7.2.2 Development History of Large Models
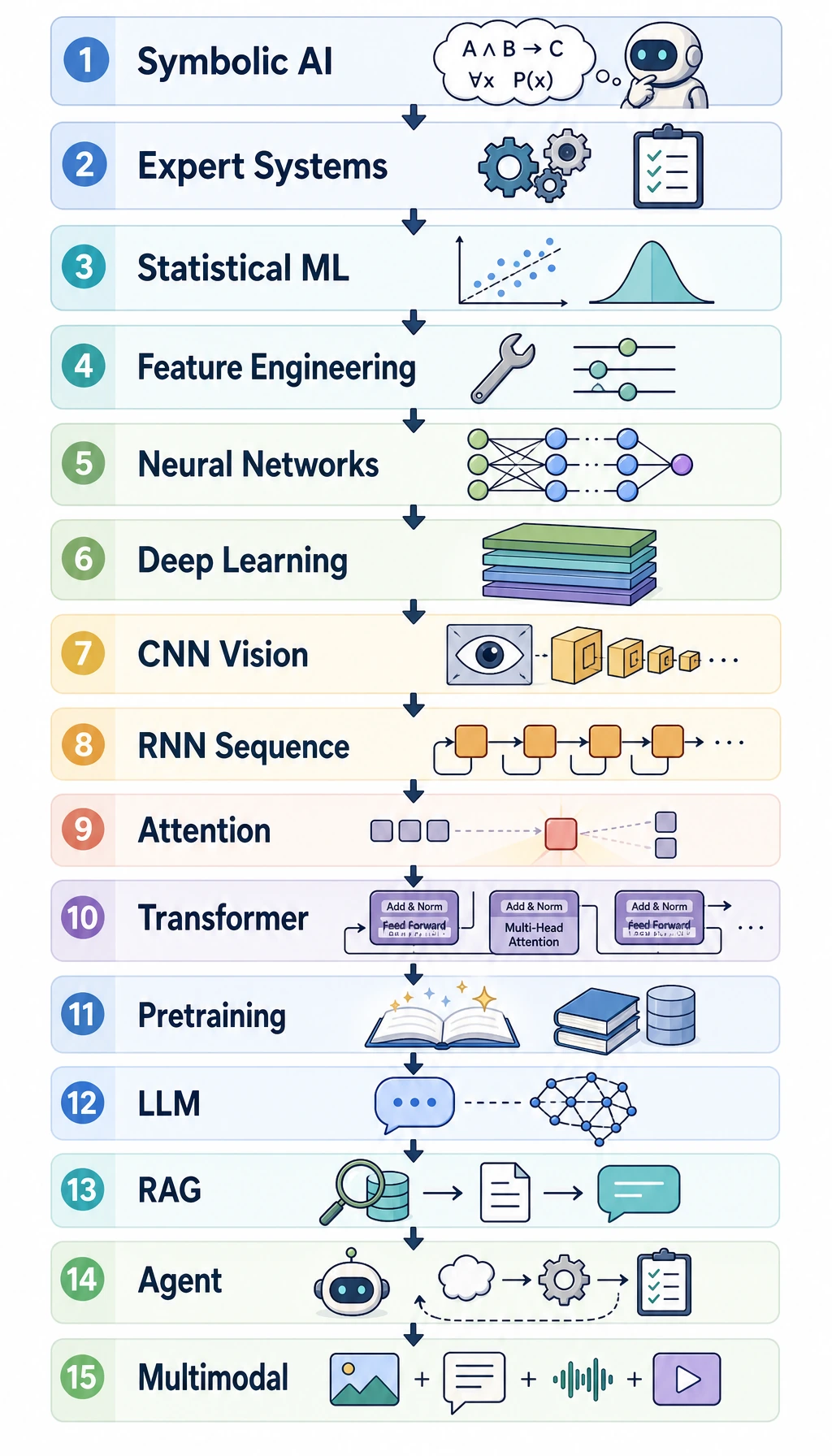
The 15-Stage Big Picture
Section titled “The 15-Stage Big Picture”| Stage | What changed | Why it matters to LLMs |
|---|---|---|
| 1. Turing question | machine intelligence became a concrete question | language became a key test of intelligence |
| 2. Dartmouth AI | AI became a research field | symbolic reasoning dominated early thinking |
| 3. Perceptron | neural learning appeared | first wave of trainable models |
| 4. Expert systems | rules scaled inside narrow domains | showed both value and maintenance pain |
| 5. Backpropagation | multilayer neural nets became trainable | foundation for deep learning |
| 6. LeNet | neural nets worked on real perception tasks | showed representation learning in practice |
| 7. Statistical ML | data-driven methods beat many hand rules | NLP moved toward corpus evidence |
| 8. ImageNet / AlexNet | deep learning won at scale | data + compute + architecture mattered |
| 9. ResNet | very deep networks became trainable | scale became more reliable |
| 10. RNN / LSTM | sequences became neural | language modeling moved beyond n-grams |
| 11. Attention | models could focus on relevant positions | solved part of long-context bottleneck |
| 12. Transformer | attention became the main architecture | parallel training and scaling took off |
| 13. BERT / GPT | pretraining became the shared foundation | one model could transfer to many tasks |
| 14. RLHF / ChatGPT | behavior was aligned with instructions | model capability became product behavior |
| 15. RAG / Agent | models used knowledge and tools | LLMs became application systems |
Now zoom in on the language-model line.
