E.A.7 Deployment Integrated Project
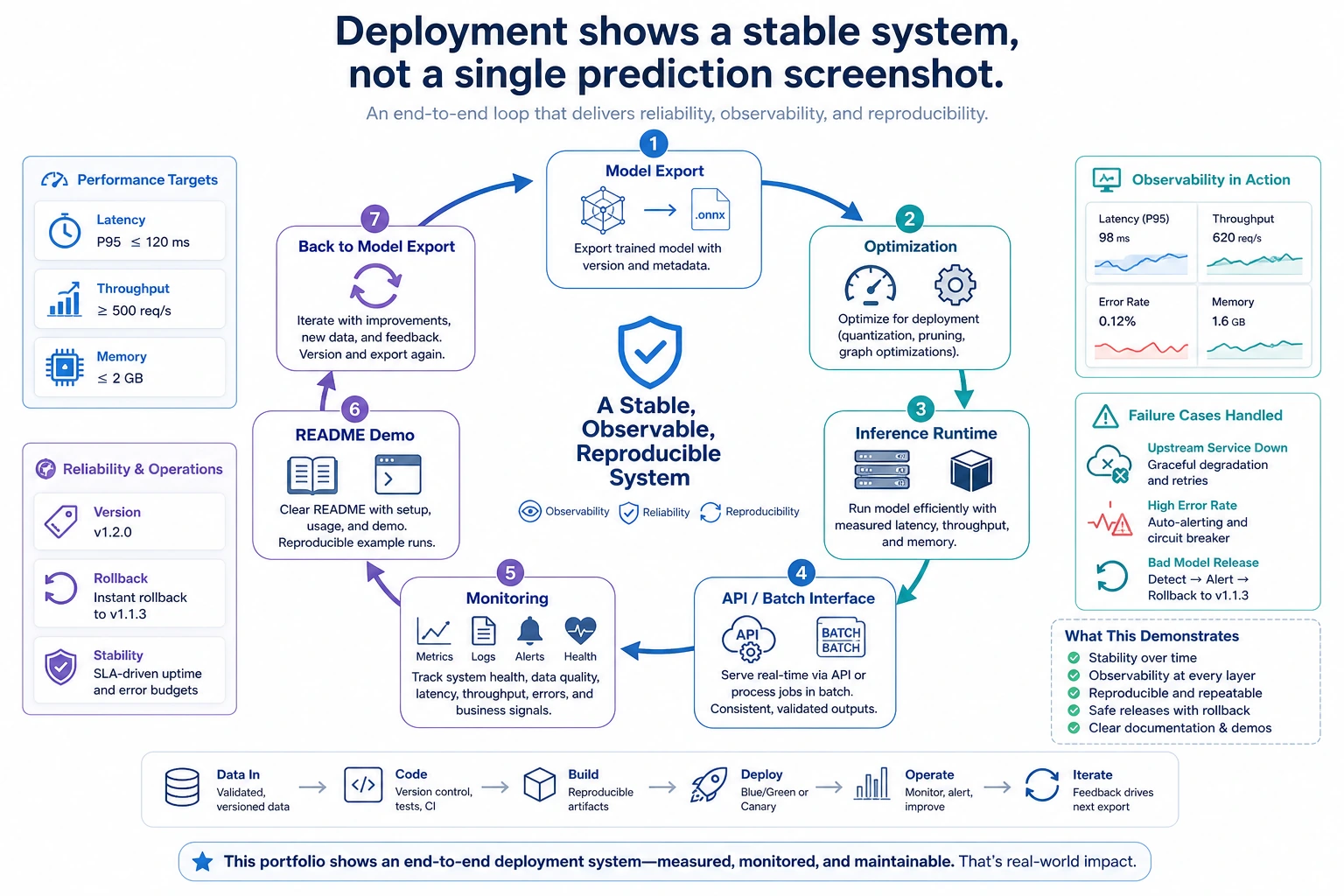
This project is not about training the biggest model. It is about proving that you can turn a model into a small, measurable, deployable system.
