9.6.4 LlamaIndex
Learning objectives
Section titled “Learning objectives”- Understand LlamaIndex’s core abstract objects
- Understand why it is especially suitable for knowledge and document scenarios
- Understand the chain: Document -> Node -> Index -> Retriever -> Query Engine
- Build judgment for when to prioritize LlamaIndex
Why are many LLM projects actually “knowledge system projects” first?
Section titled “Why are many LLM projects actually “knowledge system projects” first?”Not all systems are solving conversation problems
Section titled “Not all systems are solving conversation problems”The core of many real-world LLM applications is not chatting, but:
- enterprise knowledge base Q&A
- document retrieval
- research material integration
- assisted report generation
What these tasks have in common is:
The way knowledge is organized directly determines system quality.
This is exactly where LlamaIndex is most valuable
Section titled “This is exactly where LlamaIndex is most valuable”It does not just ask, “How do we tune the model?” Instead, it asks:
- how documents enter the system
- how information is split
- how retrieval structures are built
- how queries are organized
So a very practical way to think about it is:
LlamaIndex is more like a knowledge system framework than a pure workflow framework.
First, distinguish the most important concepts
Section titled “First, distinguish the most important concepts”Document
Section titled “Document”The most original unit of knowledge. For example:
- an article
- a PDF
- a piece of webpage content
A smaller unit after a Document has been split. In many knowledge systems, what is actually used for retrieval is often not the whole document, but a finer-grained node.
The way these nodes are organized into a queryable structure.
Retriever
Section titled “Retriever”Responsible for finding the relevant nodes based on the user query.
Query Engine
Section titled “Query Engine”A higher-level layer that combines “query -> retrieval -> result organization” into a more complete unit.
Remember this one sentence first:
Documents are the raw material, nodes are the cut-up raw material, indexes are the storage structure, retrievers find the items, and query engines present the items to the user.
First, go through this chain with pure Python
Section titled “First, go through this chain with pure Python”Document -> Node
Section titled “Document -> Node”documents = [ {"id": "doc1", "text": "You can request a refund within 7 days after purchase if your learning progress is below 20%."}, {"id": "doc2", "text": "You can receive a certificate after completing all projects and passing the test."}]
nodes = []for doc in documents: nodes.append({ "doc_id": doc["id"], "text": doc["text"] })
print(nodes)Expected output:
[{'doc_id': 'doc1', 'text': 'You can request a refund within 7 days after purchase if your learning progress is below 20%.'}, {'doc_id': 'doc2', 'text': 'You can receive a certificate after completing all projects and passing the test.'}]Although this example is simple, it already expresses a core idea:
Original documents are usually not used directly for Q&A. They are first turned into knowledge units that are more suitable for indexing and retrieval.
Why is “document ingestion” the first step in a knowledge system?
Section titled “Why is “document ingestion” the first step in a knowledge system?”Raw documents are usually messy
Section titled “Raw documents are usually messy”Real documents may contain:
- headers and footers
- repeated paragraphs
- table noise
- very long paragraphs
If you do not handle these well first, retrieval later often gets worse too.
So the most common first step in a knowledge system is not “tune the model”
Section titled “So the most common first step in a knowledge system is not “tune the model””It is:
- read the documents
- clean them
- split them
- add metadata
That is why frameworks like LlamaIndex emphasize ingest so much.
Why are indexing and retrieval at its center?
Section titled “Why are indexing and retrieval at its center?”Because knowledge applications fear one thing most: “the documents are there, but the system can’t find them”
Section titled “Because knowledge applications fear one thing most: “the documents are there, but the system can’t find them””If:
- there are many documents
- there are many nodes
- questions are expressed very flexibly
then without a good indexing and retrieval layer, even a very strong model will be dragged down.
A minimal retrieval example
Section titled “A minimal retrieval example”If you want to run this snippet locally, install scikit-learn first.
from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics.pairwise import cosine_similarity
node_texts = [node["text"] for node in nodes]vectorizer = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b")index_matrix = vectorizer.fit_transform(node_texts)
def retrieve(query): query_vec = vectorizer.transform([query]) scores = cosine_similarity(query_vec, index_matrix)[0] best_idx = scores.argmax() return nodes[best_idx]
print(retrieve("What is the refund policy?"))Expected output:
{'doc_id': 'doc1', 'text': 'You can request a refund within 7 days after purchase if your learning progress is below 20%.'}What abstract ideas does this code really correspond to?
