13.5 Open-Weight Model Landscape: gpt-oss, Qwen, DeepSeek, Llama
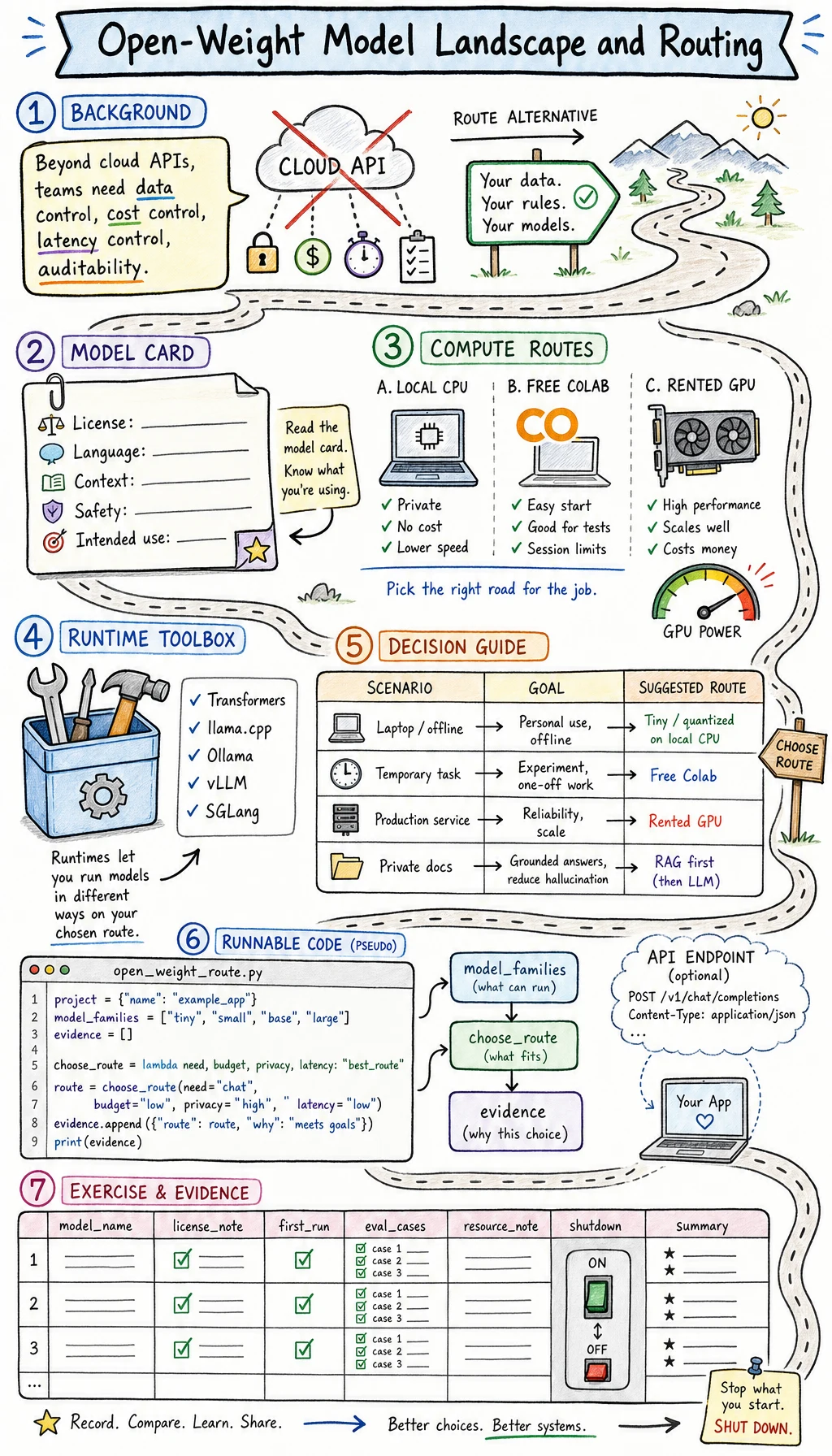
Open-weight models are now a practical part of the AI engineering stack. Families such as OpenAI gpt-oss, Qwen, DeepSeek-style reasoning models, Llama-family models, and Mistral-family models give teams more control over privacy, cost, latency, and deployment.
This lesson does not ask you to chase every model name. It teaches the repeatable workflow: read the model card, choose a runtime, run a tiny proof, evaluate the result, and only then decide whether to fine-tune.
Why This Appeared
Section titled “Why This Appeared”Cloud APIs made LLM applications easy to start. Open-weight models became important because teams also need:
-
Data control Some inputs cannot leave a private machine or VPC.
-
Cost control Repeated high-volume inference can be cheaper on owned or rented hardware.
-
Latency control Local or regional deployment can reduce round trips.
-
Customization RAG, decoding settings, adapters, quantization, and LoRA can be tuned around a specific product.
-
Auditability Engineers can record model files, revisions, runtime settings, and evaluation cases.
The trade-off is that you now own more systems work: downloads, licenses, memory, drivers, serving, evaluation, and shutdown.