Five Language-Model Eras
Section titled “Five Language-Model Eras”| Era | Core idea | Main limitation |
|---|---|---|
| Rule-based systems | humans write language rules | brittle and expensive to maintain |
| Statistical language models | next word follows observed frequency | sparse data and short context |
| Neural sequence models | learn vectors and recurrent state | hard to train long dependencies |
| Transformers | every token can attend to relevant tokens | compute and data cost are high |
| LLM + alignment | scale pretraining, then tune behavior | hallucination, safety, cost, evaluation |
The through line is context. Each era tried to use more context with fewer brittle assumptions.
Lab: Build a Bigram Language Model
Section titled “Lab: Build a Bigram Language Model”This small n-gram model predicts the next word from the current word. It is not powerful, but it shows the statistical idea that came before neural LMs.
from collections import Counter, defaultdict
corpus = [ "I like learning AI", "I like learning Python", "You like learning NLP", "I like doing projects",]
next_word_counter = defaultdict(Counter)
for sentence in corpus: tokens = sentence.split() for current_word, next_word in zip(tokens[:-1], tokens[1:]): next_word_counter[current_word][next_word] += 1
def suggest_next(word): candidates = next_word_counter[word] return candidates.most_common() if candidates else []
print("Common words after I :", suggest_next("I"))print("Common words after like :", suggest_next("like"))print("Common words after learning:", suggest_next("learning"))Expected output:
Common words after I : [('like', 3)]Common words after like : [('learning', 3), ('doing', 1)]Common words after learning: [('AI', 1), ('Python', 1), ('NLP', 1)]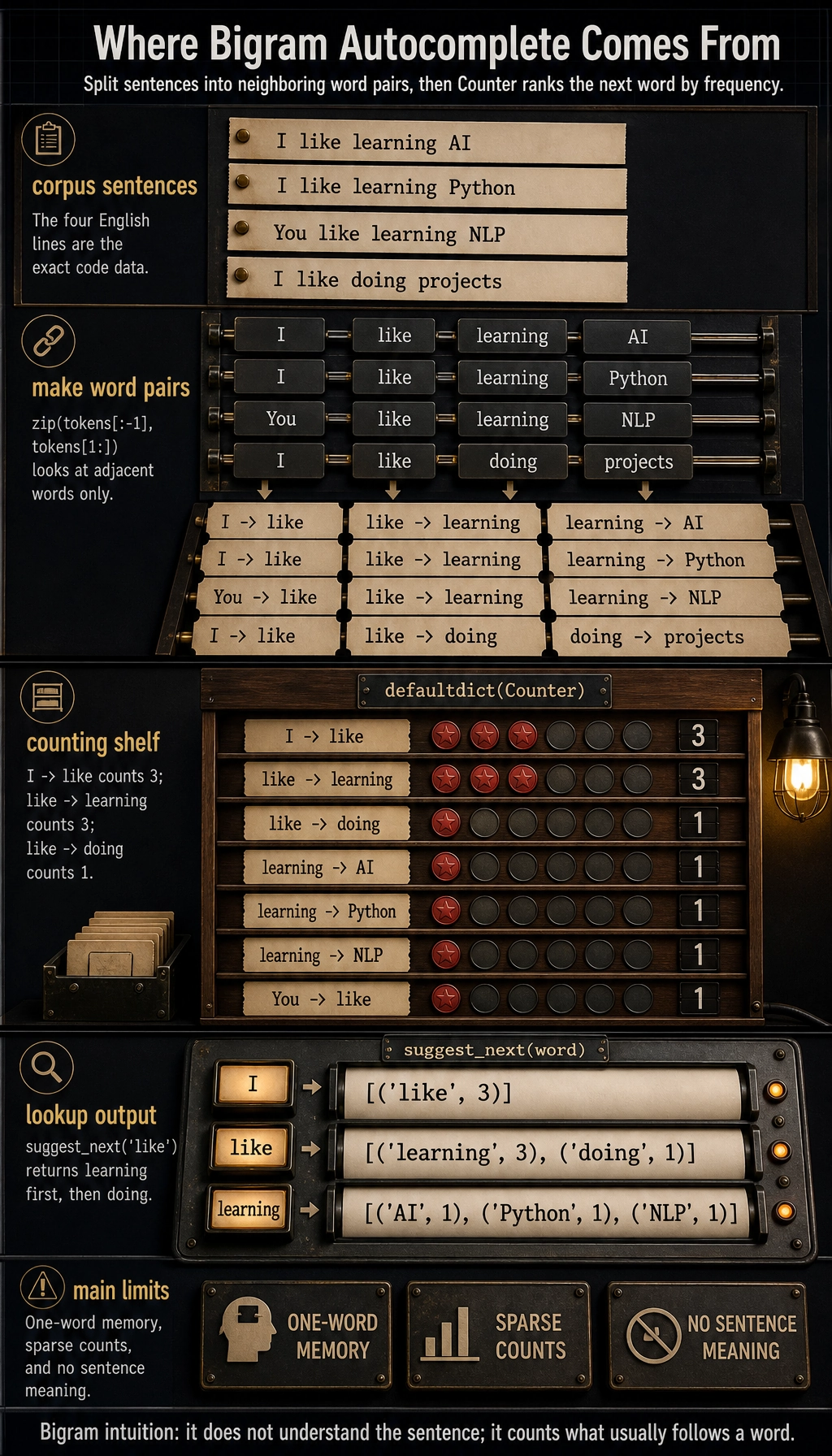
This already feels like autocomplete. But it has three obvious limits:
- it only looks one word back;
- rare combinations have weak statistics;
- it has no semantic representation of the sentence.
Why Neural Models Mattered
Section titled “Why Neural Models Mattered”Neural language models replaced raw counting with learned representations:
Word2Vec, GloVe, RNN, LSTM, and GRU made language modeling more flexible. They helped models learn similarity and longer context, but sequential reading still made training slow and long-range memory fragile.
Why Transformer Was the Turning Point
Section titled “Why Transformer Was the Turning Point”RNNs read mainly step by step. Transformers let tokens directly compare with other tokens through attention:
That changed three things:
- training could be more parallel;
- long-range relationships became easier to model;
- scaling parameters, data, and compute became more effective.
