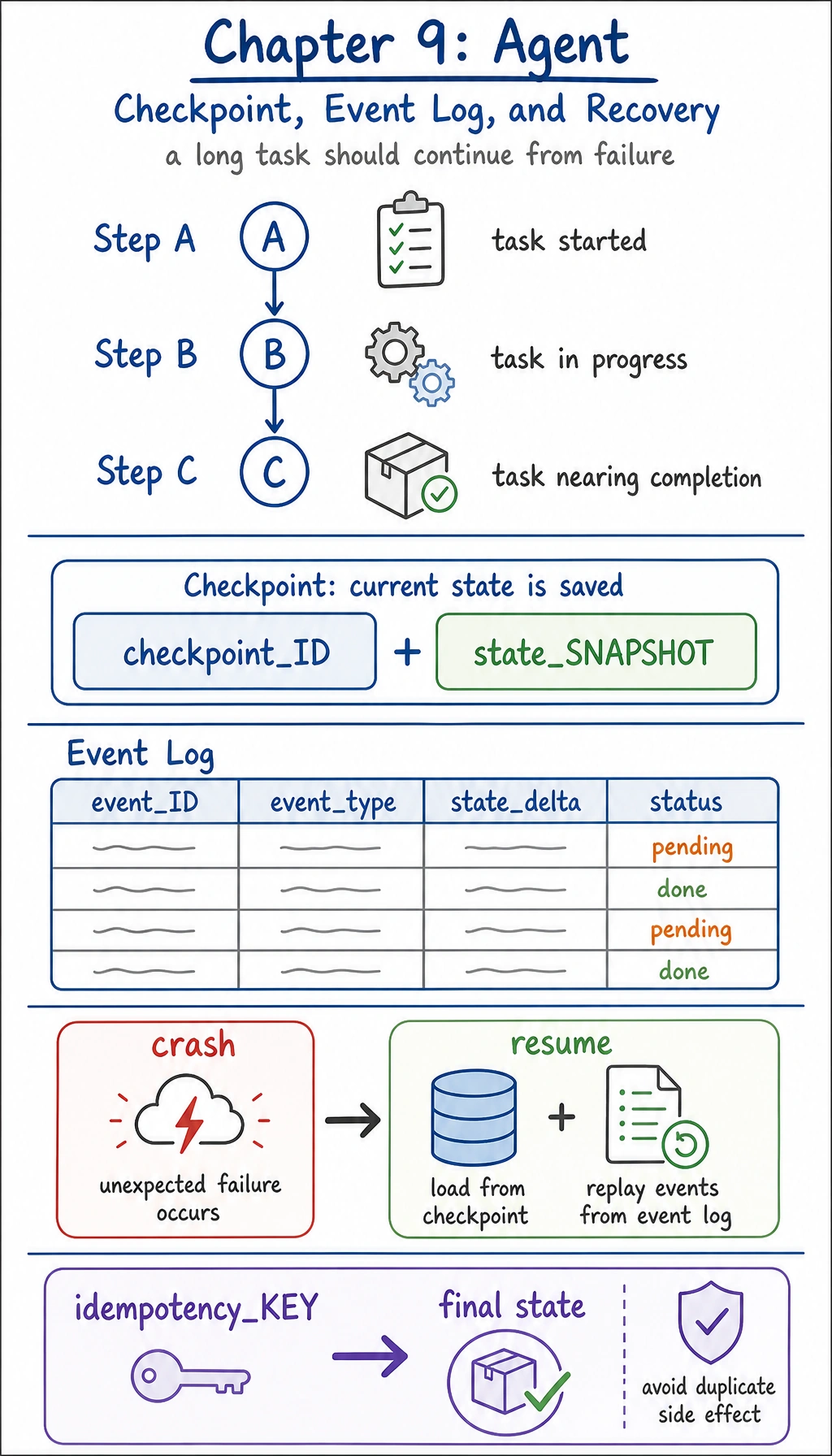
What exactly is being persisted?