Concept Map
Section titled “Concept Map”| Layer | Question | Evidence |
|---|---|---|
| Model card | What is this model allowed and designed to do? | License, language, context, safety notes, intended use |
| Runtime | How will it run? | Transformers, llama.cpp, Ollama, vLLM, SGLang, or hosted notebook |
| Compute route | Where will it run? | Local CPU/GPU, free Colab, rented GPU |
| Evaluation | Is it good enough for this task? | Fixed prompts, pass/fail notes, latency, memory |
| Adaptation | Should we tune? | Prompt/RAG first, then LoRA only with failing eval evidence |
Decision Table
Section titled “Decision Table”| Situation | First route | First target | Stop when you have |
|---|---|---|---|
| Laptop only, no GPU | Local CPU quantized model | Tiny instruct model or small quantized model | Prompt, output, time note, memory note |
| Temporary experiment | Free Colab if available | Small model and short eval | Notebook link, runtime type, reset note |
| Need stable service | Rented GPU | vLLM/SGLang/OpenAI-compatible API | Endpoint, request/response, cost/hour, stop command |
| Need private documents | Local or private GPU | RAG before tuning | Access rule, source trace, no data-leak note |
| Need domain behavior change | GPU route | LoRA only after eval failures | Before/after eval and adapter artifact |
Runnable Lab: Choose an Open-Weight Route
Section titled “Runnable Lab: Choose an Open-Weight Route”Create open_weight_route.py and run it with Python 3.10 or later. The script does not download a model; it builds the decision card you should write before spending GPU money.
import jsonfrom pathlib import Path
project = { "task": "course Q&A assistant", "privacy": "private_docs", "available_route": "rented_gpu", "needs_service_api": True, "needs_fine_tuning": False, "budget_level": "small",}
model_families = [ {"family": "small instruct model", "fit": ["cpu_lab", "colab"], "runtime": "llama.cpp or Transformers"}, {"family": "Qwen or Llama family", "fit": ["colab", "rented_gpu"], "runtime": "Transformers, vLLM, or SGLang"}, {"family": "gpt-oss family", "fit": ["rented_gpu"], "runtime": "check current model card and runtime support"}, {"family": "reasoning model family", "fit": ["rented_gpu"], "runtime": "serve only after latency and cost checks"},]
def choose_route(info): if info["available_route"] == "local_cpu": return {"route": "local_cpu", "goal": "prove the pipeline with a small quantized model"} if info["available_route"] == "free_colab": return {"route": "free_colab", "goal": "run one notebook experiment and save reset notes"} return {"route": "rented_gpu", "goal": "run a stable API with explicit cost and shutdown"}
def choose_family(info, families): route = choose_route(info)["route"] for item in families: if route in item["fit"]: if info["needs_service_api"] and "vLLM" not in item["runtime"] and route == "rented_gpu": continue return item return families[0]
decision = { "project": project["task"], "route": choose_route(project), "model_family": choose_family(project, model_families), "adaptation": "RAG first; LoRA only after fixed eval failures" if not project["needs_fine_tuning"] else "prepare LoRA after baseline eval", "evidence": [ "model card and license note", "runtime command", "first prompt and output", "five-case eval table", "latency and memory note", "shutdown command", ],}
Path("open_weight_route.json").write_text(json.dumps(decision, indent=2), encoding="utf-8")print(json.dumps(decision, indent=2))Expected output:
{ "project": "course Q&A assistant", "route": { "route": "rented_gpu", "goal": "run a stable API with explicit cost and shutdown" }, "model_family": { "family": "Qwen or Llama family", "fit": [ "colab", "rented_gpu" ], "runtime": "Transformers, vLLM, or SGLang" }, "adaptation": "RAG first; LoRA only after fixed eval failures", "evidence": [ "model card and license note", "runtime command", "first prompt and output", "five-case eval table", "latency and memory note", "shutdown command" ]}Read the Code Line by Line
Section titled “Read the Code Line by Line”project is the constraint card. Change route, privacy, API need, and tuning need before picking a model.
model_families is intentionally not a benchmark table. It is a planning table. Always check the current official model card before downloading or serving.
choose_route() separates local CPU, free Colab, and rented GPU. Each route has a different proof target.
choose_family() avoids selecting a family only because it is popular. It asks whether the family fits the route and runtime.
decision["evidence"] is the minimum run packet. Do not fine-tune before this exists.
Mini Exercise
Section titled “Mini Exercise”Run the script three times:
| Run | Change | What should happen |
|---|---|---|
| Local CPU | available_route="local_cpu", needs_service_api=False | The goal becomes pipeline proof, not serving |
| Free Colab | available_route="free_colab" | The evidence must include reset/runtime notes |
| Rented GPU | available_route="rented_gpu", needs_service_api=True | The plan must include API, cost, and shutdown |
Then write one rejected model family and why you rejected it.
Evidence to Keep
Section titled “Evidence to Keep”Every open-weight experiment should save:
- Model Name
- exact repository and revision if possible
- License Note
- what use is allowed
- Route
- local CPU, free Colab, or rented GPU
- Runtime
- command and version
- First Run
- prompt, output, timestamp
- Eval
- at least five fixed cases
- Resource Note
- memory, latency, disk, cost
- Shutdown
- how to stop server or rented instance
- Decision
- keep, switch, RAG, LoRA, or stop
Small Summary
Section titled “Small Summary”Open-weight models give more control, but they also make you responsible for more engineering. Start with a small proof, save evidence, evaluate before tuning, and treat GPU rental as a reproducible experiment rather than a shortcut.
Check reasoning and explanation
You pass this lesson when you can choose among local CPU, free Colab, and rented GPU; name the model-card evidence you need; run or plan a small proof; and explain why fine-tuning should wait until baseline evaluation fails.