6.5.3 Transformer Architecture
Learning Objectives
Section titled “Learning Objectives”- Read a Transformer block as an executable data flow.
- Explain residual connections, LayerNorm, and FFN without memorizing layer names.
- Run PyTorch examples that show the main shapes.
- Distinguish encoder-only, decoder-only, and encoder-decoder models.
- Understand why modern LLM decoders use pre-norm, RMSNorm, RoPE, GQA/MQA, and SwiGLU.
Start with the Block Picture
Section titled “Start with the Block Picture”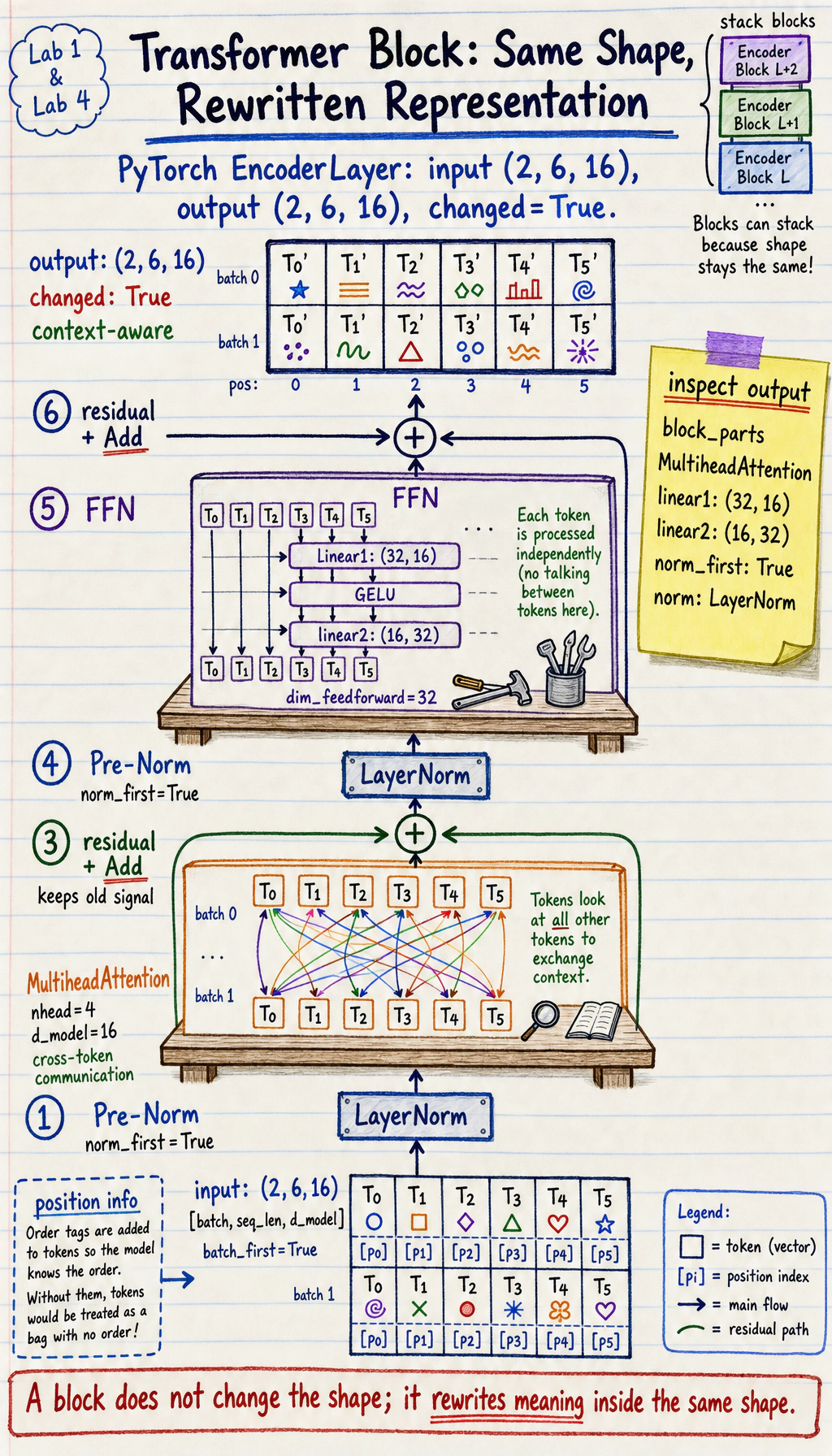
A Transformer block usually keeps the outer shape:
[batch, seq_len, d_model] -> [batch, seq_len, d_model]The shape often stays the same, but the representation becomes more context-aware.