Section titled “What exactly is being persisted?”The most important thing is task state
Section titled “The most important thing is task state”For example:
- Which step execution is currently on
- Which steps have been completed
- What the intermediate results are
Next comes the event log
Section titled “Next comes the event log”The event log answers:
- What exactly happened before?
For example:
- Which tool was called
- What response was received
- Which step failed
The difference between snapshots and logs
Section titled “The difference between snapshots and logs”You can remember it like this:
checkpoint / snapshot: a compressed slice of the current stateevent log: the stream of events that happened along the way
In real engineering, these two are often used together.
First, run a minimal recovery workflow
Section titled “First, run a minimal recovery workflow”The example below simulates a three-step task:
- Read materials
- Generate a summary
- Write the report
The system writes a checkpoint after each step. If a failure occurs in step 2, it continues from the last checkpoint.
import copy
TASK_PLAN = ["load_data", "summarize", "write_report"]
def execute_step(step, state): if step == "load_data": state["data"] = ["refund policy", "invoice policy", "address change policy"] elif step == "summarize": state["summary"] = ";".join(state["data"]) elif step == "write_report": state["report"] = f"Final report: {state['summary']}" return state
class WorkflowRunner: def __init__(self): self.event_log = [] self.last_checkpoint = None
def checkpoint(self, state): self.last_checkpoint = copy.deepcopy(state)
def log_event(self, event_type, payload): self.event_log.append({"type": event_type, "payload": copy.deepcopy(payload)})
def run(self, fail_on_step=None): state = self.last_checkpoint or {"current_index": 0, "completed_steps": []}
while state["current_index"] < len(TASK_PLAN): step = TASK_PLAN[state["current_index"]] self.log_event("step_started", {"step": step, "state": state})
if step == fail_on_step: self.log_event("step_failed", {"step": step}) raise RuntimeError(f"crash_on_{step}")
state = execute_step(step, state) state["completed_steps"].append(step) state["current_index"] += 1
self.checkpoint(state) self.log_event("step_completed", {"step": step, "state": state})