Section titled “What abstract ideas does this code really correspond to?”It already corresponds to:
- node
- index
- retriever
In other words, much of LlamaIndex’s value is essentially about organizing this knowledge chain more systematically.
Why is it worth separating out the Query Engine?
Section titled “Why is it worth separating out the Query Engine?”Because Q&A is not just “return the most similar paragraph”
Section titled “Because Q&A is not just “return the most similar paragraph””In a real system, you often still need to decide:
- how many results to return
- whether to summarize them
- whether to include sources
- whether to call the model again
At that point, a “query engine” looks more like a system-level abstraction than a single retriever.
A very simple Query Engine example
Section titled “A very simple Query Engine example”def query_engine(query): node = retrieve(query) return { "answer": node["text"], "source": node["doc_id"] }
print(query_engine("What is the refund policy?"))Expected output:
{'answer': 'You can request a refund within 7 days after purchase if your learning progress is below 20%.', 'source': 'doc1'}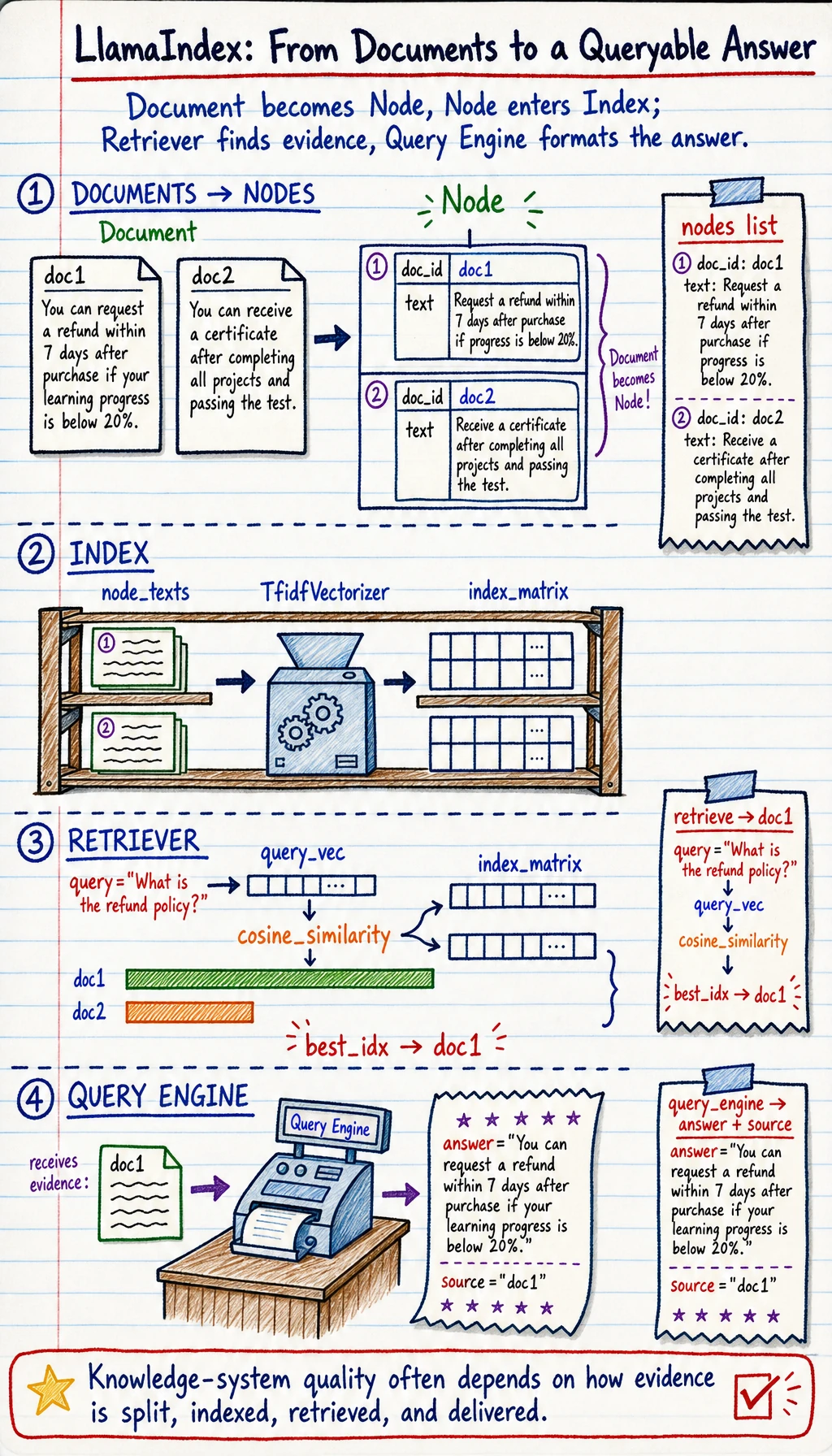
This example is teaching you:
Retrieval is only the middle layer. In the end, you still need a layer that organizes the result into a user-facing query interface.
