6.8.3 Project: Text Sentiment Analysis
Learning Objectives
Section titled “Learning Objectives”- Define sentiment labels before choosing a model.
- Build an interpretable keyword baseline.
- Improve one known error type with a simple negation rule.
- Turn wrong predictions into error buckets.
- Package a small NLP project as a reproducible deliverable.
See the Project Loop First
Section titled “See the Project Loop First”
label boundarybaselinepredictionserror bucketstargeted upgrade
Start with binary labels:
positive: clearly recommends, praises, or expresses satisfaction.negative: clearly complains, rejects, or expresses dissatisfaction.
Do not begin with too many labels such as neutral, mixed, irony, and unclear until the basic loop is stable.
Lab: Keyword Baseline and Negation Fix
Section titled “Lab: Keyword Baseline and Negation Fix”Create sentiment_project_baseline.py:
from collections import Counter
def tokenize(text): text = text.lower() for ch in ",.!?": text = text.replace(ch, "") return text.split()
train = [ ("clear examples and practical pace", "positive"), ("recommended and systematic course", "positive"), ("messy confusing and too fast", "negative"), ("unclear examples and weak structure", "negative"),]
val = [ ("clear and practical course", "positive"), ("messy and confusing pace", "negative"), ("not recommended", "negative"),]
positive_words = Counter()negative_words = Counter()
for text, label in train: if label == "positive": positive_words.update(tokenize(text)) else: negative_words.update(tokenize(text))
positive_words.update(["recommended"] * 2)negative_words.update(["messy"] * 2)
def predict(text): score = sum(positive_words[t] - negative_words[t] for t in tokenize(text)) return ("positive" if score >= 0 else "negative"), score
def predict_with_negation(text): score = 0 flip = False
for token in tokenize(text): if token in {"not", "no", "never"}: flip = True continue
token_score = positive_words[token] - negative_words[token] if flip and token_score != 0: token_score *= -1 flip = False
score += token_score
return ("positive" if score >= 0 else "negative"), score
print("sentiment_baseline")for text, gold in val: pred, score = predict(text) print({"gold": gold, "pred": pred, "score": score, "text": text})
print("with_negation")for text, gold in val: pred, score = predict_with_negation(text) print({"gold": gold, "pred": pred, "score": score, "text": text})Run it:
python sentiment_project_baseline.pyExpected output:
sentiment_baseline{'gold': 'positive', 'pred': 'positive', 'score': 3, 'text': 'clear and practical course'}{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'messy and confusing pace'}{'gold': 'negative', 'pred': 'positive', 'score': 3, 'text': 'not recommended'}with_negation{'gold': 'positive', 'pred': 'positive', 'score': 3, 'text': 'clear and practical course'}{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'messy and confusing pace'}{'gold': 'negative', 'pred': 'negative', 'score': -3, 'text': 'not recommended'}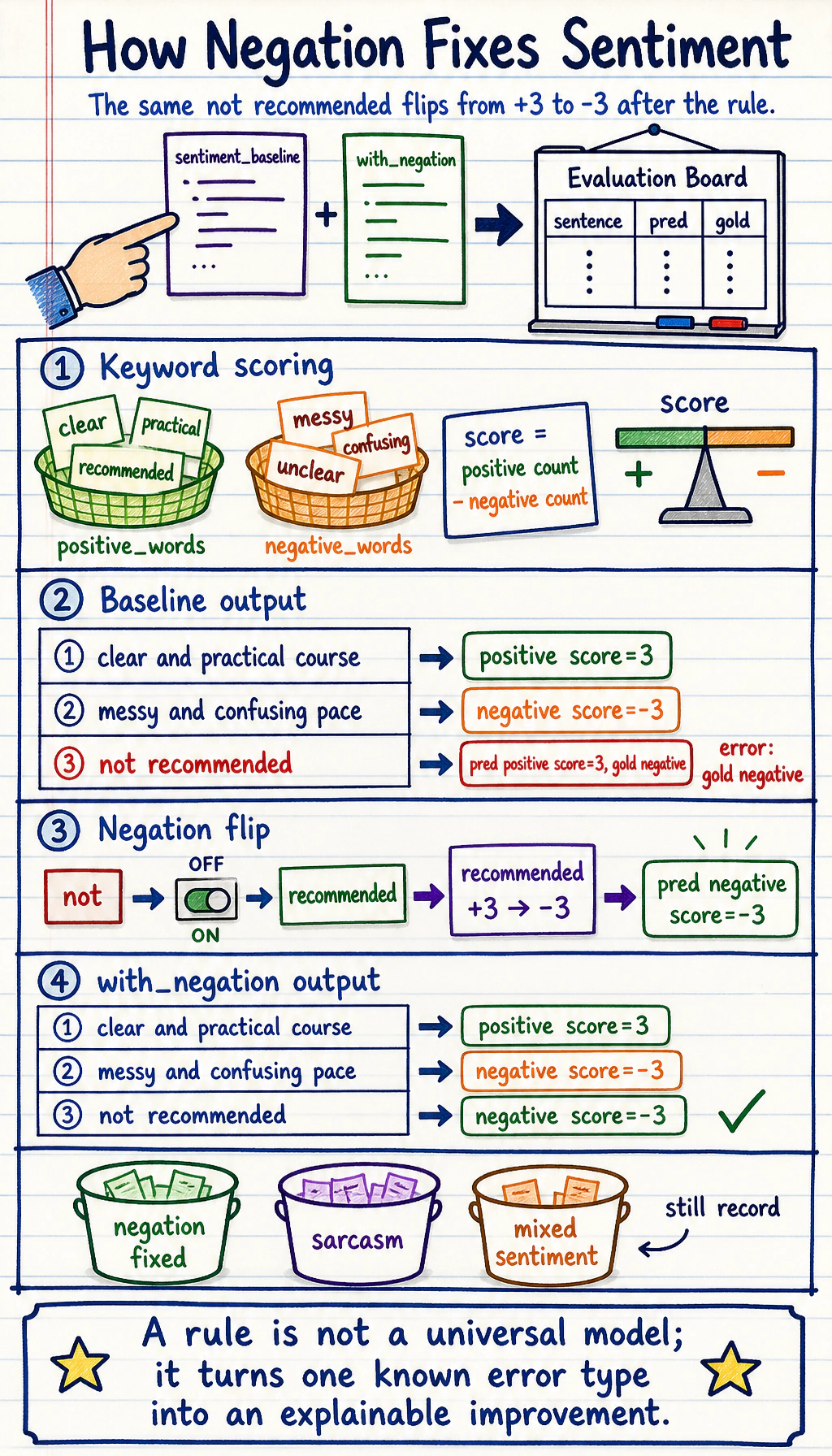
