7.3.1 Transformer Deep Dive Roadmap: Blocks, Masks, Cost
This chapter looks inside the Transformer enough to debug LLM behavior and understand why context length, attention, KV cache, and model variants matter.
Look at the Internal Flow First
Section titled “Look at the Internal Flow First”
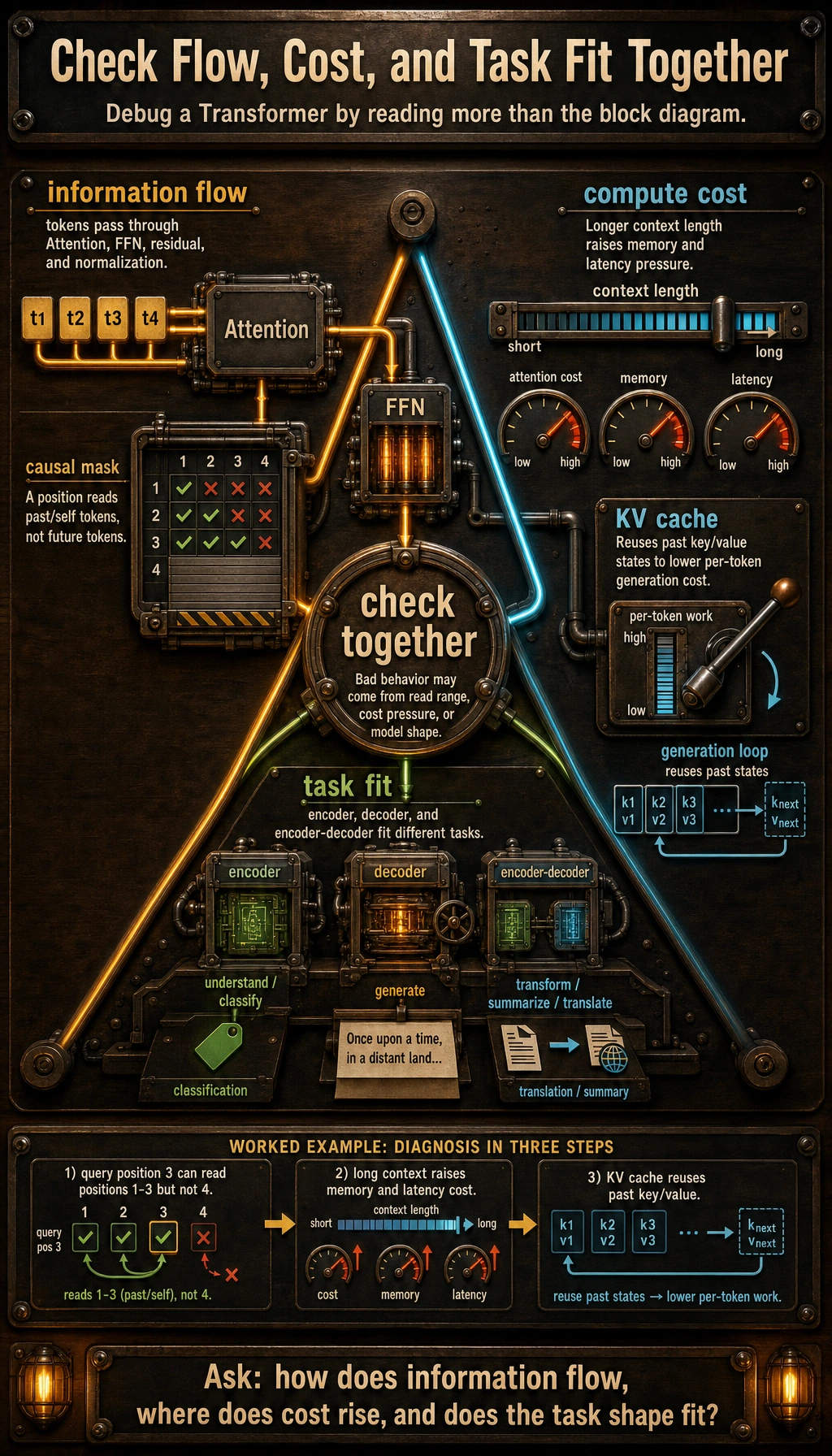
Read the second map as a debugging route: attention flow, compute cost, and task fit should be checked together.