Build a simple project story:
Lightweight image classification service with local inference, batching, metrics, and an edge-device readiness check.
What You Need
Section titled “What You Need”- Python 3.10+
- No external packages
- One small model idea, real or simulated
- One target device, such as a laptop CPU, Raspberry Pi, Jetson, or cloud CPU instance
Delivery Checklist
Section titled “Delivery Checklist”Your final project should show:
- Target device and engine choice
- Input and output examples
- Baseline vs optimized metrics
- Serving or batch-processing flow
- Known failure cases
- Reproduction commands
Run A Project Readiness Score
Section titled “Run A Project Readiness Score”Create deployment_project_check.py:
project = { "name": "lightweight-image-classifier", "target_device": "edge-c", "engine": "ONNX Runtime", "baseline": {"latency_ms": 120, "memory_mb": 820, "accuracy": 0.904}, "optimized": {"latency_ms": 68, "memory_mb": 430, "accuracy": 0.899}, "evidence": ["README.md", "metrics.csv", "failure_cases.md"],}
checks = { "latency_under_80": project["optimized"]["latency_ms"] < 80, "memory_under_512": project["optimized"]["memory_mb"] < 512, "accuracy_drop_ok": project["baseline"]["accuracy"] - project["optimized"]["accuracy"] <= 0.01, "has_failure_cases": "failure_cases.md" in project["evidence"],}
for name, passed in checks.items(): print(name, passed)
release_candidate = all(checks.values())print("release_candidate:", release_candidate)print("evidence_files:", project["evidence"])Run it:
python deployment_project_check.pyExpected output:
latency_under_80 Truememory_under_512 Trueaccuracy_drop_ok Truehas_failure_cases Truerelease_candidate: Trueevidence_files: ['README.md', 'metrics.csv', 'failure_cases.md']This is the shape of a presentable deployment project: not just code, but evidence.
Project Review
Section titled “Project Review”Review the project as a release candidate, not as a notebook. A release candidate has a target, a constraint, a reproducible command, a metric table, and a known limitation. If one of those pieces is missing, the project may still be a useful experiment, but it is not yet a deployment story.
The strongest project write-up is usually narrow. Instead of claiming “I deployed an AI system,” say exactly what you proved: “I simulated an edge image classifier, reduced memory below 512 MB, kept accuracy drop under 1 point, and saved failure cases for review.” Specific evidence makes the project credible.
How To Present The Project
Section titled “How To Present The Project”Use this order:
- Problem: what needs to run, where, and why.
- Constraints: memory, latency, hardware, offline requirement.
- Design: model format, engine, serving path.
- Evidence: before/after metrics and failure cases.
- Trade-off: what you did not optimize yet and why.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Deployment Target
- local inference, edge device, model server, or optimization experiment
- Artifact
- C++ snippet, benchmark, model artifact, serving config, or deployment note
- Metric
- latency, memory, throughput, model size, accuracy drop, or reliability
- Failure Check
- ABI/build issue, hardware mismatch, quantization loss, or serving bottleneck
- Expected Output
- reproducible deployment or optimization evidence, not only theory notes
Common Mistakes
Section titled “Common Mistakes”- Showing only a demo interface and no metrics.
- Optimizing latency but hiding the accuracy drop.
- Claiming edge readiness without a memory or long-running test.
- Making the project too broad, such as cloud, mobile, and edge all at once.
Practice
Section titled “Practice”Add a second target device and rerun the readiness checks. Then write three README lines that explain why the chosen device and engine are reasonable.
Solution approach and explanation
The second device should be added to the same readiness logic, not judged by a separate story. A good README answer can be as short as:
- Chosen Device
- edge-c, because it passes memory, power, and offline checks.
- Chosen Engine
- ONNX Runtime, because it supports the model format and is easier for this project to maintain.
- Known Trade Off
- TensorRT may be faster later, but the current project optimizes repeatable evidence first.
If another device wins after your added constraints, that is fine. The answer is correct when the README lines are backed by the checks and do not hide accuracy, memory, or latency trade-offs.