| Part | What it does | Why it matters |
|---|---|---|
| Multi-head attention | mixes information across token positions | builds context |
| Residual connection | adds the input back | protects information and gradients |
| LayerNorm / RMSNorm | stabilizes feature scale | makes deep training easier |
| FFN | transforms each position independently | adds nonlinear processing power |
| Position information | tells the model token order | attention alone is order-light |
Lab 1: Inspect a PyTorch Transformer Block
Section titled “Lab 1: Inspect a PyTorch Transformer Block”import torchfrom torch import nn
torch.manual_seed(42)
layer = nn.TransformerEncoderLayer( d_model=16, nhead=4, dim_feedforward=32, batch_first=True, norm_first=True, dropout=0.0,)
print("block_parts")print(type(layer.self_attn).__name__)print("linear1:", tuple(layer.linear1.weight.shape))print("linear2:", tuple(layer.linear2.weight.shape))print("norm_first:", layer.norm_first)print("norm:", type(layer.norm1).__name__)Expected output:
block_partsMultiheadAttentionlinear1: (32, 16)linear2: (16, 32)norm_first: Truenorm: LayerNormRead the parameters:
d_model=16: every token representation has 16 features.nhead=4: attention is split into 4 heads.dim_feedforward=32: the FFN expands from 16 to 32, then projects back.batch_first=True: tensors use[batch, seq_len, d_model].norm_first=True: use pre-norm, a common stable pattern for deep stacks.
Residual and Normalization
Section titled “Residual and Normalization”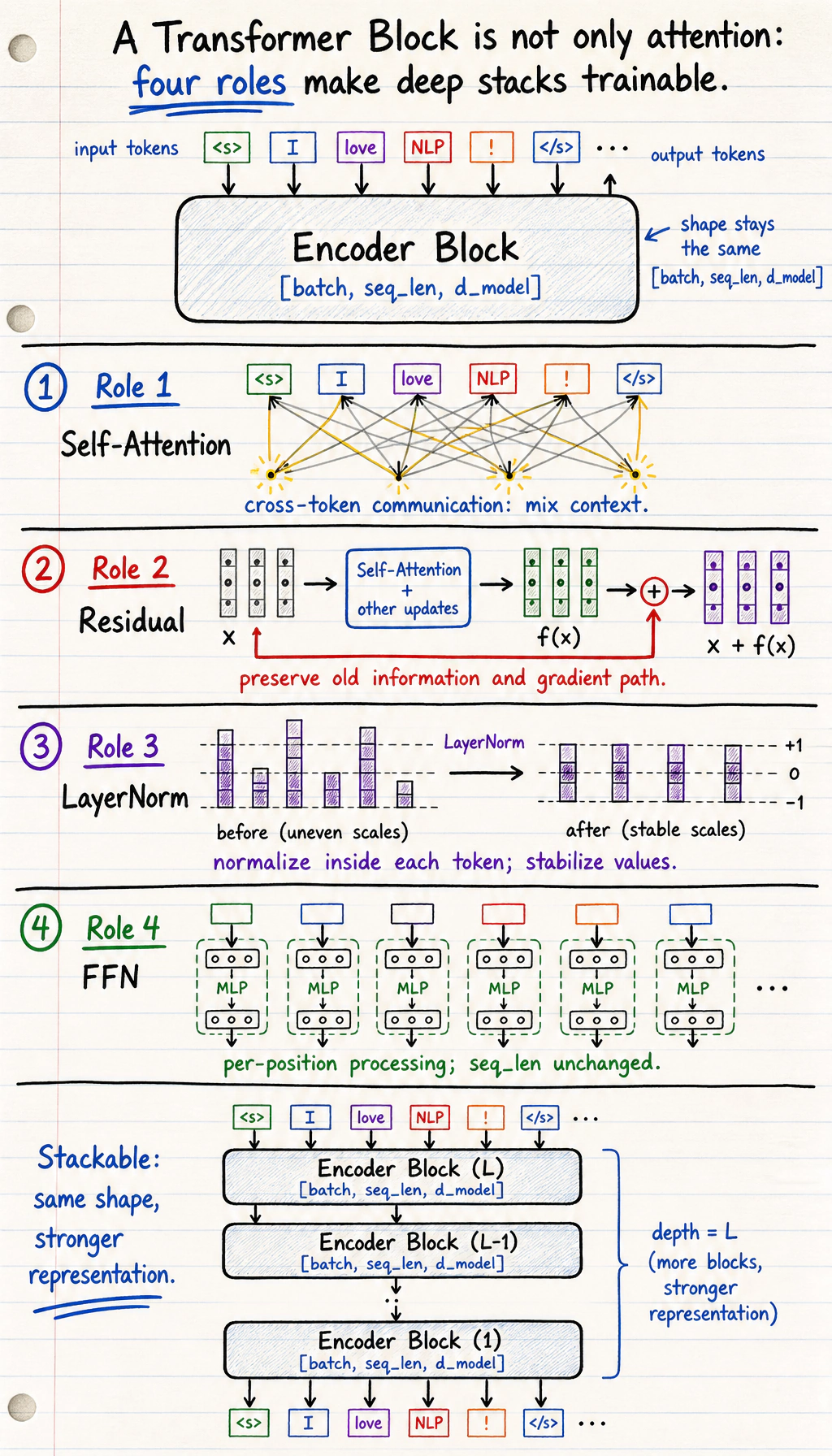
Residual connections and normalization are not decoration. They are what let the block become deep without losing the original signal or exploding into unstable values.
