10.3.1 Object Detection Roadmap: Class plus Box
Object detection adds location to classification: what object is present, and where is it in the image?
See the Box Workflow First
Section titled “See the Box Workflow First”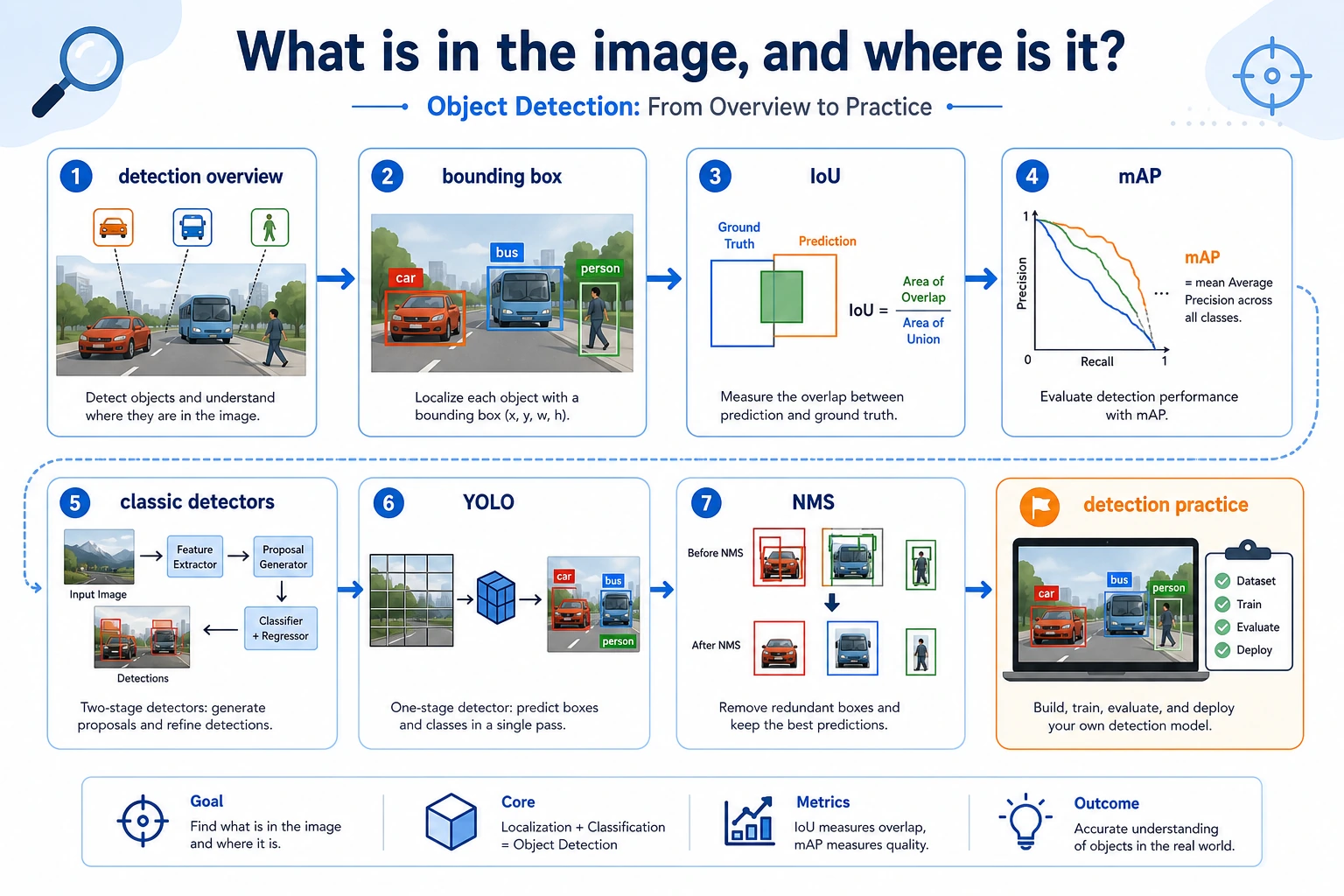
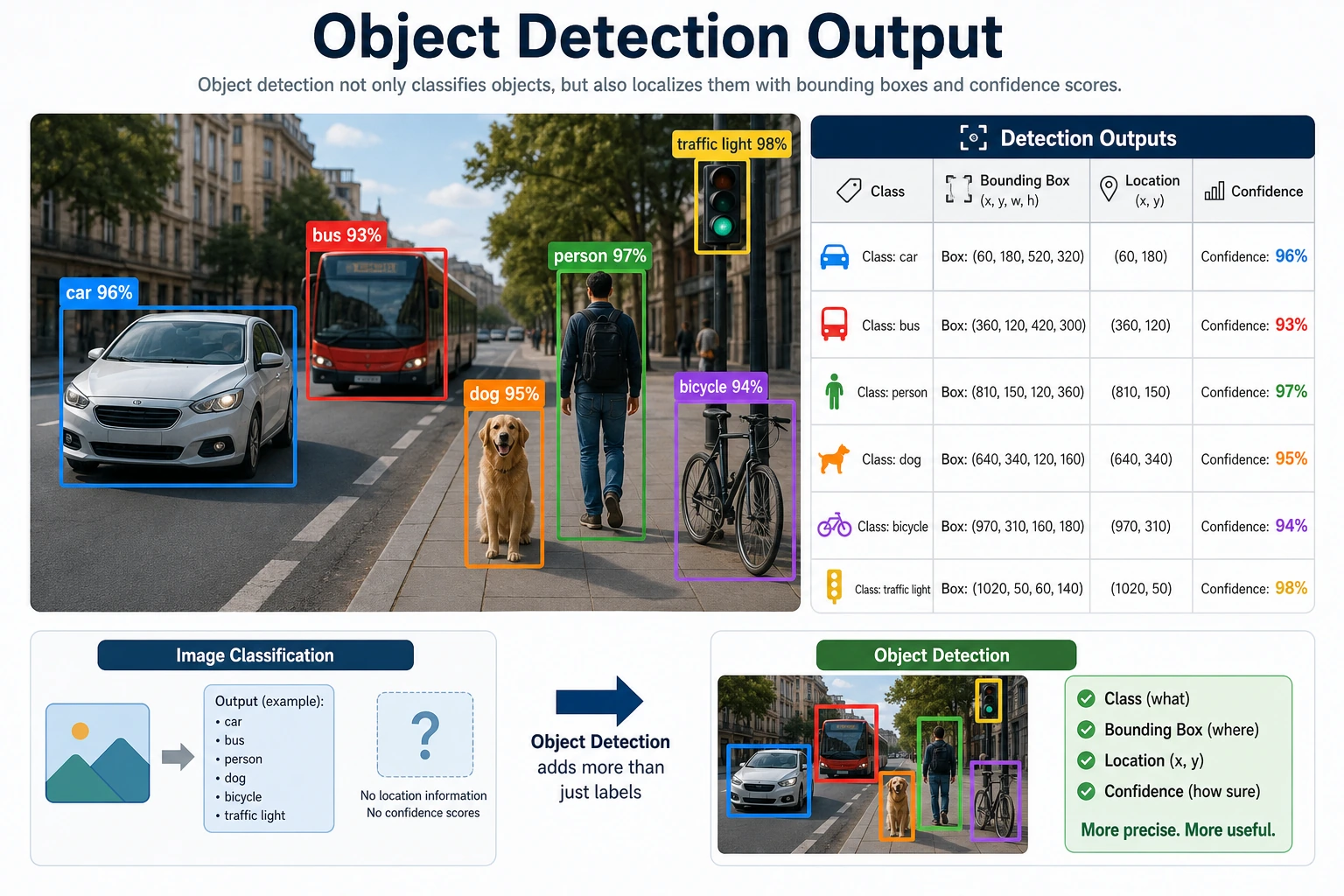
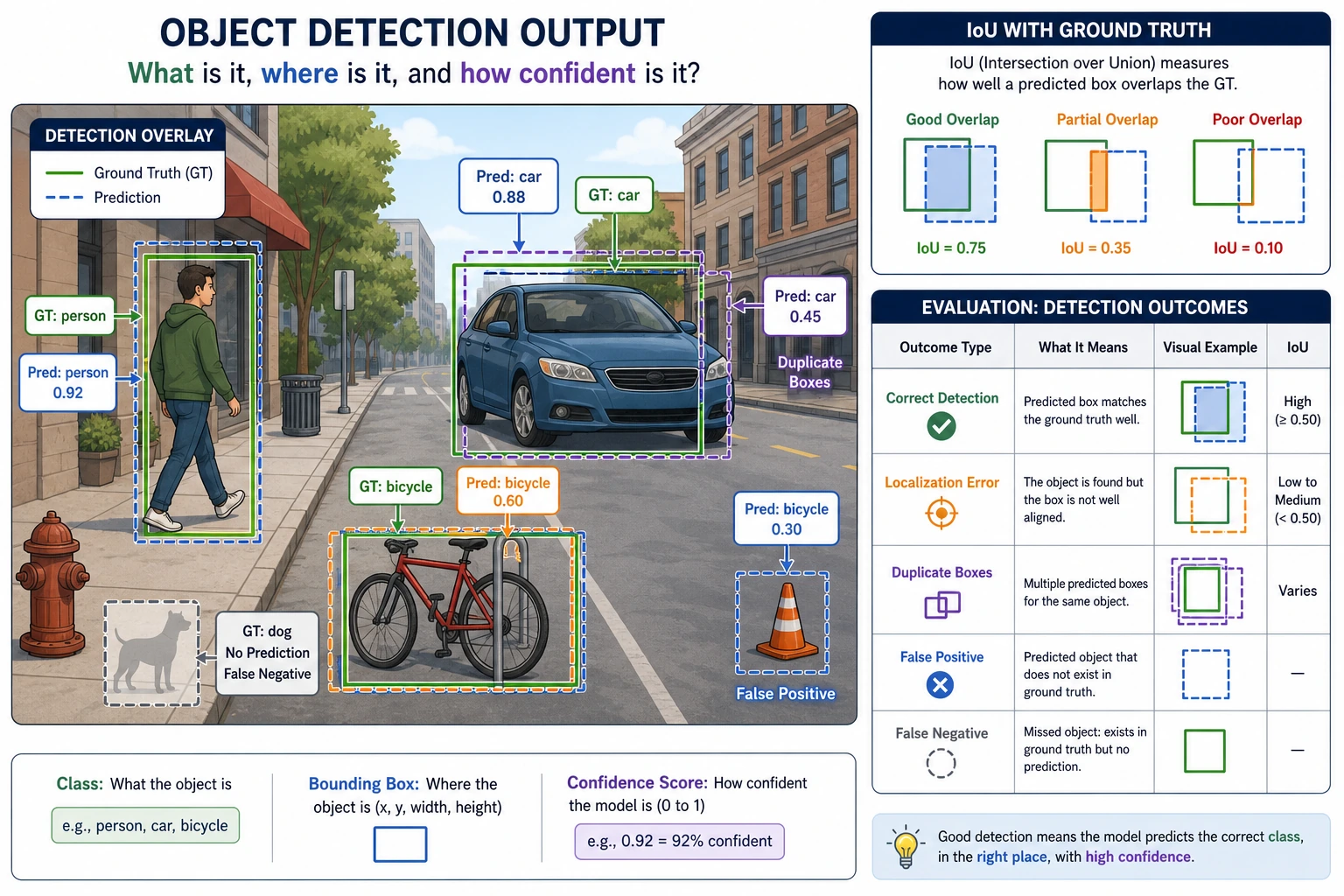
The important concepts are bounding box, class, confidence, IoU, threshold, false positive, false negative, and mAP.
Run an IoU Check
Section titled “Run an IoU Check”IoU measures how much the predicted box overlaps the ground-truth box.
truth = (10, 10, 50, 50)pred = (20, 20, 60, 60)
def area(box): x1, y1, x2, y2 = box return max(0, x2 - x1) * max(0, y2 - y1)
ix1 = max(truth[0], pred[0])iy1 = max(truth[1], pred[1])ix2 = min(truth[2], pred[2])iy2 = min(truth[3], pred[3])intersection = area((ix1, iy1, ix2, iy2))union = area(truth) + area(pred) - intersection
