E.A.3 Model Optimization Techniques
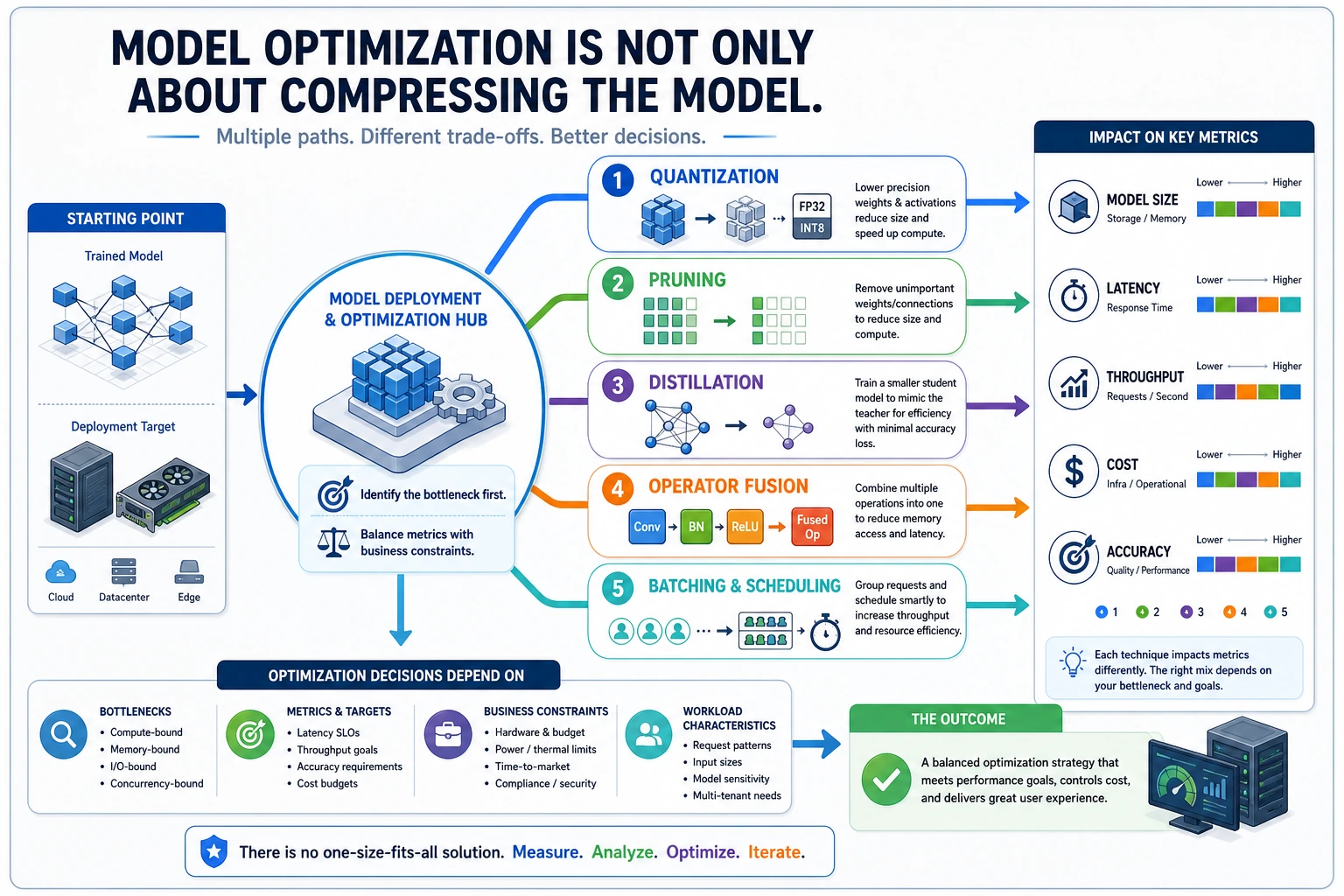
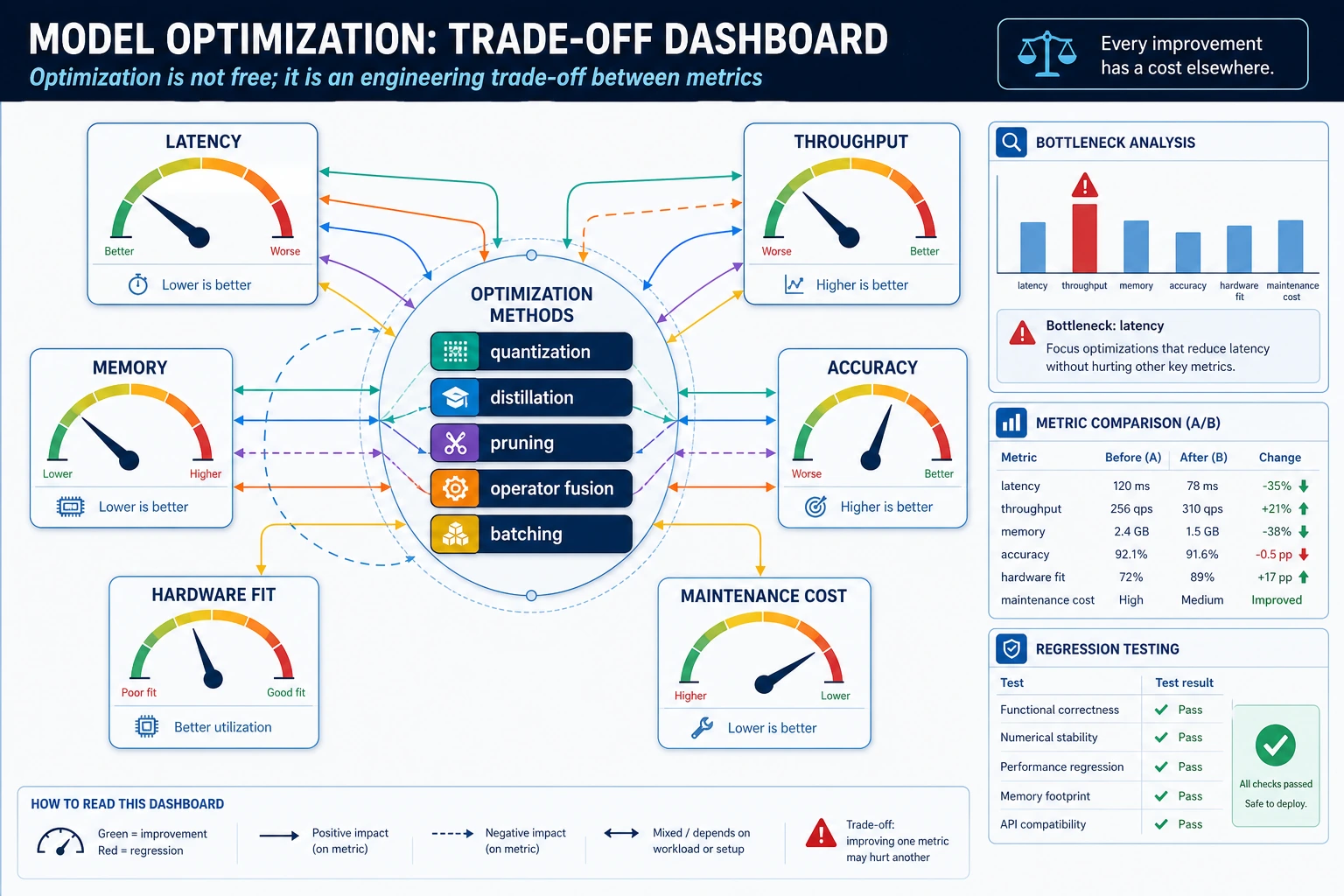
Optimization does not mean “make the model as small as possible.” It means improving one constraint while checking what you lose.
Run a tiny quantization-error check
Section titled “Run a tiny quantization-error check”values = [0.1234, 0.5678, 0.9012]quantized = [round(value * 255) / 255 for value in values]errors = [abs(original - compressed) for original, compressed in zip(values, quantized)]
print([round(value, 4) for value in quantized])print(f"max_error={max(errors):.4f}")Expected output:
[0.1216, 0.5686, 0.902]max_error=0.0018This is the smallest optimization habit: compress, measure the error, and decide whether the error is acceptable.
Choose the right optimization path
Section titled “Choose the right optimization path”| Technique | Best when | Check before shipping |
|---|---|---|
| Quantization | Latency and memory are too high | Accuracy drop on real validation cases |
| Pruning | Many weights or channels are not useful | Whether the runtime actually speeds up |
| Distillation | A smaller model can imitate a larger one | Whether the compact model fails on edge cases |
| Operator fusion | Runtime overhead is high | Whether your engine supports the fused graph |
| Batching / scheduling | Many requests arrive together | Latency tail and queue delay |
Practical order
Section titled “Practical order”- Measure baseline latency, memory, and accuracy.
- Try one optimization at a time.
- Record before/after metrics.
- Keep failure examples.
- Only ship when the trade-off is visible.
Optimization Review
Section titled “Optimization Review”Treat every optimization as an experiment with a control group. The baseline is the control. The optimized model is the candidate. If you change quantization, batching, and runtime at the same time, you will not know which change helped or hurt. Keep the comparison narrow enough that a teammate can rerun it.