What is the most important difference between LlamaIndex and LangGraph?
Section titled “What is the most important difference between LlamaIndex and LangGraph?”If we summarize it very roughly, remember this:
- LangGraph is more about “how task states flow”
- LlamaIndex is more about “how knowledge is organized”
Of course, you can mix them in real projects, but their first concerns are indeed different.
So if the essence of your project is:
- document Q&A
- knowledge base assistant
- RAG main pipeline
then abstractions like LlamaIndex will usually feel more natural.
When is LlamaIndex not necessarily the main focus?
Section titled “When is LlamaIndex not necessarily the main focus?”If your system is more about:
- multi-Agent collaboration
- complex loops
- explicit state machines
then LlamaIndex may not be the “main framework,” but rather a knowledge-layer component.
So do not think of it as a “universal Agent framework.” Instead, think of it as:
A framework that is especially convenient for knowledge and retrieval problems.
Common mistakes beginners make
Section titled “Common mistakes beginners make”Looking only at the model and ignoring document ingestion
Section titled “Looking only at the model and ignoring document ingestion”Many knowledge system problems actually come from the document entry point.
Thinking that once indexing is done, the Q&A system is complete
Section titled “Thinking that once indexing is done, the Q&A system is complete”An index is only the middle layer, not the end product.
Not understanding its boundary with workflow-oriented frameworks
Section titled “Not understanding its boundary with workflow-oriented frameworks”This makes it easy to expect it to solve problems that are not its strongest area.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Problem Shape
- workflow graph, retrieval app, role team, or experiment
- Framework Choice
- what abstraction it adds and what control it hides
- Trace
- state, node, tool call, message, or run id
- Failure Check
- framework magic hides state, retries, or permissions
- Decision
- choose framework only after the single-agent loop is clear
Summary
Section titled “Summary”The most important thing in this section is not memorizing LlamaIndex APIs, but understanding:
The value of LlamaIndex lies in organizing document knowledge from raw text into a structure that can be retrieved, cited, and queried.
Once you view it as a “knowledge organization framework” rather than a “universal framework,” many judgments become much clearer.
Exercises
Section titled “Exercises”- Explain in your own words what Document, Node, Index, Retriever, and Query Engine are like.
- Think about why the quality of document ingestion directly affects retrieval results later.
- Recreate 3 nodes using your own knowledge base data and run the retrieval example again.
- Explain: if the main pipeline of the system is multi-Agent collaboration rather than knowledge retrieval, why might LlamaIndex not be the best choice as the “main framework”?
Solution approach and explanation
- Document is the source material, Node is the retrievable chunk, Index is the organized search structure, Retriever selects relevant nodes, and Query Engine combines retrieval with response generation.
- Ingestion quality matters because bad chunking, missing metadata, or noisy parsing becomes retrieval failure later. The model cannot answer well if the right evidence never reaches the context.
- A good rerun with your own data should show which nodes were selected and why. If results are weak, inspect chunk size, overlap, metadata, and whether the query uses the same vocabulary as the documents.
- If the main problem is multi-Agent collaboration, LlamaIndex may still be useful for knowledge retrieval, but it may not be the main orchestration framework because its strongest abstraction starts from documents and indexes.