11.1.1 Text Basics Roadmap: Tokens, Cleaning, Representation
Text is not naturally computable. Before classification, extraction, summarization, or QA, you need to turn raw text into stable units and features.
See the Text Pipeline First
Section titled “See the Text Pipeline First”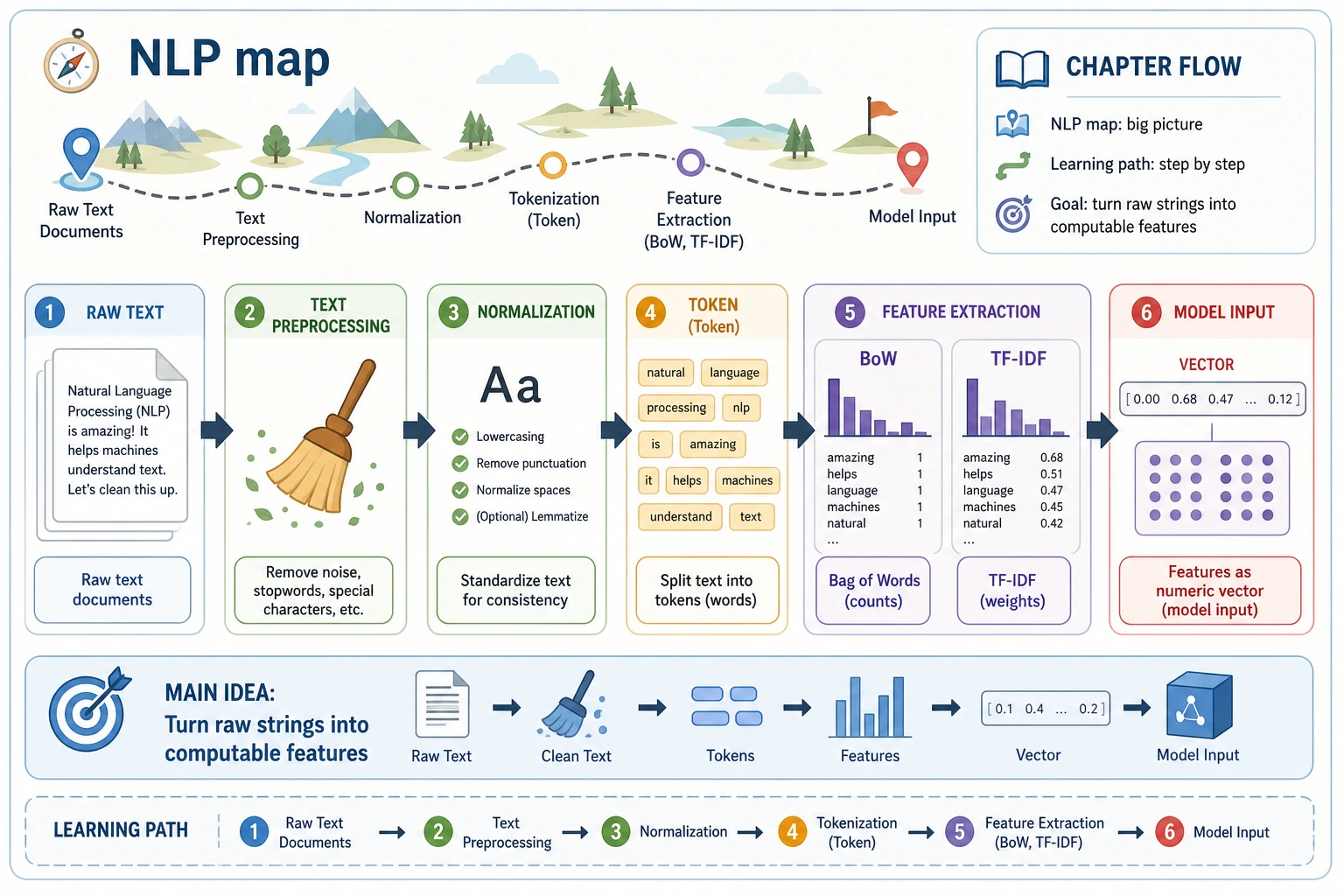


The first habit is to ask: what is the input text, what is the task, and what output shape should the system produce?
Run a Token and Vocabulary Check
Section titled “Run a Token and Vocabulary Check”text = "RAG answers need citations"tokens = text.lower().split()vocab = {token: index for index, token in enumerate(sorted(set(tokens)))}ids = [vocab[token] for token in tokens]
print("tokens:", tokens)print("ids:", ids)print("vocab_size:", len(vocab))Expected output:
tokens: ['rag', 'answers', 'need', 'citations']ids: [3, 0, 2, 1]vocab_size: 4If tokenization is unstable, every downstream task becomes unstable too.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | NLP task map | Match classification, labeling, extraction, QA, summarization |
| 2 | Preprocessing | Normalize text, split tokens, handle noise and boundaries |
| 3 | Text representation | Build tokens, ids, vocabulary, sparse features, or vectors |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Raw Text
- original examples before cleaning or tokenization
- Processed Text
- cleaned text, tokens, normalization notes, and removed items
- Task Boundary
- classification, extraction, retrieval, generation, or QA output
- Failure Check
- lost meaning, bad token split, language issue, or ambiguous label
- Expected Output
- before/after text samples plus token or representation output
Pass Check
Section titled “Pass Check”You pass this chapter when you can take raw text, tokenize it, explain the task output shape, and save one preprocessing example in your project notes.
Check reasoning and explanation
- A passing answer starts from the text unit and output type: token, span, sentence label, sequence, embedding, or generated text.
- The evidence should include a small dataset example, model or pipeline choice, metric, and at least one inspected error case.
- A good self-check distinguishes preprocessing issues from model issues, such as tokenization mistakes, label ambiguity, data imbalance, or hallucinated generation.