8.1.1 RAG Roadmap: Documents, Retrieval, Answers
RAG solves a practical problem: the model does not know every fresh, private, or source-specific fact, so the application must retrieve evidence before asking the model to answer.
See the RAG Pipeline First
Section titled “See the RAG Pipeline First”
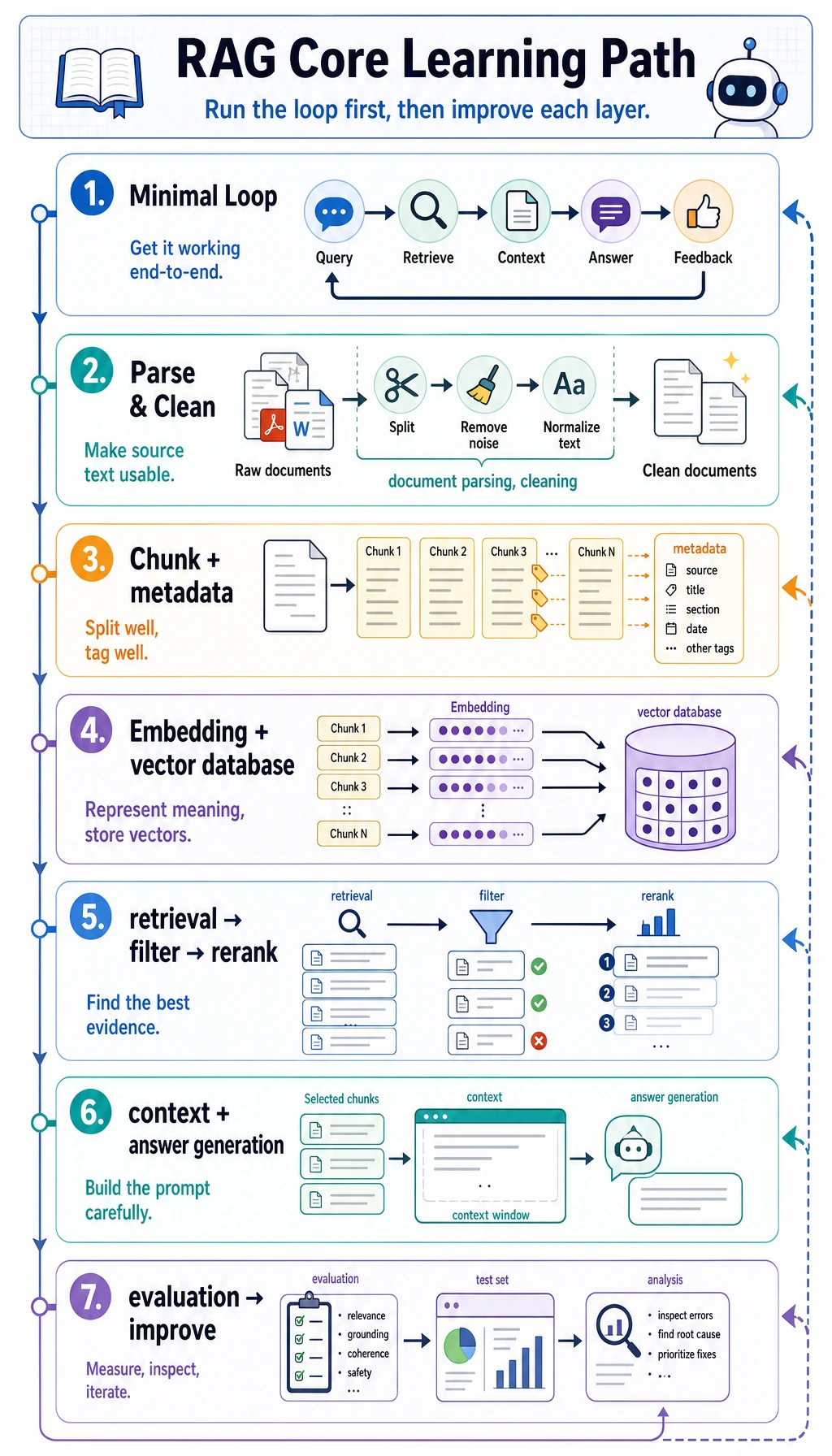

The core loop is: load documents, split chunks, add metadata, embed, retrieve, rerank, assemble context, answer, cite sources, and evaluate.
Run a Tiny Retrieval Check
Section titled “Run a Tiny Retrieval Check”This is not a vector database yet. It is a tiny offline version of the retrieval habit: score chunks, print sources, and verify whether the evidence matches the question.
chunks = [ {"source": "rag.md", "text": "RAG retrieves source chunks before the model answers."}, {"source": "eval.md", "text": "Citations let users verify whether an answer is grounded."}, {"source": "deploy.md", "text": "Deployment exposes the model through a stable API."},]
query = "why do RAG answers need citations"query_terms = set(query.lower().split())
def score(chunk): words = set(chunk["text"].lower().replace(".", "").split()) return len(query_terms & words)
for chunk in sorted(chunks, key=score, reverse=True)[:2]: print(chunk["source"], score(chunk))Expected output:
rag.md 2eval.md 1If the top source is unrelated, do not tune the final prompt first. Check document parsing, chunking, metadata, and retrieval coverage.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | RAG basics | Draw the question → evidence → answer loop |
| 2 | Document processing | Produce chunks with source and metadata |
| 3 | Vector databases | Explain embedding, vector record, and similarity search |
| 4 | Retrieval strategies | Compare keyword, vector, hybrid, filter, and rerank |
| 5 | Optimization and advanced RAG | Debug poor recall, poor ranking, and weak context |
| 6 | RAG evaluation | Test answer correctness, citation support, and no-answer behavior |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Query
- one user question or test case
- Retrieved Chunks
- chunk ids, scores, and source titles
- Answer
- final response with citation or source note
- Failure Check
- missing evidence, wrong chunk, stale doc, or unsupported claim
- Next Action
- chunking, embedding, reranking, prompt, or eval change
Pass Check
Section titled “Pass Check”You pass this chapter when you can build a minimal knowledge-base Q&A loop that prints retrieved chunks, answer text, and source citations for at least 10 fixed questions.
The exit mini project is a course knowledge-base assistant with 3 to 5 Markdown documents, top-k retrieval output, source display, and a simple evaluation table.
Check reasoning and explanation
- A passing answer traces the full path from query to chunks, retrieval scores, cited evidence, answer, and fallback behavior.
- The evidence should include retrieved passages, source metadata, a cited answer, and at least one empty-retrieval or wrong-retrieval case.
- A good self-check explains whether a failure came from chunking, retrieval, ranking, prompt assembly, missing sources, or unsupported generation.