13.3 Model and Runtime Decision
A good open-source LLM project starts before the first download. This lesson turns model selection into a written decision so you do not waste time on a model that your hardware, license, latency target, or product boundary cannot support.
What This Page Solves
Section titled “What This Page Solves”The beginner mistake is to ask, “Which model is best?” The engineering question is more specific: “Which model/runtime pair is enough for this project, on this hardware, with this license and rollback path?”
Use the smallest model and simplest runtime that proves the project behavior. Move upward only when evidence shows that quality, context length, throughput, privacy, or cost requires it.
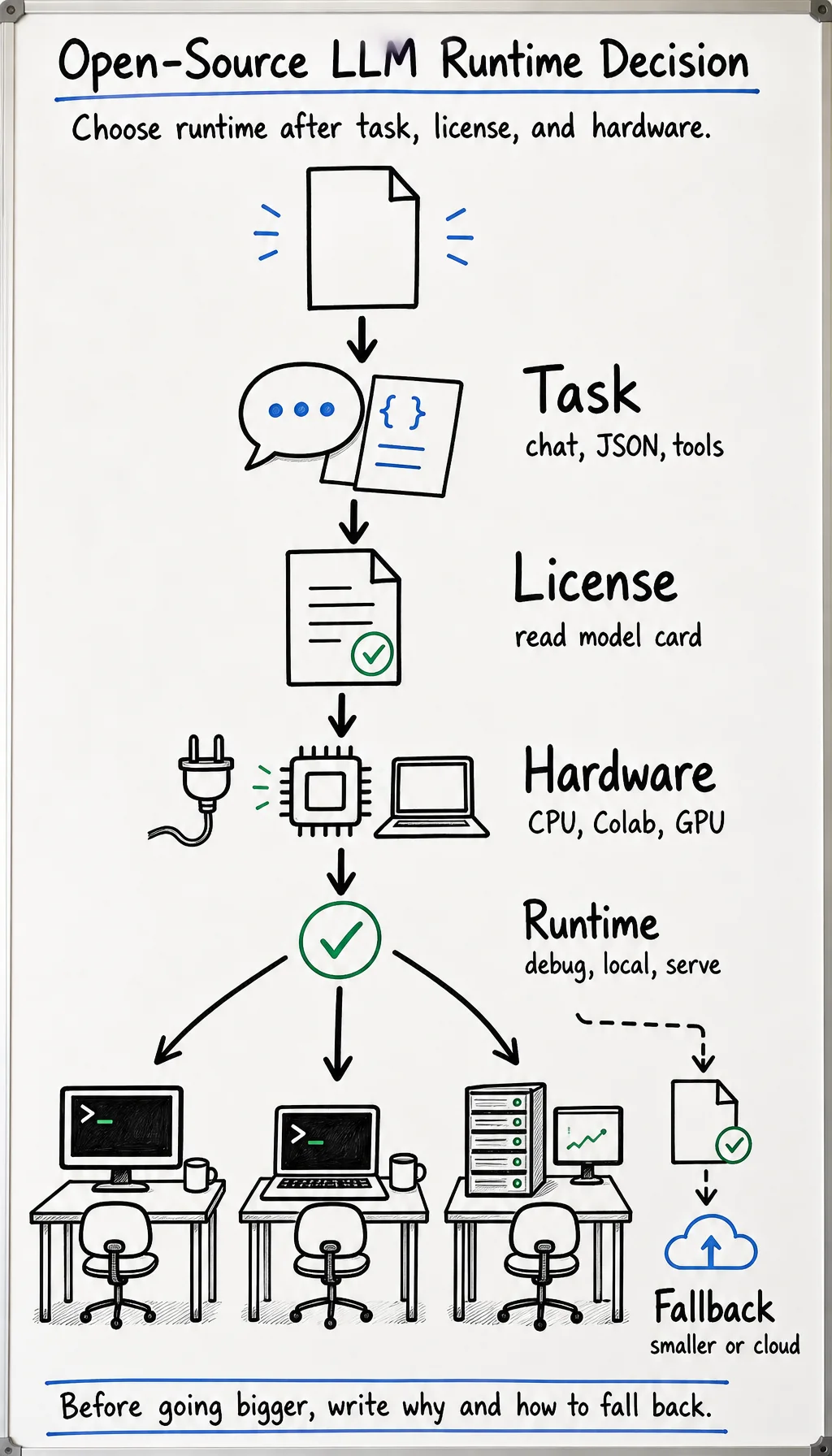
The Decision Ladder
Section titled “The Decision Ladder”-
Task fit Decide whether the project needs chat, extraction, code, multilingual support, long context, tool calling, or multimodal behavior.