return state
runner = WorkflowRunner()
try: runner.run(fail_on_step="summarize")except RuntimeError as e: print("first run crashed:", e)
print("checkpoint after crash:", { "current_index": runner.last_checkpoint["current_index"], "completed_steps": runner.last_checkpoint["completed_steps"],})
final_state = runner.run()print("\nrestored final state:")print({ "completed_steps": final_state["completed_steps"], "report": final_state["report"],})
print("\nevent types:")print([event["type"] for event in runner.event_log])Expected output:
first run crashed: crash_on_summarizecheckpoint after crash: {'current_index': 1, 'completed_steps': ['load_data']}
restored final state:{'completed_steps': ['load_data', 'summarize', 'write_report'], 'report': 'Final report: refund policy;invoice policy;address change policy'}
event types:['step_started', 'step_completed', 'step_started', 'step_failed', 'step_started', 'step_completed', 'step_started', 'step_completed']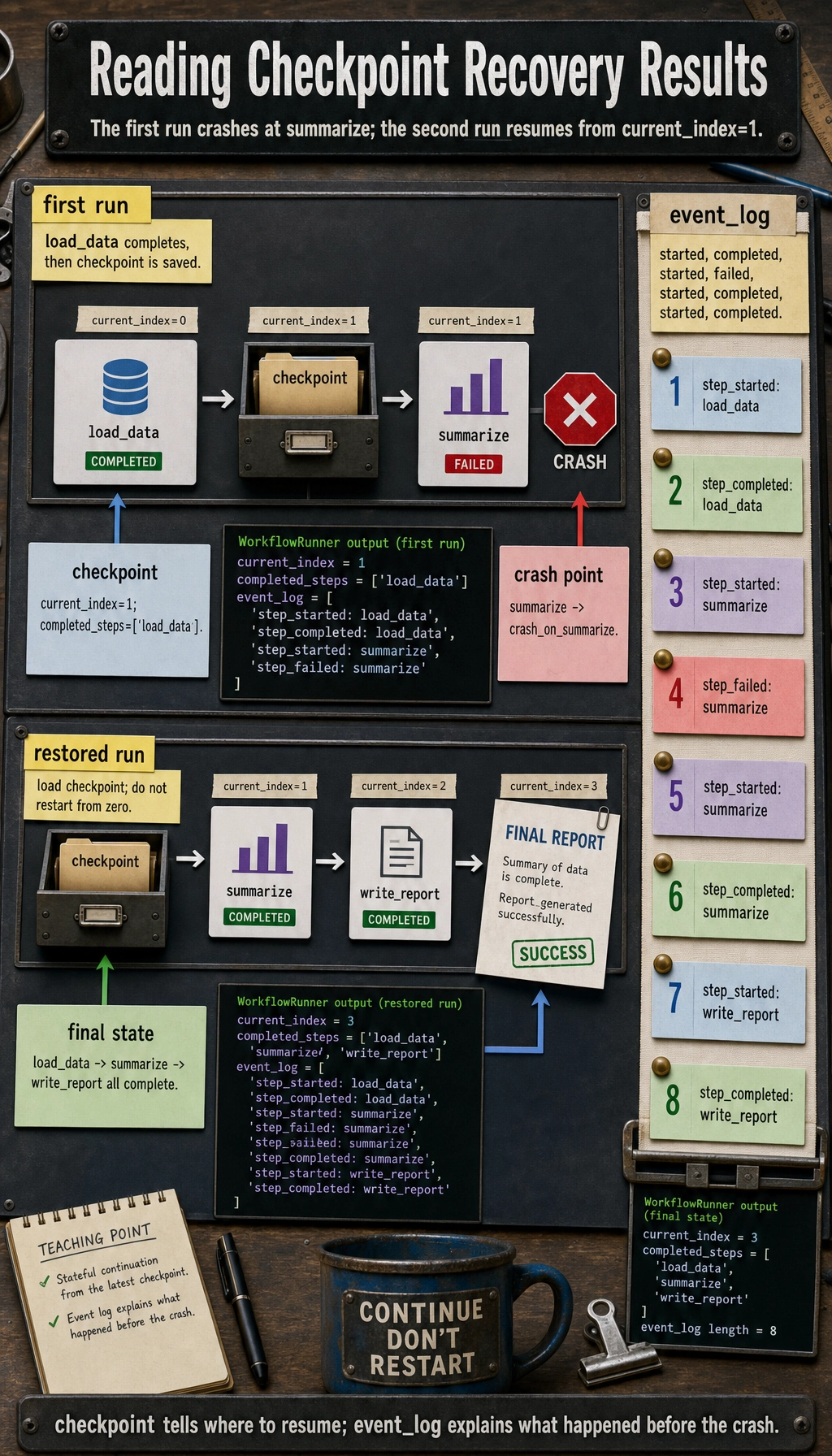
What is the most important thing to learn from this example?
Section titled “What is the most important thing to learn from this example?”It connects the three most important pieces in the recovery path:
- Write a checkpoint after each step
- Keep an event log when errors happen
- After restart, continue from the last checkpoint
Why not write the checkpoint only at the end of the task?
Section titled “Why not write the checkpoint only at the end of the task?”Because if the task crashes midway, you still cannot recover anything.
So for long tasks, a more practical choice is:
- Step-level checkpoints
Why is the event log important?
Section titled “Why is the event log important?”A checkpoint can only tell you “what the current state is,” but it cannot fully explain:
- Why it became that state
- Where the failure happened
Logs help with postmortems and debugging.
Why is idempotency the core of the recovery path?
Section titled “Why is idempotency the core of the recovery path?”What does idempotent mean?
Section titled “What does idempotent mean?”Idempotency can be roughly understood as:
- Repeating the same action multiple times still produces the same result
Why is it especially needed during recovery?