print("iou:", round(intersection / union, 3))Expected output:
iou: 0.391Detection debugging starts by printing boxes and metrics. Do not judge detection quality from one nice screenshot.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | Detection overview | Explain box, class, confidence, IoU, mAP |
| 2 | Classic detectors | Compare two-stage and one-stage ideas |
| 3 | YOLO | Understand grid prediction, threshold, NMS, and speed trade-offs |
| 4 | Detection practice | Record false positives, missed detections, and threshold changes |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Input Image
- detection sample with ground-truth or expected objects
- Prediction
- boxes, labels, confidence scores, IoU, and threshold settings
- Metric
- precision/recall, mAP, false positives, and false negatives
- Failure Check
- small object, overlap, NMS, poor labels, or confidence threshold
- Expected Output
- annotated image plus detection metrics or error buckets
Pass Check
Section titled “Pass Check”You pass this chapter when you can explain a detection result with boxes, confidence, IoU, and at least one false-positive or false-negative case.
Check reasoning and explanation
- A passing answer maps the task to the right visual output: class label, bounding box, mask, OCR text, embedding, or video event.
- The evidence should include a rendered visual artifact and one metric or qualitative error note.
- A good self-check names one visual failure mode such as class confusion, missed objects, bad masks, lighting shift, domain shift, or weak annotation quality.