E.C.2 K-Nearest Neighbors
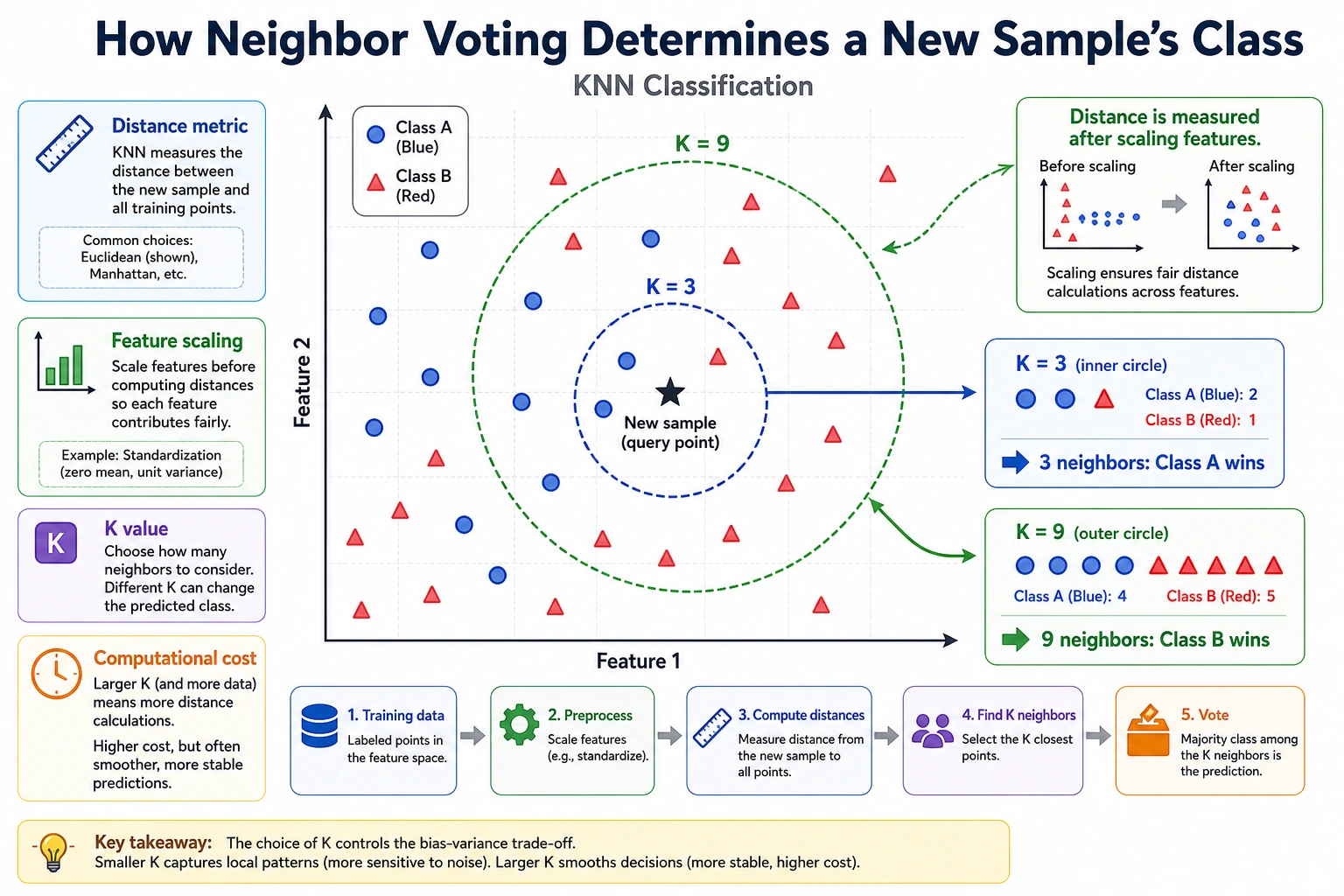
KNN makes a prediction by looking at the nearest labeled samples and letting them vote. It has almost no training cost, but prediction can become expensive because it must compare distances.
What You Need
Section titled “What You Need”- Python 3.10+
- Current stable
scikit-learnandnumpy
python -m pip install -U scikit-learn numpyKey Terms
Section titled “Key Terms”- K: how many neighbors vote.
- Distance metric: how “near” is calculated.
- Lazy learning: little work during training, more work during prediction.
- Scaling: required when feature ranges differ.
Run A Neighbor Vote
Section titled “Run A Neighbor Vote”Create knn_vote.py:
import numpy as npfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScaler
X = np.array([ [1, 1], [2, 2], [2, 1], [8, 8], [9, 9], [8, 9],])y = np.array([0, 0, 0, 1, 1, 1])
model = make_pipeline( StandardScaler(), KNeighborsClassifier(n_neighbors=3),)
model.fit(X, y)pred = model.predict([[3, 3], [8.5, 8.2]])print("predictions:", pred.tolist())Run it:
python knn_vote.pyExpected output:
predictions: [0, 1]The model did not learn a complex formula. It stored examples, scaled features, measured distance, and voted.
Baseline Review
Section titled “Baseline Review”Review KNN by inspecting which neighbors voted, not just the final label. If the nearest examples do not make intuitive sense, the feature space is probably wrong or unscaled.
KNN is useful in a portfolio when you want a transparent distance baseline. It is weaker as a production default when the dataset grows large, because prediction must compare against stored examples unless you add an index or approximate search.
Change K
Section titled “Change K”Change n_neighbors=3 to 1 and 5. Small K reacts strongly to local points; large K smooths the decision.
Practical Rule
Section titled “Practical Rule”Try KNN when:
- The dataset is small.
- Feature distances are meaningful.
- You want an interpretable baseline quickly.
- Prediction latency is not strict.
Avoid it as a default for huge datasets or real-time high-QPS services.
Baseline Review
Section titled “Baseline Review”Review KNN by looking beyond the final label. Keep the nearest neighbors, their labels, and the distance values for at least one prediction. This shows whether the result came from meaningful similarity or from a feature scale that accidentally dominated distance.
KNN is a useful baseline because it is easy to explain. It is also easy to misuse. If scaling changes the prediction completely, or if prediction latency grows too much with the dataset, record that limit before moving to a heavier model.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Model Family
- SVM, KNN, Naive Bayes, LDA, or another classical baseline
- Dataset View
- feature scale, class balance, decision boundary, and train/test split
- Metric
- accuracy/F1, confusion matrix, margin, neighbor behavior, or projection quality
- Failure Check
- scaling, high dimensionality, weak assumptions, leakage, or poor baseline fit
- Expected Output
- classical-ML baseline result with one limitation note
Common Mistakes
Section titled “Common Mistakes”- Forgetting to scale features.
- Treating KNN as “trained” when most cost happens at prediction time.
- Tuning K before checking whether the features actually express similarity.
Practice
Section titled “Practice”Add a third feature with values around 10000, remove StandardScaler(), and observe how distance voting becomes distorted.
Reference implementation and walkthrough
Without scaling, the feature near 10000 dominates Euclidean distance. That means KNN may vote based mostly on the large-scale feature, even if the original two features describe the class pattern better.
A good answer compares predictions with and without StandardScaler() and explains which feature controlled the distance. The lesson is that KNN depends heavily on feature scale because it has no learned weights to correct bad distance geometry.