Lab 2: Residual Connection
Section titled “Lab 2: Residual Connection”import torch
x = torch.tensor([[1.0, 2.0, 3.0]])f_x = torch.tensor([[0.1, -0.2, 0.3]])
y = x + f_x
print("residual_lab")print(y)Expected output:
residual_labtensor([[1.1000, 1.8000, 3.3000]])The layer only needs to learn a useful update f(x). The old representation x is still available through the shortcut.
Lab 3: LayerNorm
Section titled “Lab 3: LayerNorm”import torchfrom torch import nn
x = torch.tensor( [ [1.0, 2.0, 3.0, 10.0], [2.0, 2.5, 3.5, 9.0], ])
ln = nn.LayerNorm(4)y = ln(x)
print("layernorm_lab")print(torch.round(y.detach(), decimals=3))print("row_means:", torch.round(y.mean(dim=1).detach(), decimals=4))print("row_stds:", torch.round(y.std(dim=1, unbiased=False).detach(), decimals=4))Expected output:
layernorm_labtensor([[-0.8490, -0.5660, -0.2830, 1.6970], [-0.8050, -0.6260, -0.2680, 1.6990]])row_means: tensor([0., 0.])row_stds: tensor([1., 1.])LayerNorm normalizes across the feature dimension for each token. It does not normalize across the batch.
FFN: Same Position, Stronger Transformation
Section titled “FFN: Same Position, Stronger Transformation”Attention mixes information across positions. The feed-forward network processes each position independently after that mixing.
import torchfrom torch import nn
torch.manual_seed(42)
x = torch.randn(2, 5, 8)
ffn = nn.Sequential( nn.Linear(8, 32), nn.GELU(), nn.Linear(32, 8),)
y = ffn(x)
print("ffn_lab")print("input:", tuple(x.shape))print("output:", tuple(y.shape))Expected output:
ffn_labinput: (2, 5, 8)output: (2, 5, 8)The FFN expands the hidden size internally, then projects back. Sequence length does not change.