-
License fit Read the model card and license before building around the model. Keep a note for commercial use, redistribution, and data-use restrictions.
-
Hardware fit Estimate VRAM/RAM and disk before download. If the model cannot run locally, choose a smaller model, quantization, a rented GPU, or a cloud API fallback.
-
Runtime fit Use Transformers for learning, Ollama/LM Studio for local handoff, llama.cpp for quantized CPU/edge tests, and vLLM/SGLang for server-style inference.
-
Evidence fit Do not call the decision complete until you have model version, command, first output, evaluation table, and stop procedure.
Model Decision Table
Section titled “Model Decision Table”Create model_runtime_decision.md:
# Model Runtime Decision
project_goal: support-operations SOP assistantmust_have: private document handling, Chinese/English answers, stable JSON outputnice_to_have: low latency, long context, OpenAI-compatible endpoint
candidate_1: Qwen2.5-0.5B-Instructlicense_note: check model card before deploymentruntime: vLLM when GPU is available, Transformers for first local testhardware_note: small enough for first experiment; still validate memoryrisk: quality may be too weak for complex SOP reasoning
candidate_2: 7B instruct modellicense_note: check commercial and redistribution termsruntime: vLLM or SGLang on rented GPUhardware_note: requires planned GPU budget and shutdown proofrisk: higher cost and slower iteration
fallback: cloud model API or RAG with current API modelwhy_now: prove the deployment loop before chasing larger modelsrejected_for_now: full fine-tuning, because eval failures are not proven yetThe exact model names can change. The decision shape should not change.
Runtime Selection Rules
Section titled “Runtime Selection Rules”Start with Transformers when you need to inspect tokens, prompts, and Python behavior. It is easy to debug and close to the model API, but it is not usually the final high-throughput server.
Use Ollama or LM Studio when the goal is a laptop demo or non-engineer handoff. They lower setup friction, but you give up some production control.
Use llama.cpp when CPU, quantized, or edge constraints matter. It is strong for small local experiments, but you still need a clear API and evaluation story.
Use vLLM when the project needs OpenAI-compatible serving and throughput. Do not start here until GPU, driver, memory, and security posture are clear.
Use SGLang when structured generation or agentic serving patterns matter. It is powerful, but it should still be justified by project requirements rather than novelty.
Route-Specific Runtime Cards
Section titled “Route-Specific Runtime Cards”Use these cards to keep the three compute routes honest. The route changes what the first proof can claim, so each card separates the model, runtime, evidence, and upgrade signal.
Local CPU
- First Model
sshleifer/tiny-gpt2or a small quantized model.- Runtime
- Transformers for inspection; llama.cpp or Ollama for quantized local tests.
- First Proof
- Environment, download, one prompt, eval script, and local API skeleton.
- Upgrade Signal
- The loop is reproducible, but quality is too weak for the target task.
Free Colab
- First Model
- Tiny model first, then a small instruct model only if GPU is visible.
- Runtime
- Transformers notebook with saved files that can be copied back locally.
- First Proof
- The notebook can rerun, outputs are saved, and GPU use is optional.
- Upgrade Signal
- GPU is visible and fixed eval cases justify trying a larger model.