The minimum review note should include four fields: what changed, which metric improved, which metric got worse or stayed risky, and which validation examples were checked. For example: “INT8 reduced model memory by 45%, P95 latency improved from 120 ms to 76 ms, accuracy dropped 0.4 points, and the worst failures were still on low-light images.” That is a deployment decision, not just a compression result.
Pass check
Section titled “Pass check”You pass this lesson when you can explain one optimization’s benefit, its possible cost, and the metric you would inspect before using it in a real deployment.
Check reasoning and explanation
A strong answer names a specific optimization and its trade-off. For example, quantization may reduce memory and latency, but it can hurt accuracy on edge cases, so you should inspect validation accuracy, failure examples, and latency before/after.
Avoid saying only “smaller is better.” The correct deployment habit is to change one thing, measure the benefit, measure the cost, and decide whether the trade-off is acceptable.
Optimization Review
Section titled “Optimization Review”Review every optimization as a controlled experiment. The control group is the original model and runtime. The treatment is one change, such as quantization, pruning, batching, or a serving engine switch. If you change several things at once, the final result may look better but you will not know which decision caused the gain.
Keep the review small and measurable: one table with before latency, after latency, memory, model size, and the accuracy or quality check. If quality drops, keep the failed examples. Those failures decide whether the optimization is acceptable for the product.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Deployment Target
- local inference, edge device, model server, or optimization experiment
- Artifact
- C++ snippet, benchmark, model artifact, serving config, or deployment note
- Metric
- latency, memory, throughput, model size, accuracy drop, or reliability
- Failure Check
- ABI/build issue, hardware mismatch, quantization loss, or serving bottleneck
- Expected Output
- reproducible deployment or optimization evidence, not only theory notes