Position Information
Section titled “Position Information”Self-attention can compare tokens, but it does not naturally know whether a token is first, second, or last. Position information fixes that.
import torch
positions = torch.arange(5).float().unsqueeze(1)dims = torch.arange(0, 8, 2).float()angle_rates = 1 / (10000 ** (dims / 8))angles = positions * angle_rates
pe = torch.zeros(5, 8)pe[:, 0::2] = torch.sin(angles)pe[:, 1::2] = torch.cos(angles)
print("positional_lab")print(torch.round(pe[:3], decimals=4))Expected output:
positional_labtensor([[ 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000], [ 0.8415, 0.5403, 0.0998, 0.9950, 0.0100, 1.0000, 0.0010, 1.0000], [ 0.9093, -0.4161, 0.1987, 0.9801, 0.0200, 0.9998, 0.0020, 1.0000]])Modern LLMs often use RoPE instead of this classic sinusoidal style. The practical goal is the same: give attention a usable sense of order and relative distance.
Lab 4: Run One Encoder Block
Section titled “Lab 4: Run One Encoder Block”import torchfrom torch import nn
torch.manual_seed(42)
encoder_layer = nn.TransformerEncoderLayer( d_model=16, nhead=4, dim_feedforward=32, batch_first=True, norm_first=True, dropout=0.0,)
tokens = torch.randn(2, 6, 16)out = encoder_layer(tokens)
print("encoder_shape_lab")print("input:", tuple(tokens.shape))print("output:", tuple(out.shape))print("changed:", bool(torch.not_equal(tokens, out).any()))Expected output:
encoder_shape_labinput: (2, 6, 16)output: (2, 6, 16)changed: TrueThe shape stays the same, but every token has been rewritten with context from other tokens.