Section titled “Why is it especially needed during recovery?”If the system crashes before “writing the report,” after restarting you may not know:
- Whether this step was actually completed
If the action is not idempotent, it can lead to:
- Duplicate writes
- Duplicate charges
- Duplicate messages
A simplified example
Section titled “A simplified example”processed = set()
def send_email_once(task_id, address): if task_id in processed: return {"ok": True, "status": "skipped_duplicate"} processed.add(task_id) return {"ok": True, "status": f"sent_to:{address}"}
Expected output:
{'ok': True, 'status': 'sent_to:[email protected]'}{'ok': True, 'status': 'skipped_duplicate'}This is the simplest idea behind idempotency protection.
What do people most often forget when designing recovery?
Section titled “What do people most often forget when designing recovery?”Storing only the “result,” not the “progress”
Section titled “Storing only the “result,” not the “progress””If you only store the summary and do not store:
- Which step you are currently on
then recovery still remains difficult.
Storing only checkpoints, not logs
Section titled “Storing only checkpoints, not logs”This allows recovery, but makes it hard to investigate why the failure happened.
External side effects have no idempotency key
Section titled “External side effects have no idempotency key”This makes recovery risky, because the system cannot tell whether replaying will create duplicate side effects.
How is this usually done in real systems?
Section titled “How is this usually done in real systems?”State table
Section titled “State table”Store:
- Task id
- Current step
- Current state snapshot
- Update time
Event table
Section titled “Event table”Store:
- Event type
- Time
- Input/output summary
- Error information
Recovery service
Section titled “Recovery service”Responsible for:
- Scanning unfinished tasks on restart
- Loading the latest checkpoint
- Continuing from a safe point
Most common misconceptions
Section titled “Most common misconceptions”Misconception 1: If there is a database, then it is “recoverable”
Section titled “Misconception 1: If there is a database, then it is “recoverable””Not true. The key is whether you have stored:
- Enough information to recover
Misconception 2: Recovery just means “run it again”
Section titled “Misconception 2: Recovery just means “run it again””Running it again often causes duplicate side effects. Recovery is not redoing; it is continuing statefully.
Misconception 3: Only very long tasks need recovery
Section titled “Misconception 3: Only very long tasks need recovery”As long as a task includes external side effects or multi-step execution, recovery capability is important.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Runtime
- queues, workers, state store, tool services, and model endpoint
- Persistence
- checkpoints, event log, memory store, and recovery path
- Ops Signal
- latency, cost, error rate, trace coverage, and saturation
- Failure Check
- stuck run, duplicate action, partial failure, or runaway cost
- Recovery Action
- resume, rollback, cancel, human handoff, or degrade gracefully
Summary
Section titled “Summary”The most important thing in this lesson is to build a production-grade judgment:
Persistence and recovery for an Agent is not simply writing the result to disk. It is about using checkpoints, event logs, and idempotency mechanisms to let a task continue safely after failures.
Once this chain is designed clearly, the system moves from a demo that “sometimes works” to a production system that can still continue after failures.
Exercises
Section titled “Exercises”- Add a
retry_countfield to the example to record the number of retries for each step. - Change
write_reportinto an action with external side effects, then think about how idempotency should be implemented. - Why do we say checkpoint and event log are both indispensable in recovery?
- If a task is especially long, would you choose a checkpoint after every step, or every few steps? Why?
Reference implementation and walkthrough
retry_countshould be stored per step, not only per whole run. That lets you see which step is unstable and prevents a retry storm from being hidden inside one final status.- If
write_reporthas external side effects, make it idempotent with a stable operation id, existence checks, deduplication, and a record of whether the external write already succeeded. - Checkpoints give you the latest resumable state; event logs explain how the system reached that state. Recovery needs both the snapshot and the history of decisions and side effects.
- For long tasks, checkpoint after important irreversible or expensive steps, and every few low-risk steps. Checkpointing every step is safest but may add storage and latency overhead.