Build a Causal Mask
Section titled “Build a Causal Mask”seq_len = 4mask = []for query_pos in range(seq_len): row = [] for key_pos in range(seq_len): row.append("allow" if key_pos <= query_pos else "block") mask.append(row)
for row in mask: print(row)Expected output:
['allow', 'block', 'block', 'block']['allow', 'allow', 'block', 'block']['allow', 'allow', 'allow', 'block']['allow', 'allow', 'allow', 'allow']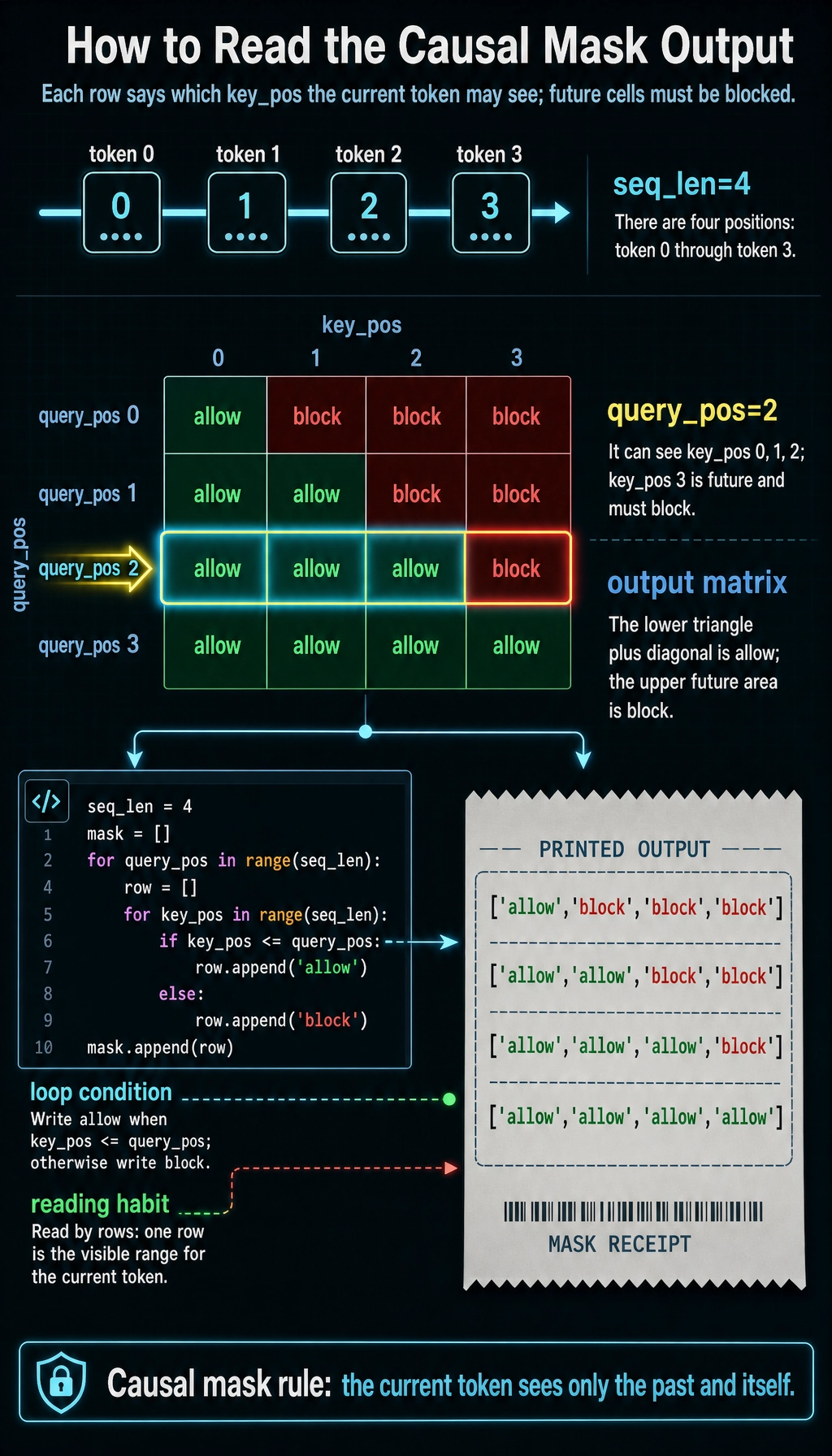
Generation uses this “no future peeking” rule: a token can attend to earlier tokens, but not future tokens.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to focus on |
|---|---|---|
| 1 | 7.3.2 Architecture Review | attention, residual, normalization |
| 2 | 7.3.3 Modern Decoder Block | decoder-only LLM block |
| 3 | 7.3.4 Model Variants | encoder, decoder, encoder-decoder |
| 4 | 7.3.5 Efficient Attention | KV cache, MQA/GQA, long context |
| 5 | 7.3.6 Scale and Computation | cost, latency, memory |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Block Contract
- [batch, seq, d_model] in and out
- Mask Check
- causal mask blocks future positions
- Kv Cache Reason
- inference reuses past keys and values
- Compute Note
- attention cost grows with sequence length
- Bridge
- these details explain latency and context limits in apps
Pass Check
Section titled “Pass Check”You pass this roadmap when you can explain why decoder-only models need a causal mask, why attention gets expensive as context grows, and why KV cache helps generation.
Check reasoning and explanation
- A passing answer explains how tokens, context, attention, prompts, and generation behavior connect in one request-response path.
- The evidence should include at least one reproducible prompt or structured-output test, plus notes on why the output passed or failed.
- A good self-check separates prompt design, RAG, fine-tuning, and alignment: use the lightest method that fixes the observed problem.