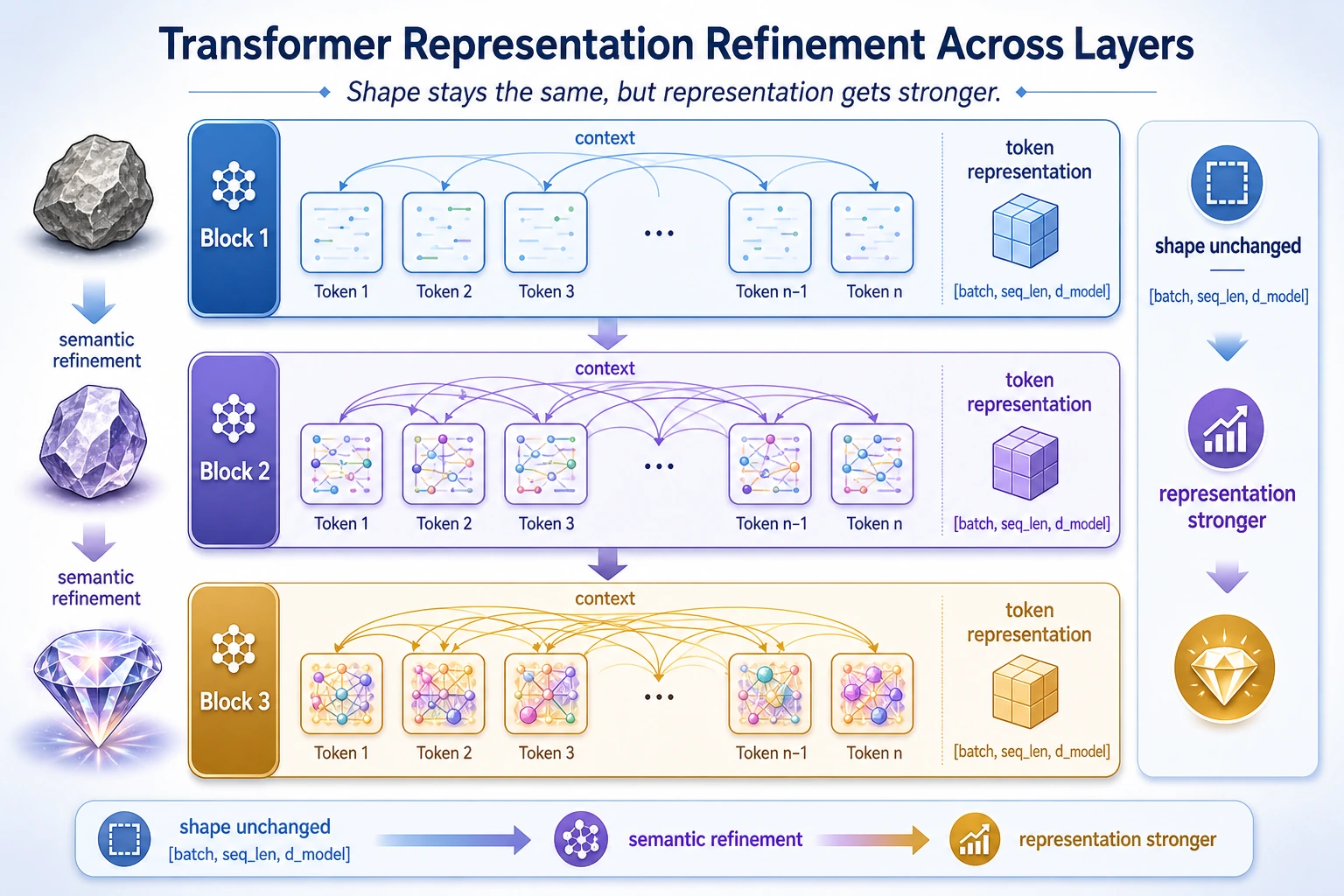
Encoder, Decoder, and Encoder-Decoder
Section titled “Encoder, Decoder, and Encoder-Decoder”| Family | Typical model | Main use | Attention pattern |
|---|---|---|---|
| Encoder-only | BERT | understanding and classification | bidirectional self-attention |
| Decoder-only | GPT-style LLMs | generation | causal self-attention |
| Encoder-decoder | T5, original Transformer | read one sequence, generate another | encoder self-attention plus decoder cross-attention |
Lab 5: Decoder Shape and Cross-Attention
Section titled “Lab 5: Decoder Shape and Cross-Attention”import torchfrom torch import nn
torch.manual_seed(42)
decoder_layer = nn.TransformerDecoderLayer( d_model=16, nhead=4, dim_feedforward=32, batch_first=True, norm_first=True, dropout=0.0,)
target = torch.randn(2, 3, 16)memory = torch.randn(2, 5, 16)causal_mask = nn.Transformer.generate_square_subsequent_mask(target.size(1))
out = decoder_layer(target, memory, tgt_mask=causal_mask)
print("decoder_shape_lab")print("target:", tuple(target.shape))print("memory:", tuple(memory.shape))print("mask:", tuple(causal_mask.shape))print("output:", tuple(out.shape))Expected output:
decoder_shape_labtarget: (2, 3, 16)memory: (2, 5, 16)mask: (3, 3)output: (2, 3, 16)Read it this way:
targetis what the decoder has generated so far.memoryis the encoder output.causal_maskprevents future peeking inside the decoder.- Cross-attention lets the decoder look at the encoded input.