Rented GPU
- First Model
- Small instruct model before trying a 7B-class model.
- Runtime
- vLLM or SGLang behind localhost or an SSH tunnel.
- First Proof
- Known VRAM, endpoint, eval table, latency note, and shutdown proof.
- Upgrade Signal
- Fixed eval cases pass and service behavior, not only one-off generation, matters.
Do not compare routes as if they prove the same thing. Local CPU proves the workflow. Colab proves a portable notebook path. Rented GPU proves controlled serving and cost discipline.
Write a Runnable Decision Helper
Section titled “Write a Runnable Decision Helper”Create choose_openllm_runtime.py. It does not download a model. It forces the decision to depend on task, privacy, route, and available memory.
import jsonimport osfrom pathlib import Path
profile = { "task": os.environ.get("TASK", "course assistant"), "route": os.environ.get("ROUTE", "local_cpu"), "privacy": os.environ.get("PRIVACY", "private_docs"), "available_vram_gb": float(os.environ.get("VRAM_GB", "0")), "needs_service": os.environ.get("NEEDS_SERVICE", "no") == "yes",}
def choose(profile): route = profile["route"] vram = profile["available_vram_gb"]
if route == "local_cpu": return { "model": "sshleifer/tiny-gpt2 or a small quantized model", "runtime": "Transformers for code inspection; llama.cpp/Ollama for quantized local tests", "claim": "proves the workflow, not model quality", }
if route == "free_colab": return { "model": "tiny model first; small instruct model only if GPU is visible", "runtime": "Transformers notebook", "claim": "proves a portable notebook run, not stable serving", }
if route == "rented_gpu" and vram >= 16: runtime = "vLLM or SGLang" if profile["needs_service"] else "Transformers first, then vLLM" return { "model": "small instruct model before trying 7B-class", "runtime": runtime, "claim": "proves controlled serving, eval, latency, and shutdown", }
return { "model": "smaller model or cloud API fallback", "runtime": "do not start GPU serving yet", "claim": "current hardware route is not ready", }
decision = {"profile": profile, "decision": choose(profile)}Path("model_runtime_decision.json").write_text(json.dumps(decision, indent=2), encoding="utf-8")print(json.dumps(decision, indent=2))Run one route at a time:
ROUTE=local_cpu python choose_openllm_runtime.pyROUTE=free_colab python choose_openllm_runtime.pyROUTE=rented_gpu VRAM_GB=24 NEEDS_SERVICE=yes python choose_openllm_runtime.pyThe output is not a final architecture. It is a guardrail against choosing a model name before the route, memory, service need, and evidence claim are clear.
Mini Exercise
Section titled “Mini Exercise”Take a project from Chapter 8 or 9 and write one decision paragraph:
For this project, I will start with _____ using _____ because _____.I will not use a larger model yet because _____.I will switch only if the fixed eval set shows _____.Decision reasoning and explanation
A strong answer ties model size and runtime to evidence. For example: start with a small instruct model through Transformers or Ollama to prove prompts, RAG context, and output schema. Move to vLLM only after the same eval cases show acceptable quality and the project needs a service endpoint. Do not choose LoRA or a larger GPU before you know which failures remain after prompt, RAG, schema, and quantization choices.
Evidence to Keep
Section titled “Evidence to Keep”- Model Decision
- selected model, license note, size, context length, and rejected alternatives
- Runtime Decision
- chosen runtime, hardware reason, and fallback runtime
- Hardware Note
- local CPU/GPU or rented GPU estimate, disk, and expected stop time
- Eval Gate
- fixed cases that would justify changing model or runtime
- Expected Output
- model_runtime_decision.md, model_runtime_decision.json, and one first-run command
Pass Check
Section titled “Pass Check”You pass this lesson when you can explain why your model/runtime pair is enough for the current project, what would make you upgrade, and what evidence prevents a random model demo from becoming an uncontrolled deployment.