This is why BERT, GPT, T5, and later LLMs share the Transformer family tree.
Why Scale Was Not Enough
Section titled “Why Scale Was Not Enough”Large-scale pretraining made models broadly capable, but product behavior still needed another layer:
| Need | Technique |
|---|---|
| follow instructions | instruction tuning |
| prefer helpful responses | preference learning / RLHF |
| use current private knowledge | RAG |
| perform actions | tool calling / Agent loop |
| reduce unsafe behavior | safety evaluation and guardrails |
This is the key modern distinction:
model capability != model behaviorA model can be powerful and still fail to follow policy, cite evidence, or act safely.
What to Remember
Section titled “What to Remember”Large models belong to NLP history, but they now exceed a narrow NLP boundary. The same architecture and training ideas are used for text, image, speech, code, video, multimodal QA, RAG, and agents.
The practical lesson is:
- rules gave control but poor coverage;
- statistics gave data evidence but short context;
- neural representations gave semantic space;
- Transformer made scale practical;
- alignment, RAG, and tools turned models into systems.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Timeline
- n-gram → neural LM → Transformer → scaling → instruction/alignment
- Turning Point
- what Transformer changed about context mixing
- Scale Note
- data and compute changed capability but not reliability alone
- Bigram Lab
- one output sample and its limitation
- Memory Hook
- history is a sequence of solved bottlenecks
Exercises
Section titled “Exercises”- Add two sentences to the bigram corpus and observe how suggestions change.
- Why does a bigram model fail on long instructions?
- Explain why Transformer training is easier to parallelize than RNN training.
- Give one example where a model has capability but still needs alignment or RAG.
- Pick one of the 15 stages and explain how it still affects today’s LLM applications.
Solution approach and explanation
- Adding sentences changes only the local transition counts in a bigram model. Suggestions may improve for the added phrases but will still fail outside those local patterns.
- A bigram model sees only a tiny local context. Long instructions require tracking goals, constraints, and relationships across many tokens.
- Transformer self-attention can process positions in parallel during training, while RNN states depend on previous time steps and are naturally sequential.
- A model may be able to write fluent answers but still need RAG for private documents, or alignment for safety, refusal behavior, and instruction following.
- For example, the Transformer stage still shapes modern systems because attention-based context mixing is the basis of most LLM architectures.