Early Transformer vs Modern LLM Decoder
Section titled “Early Transformer vs Modern LLM Decoder”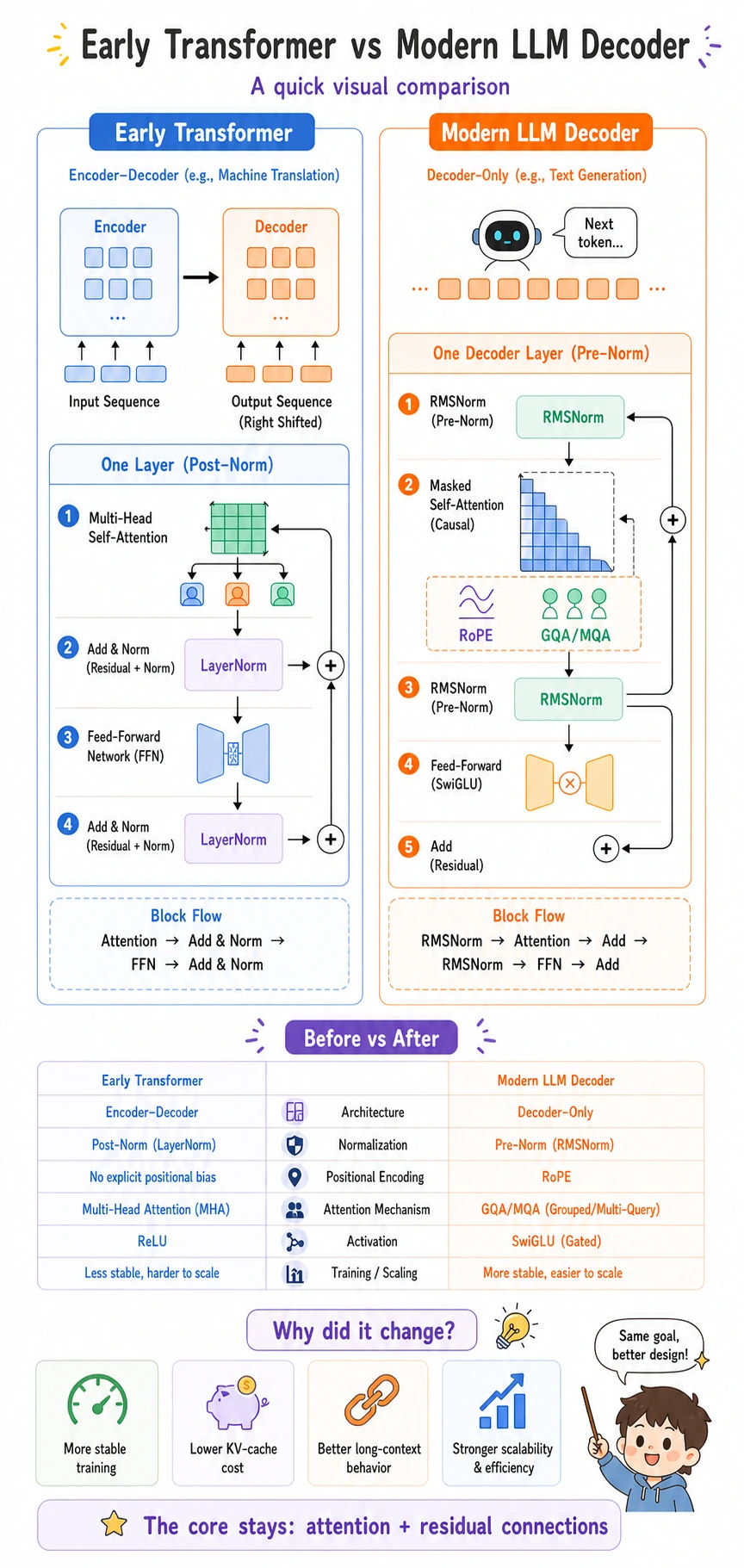
| Part | Early Transformer | Modern LLM decoder | Why it changed |
|---|---|---|---|
| Normalization | LayerNorm after attention/FFN | pre-norm, often RMSNorm | deep stacks train more stably |
| Position signal | absolute or sinusoidal position | RoPE | better relative-position behavior |
| Attention heads | full multi-head attention | GQA or MQA in many models | lower KV-cache memory during inference |
| FFN | ReLU/GELU FFN | often SwiGLU-style gated FFN | stronger scaling behavior |
| Architecture | often encoder-decoder | often decoder-only | next-token prediction scales well |
Plain-language terms:
- RMSNorm: normalize feature scale with root mean square, often cheaper than full LayerNorm.
- RoPE: rotate position information into attention so relative distance is easier to use.
- GQA: grouped-query attention, where groups of query heads share key/value heads.
- MQA: multi-query attention, where many query heads share one key/value set.
- SwiGLU: a gated FFN that controls how much transformed information passes through.
The key idea:
Original Transformer proved the block pattern.Modern LLM decoders changed the block so very deep generation models train and infer efficiently.Bridge to LLMs: From Block Output to Next Token
Section titled “Bridge to LLMs: From Block Output to Next Token”A Transformer block does not directly “answer” the user. It rewrites token representations. A decoder-only LLM stacks many such blocks, then maps the final representation to vocabulary scores.
tokens-> embeddings + position-> repeated decoder blocks-> final hidden states-> vocabulary logits-> next-token choiceRead the last two steps carefully:
| Step | Plain meaning | Why it matters in Chapter 7 |
|---|---|---|
| vocabulary logits | one score for each possible next token | this is where the model ranks possible continuations |
| decoding | choose or sample the next token from those scores | temperature, top-p, and stop rules change visible behavior |
So the bridge is:
Chapter 6: how blocks rewrite representations.Chapter 7: how rewritten representations become generated text.This also explains why prompts matter. A prompt changes the input tokens and context, which changes the hidden states, which changes the next-token scores.
Evidence to Keep
Section titled “Evidence to Keep”Keep one Transformer block card:
- Block Shape
- [batch, seq_len, d_model] stays the same
- Content Change
- token representations become context-aware
- Stability Parts
- residual + norm
- Token Parts
- attention mixes positions, FFN transforms each position
- Generation Bridge
- final hidden state → vocabulary logits → next token
Common Mistakes
Section titled “Common Mistakes”| Mistake | Fix |
|---|---|
| thinking Transformer is only attention | include residual, normalization, FFN, and position information |
| reading only tensor shape | remember the representation content changes even when shape stays the same |
| confusing encoder and decoder | check whether future tokens are visible and whether cross-attention exists |
ignoring batch_first | always confirm whether tensors are [batch, seq, dim] or [seq, batch, dim] |
| treating modern LLM blocks as identical to the 2017 block | learn pre-norm, RMSNorm, RoPE, GQA/MQA, and gated FFNs |
Exercises
Section titled “Exercises”- Change
d_modelto32in Lab 4. Which other parameters must change? - In Lab 1, set
norm_first=False. What architectural pattern does this represent? - Explain why the FFN output shape matches the input shape even though it expands internally.
- In Lab 5, change
targetlength from3to4. What must happen tocausal_mask? - Describe why GQA/MQA helps inference memory in one paragraph.
Reference implementation and walkthrough
- Embeddings, positional encodings, attention layers, and FFN input/output dimensions must agree with
d_model=32. Also make surenheaddivides32. norm_first=Falserepresents the post-norm Transformer block style, where normalization happens after the residual addition.- The FFN expands the hidden dimension internally, applies a nonlinearity, then projects back to
d_model, so the residual path can add it to the original tensor. - The target sequence length becomes
4, so the causal mask must become a compatible4 x 4mask that blocks future target positions. - GQA/MQA shares or reduces key/value heads, which shrinks the KV cache during autoregressive decoding. That saves memory bandwidth and makes long-context inference cheaper.
Key Takeaways
Section titled “Key Takeaways”- A Transformer block is attention plus stability and transformation machinery.
- Residual connections preserve old information while layers learn updates.
- Normalization keeps deep stacks trainable.
- FFN transforms each token after attention has mixed context.
- Modern LLM decoders keep the Transformer idea but optimize it for scale and inference.