What this teaches:
- the baseline is explainable because every token changes the score;
not recommendedfails before the negation rule;- a targeted rule fixes one error type without pretending to solve all language understanding.
Error Buckets
Section titled “Error Buckets”Wrong cases should be grouped by type, not hidden.
error_buckets = { "negation": [], "sarcasm": [], "mixed_sentiment": [], "other": [],}
examples = [ ("Not recommended for this course", "negative", "positive"), ("Great, it got stuck again", "negative", "positive"), ("The content is great, but the pace is too fast", "negative", "positive"),]
for text, gold, pred in examples: lower = text.lower() if "not" in lower: error_buckets["negation"].append(text) elif "great" in lower and "again" in lower: error_buckets["sarcasm"].append(text) elif "but" in lower: error_buckets["mixed_sentiment"].append(text) else: error_buckets["other"].append(text)
for name, rows in error_buckets.items(): print(name, len(rows), rows)This is project evidence. It shows what the model fails at and what you would improve next.
Upgrade Path
Section titled “Upgrade Path”| Version | What to add | Why |
|---|---|---|
| rule baseline | keyword counts and negation rule | explainable starting point |
| traditional ML | TF-IDF + LogisticRegression | stronger baseline with low cost |
| neural baseline | embedding + pooling or small Transformer | learn representation features |
| portfolio version | error buckets, comparison table, demo command | shows engineering judgment |
What to Show in the README
Section titled “What to Show in the README”Keep the README concrete:
- label definitions;
- dataset source and split;
- run command;
- baseline comparison table;
- error buckets;
- examples the model gets right and wrong;
- next-step plan.
Evidence to Keep
Section titled “Evidence to Keep”A sentiment project should leave this minimum evidence:
- Label Rules
- positive and negative boundaries
- Baseline
- keyword or TF-IDF baseline
- Known Failure
- negation, sarcasm, or mixed sentiment
- Fix Attempt
- one targeted rule or model change
- Error Buckets
- grouped wrong predictions
- Next Action
- data labeling, features, or model upgrade
Common Mistakes
Section titled “Common Mistakes”| Mistake | Fix |
|---|---|
| labels are vague | write label rules before training |
| only reporting accuracy | include error buckets and examples |
| ignoring negation | test not, never, and no cases |
| adding a deep model too early | keep a rule or TF-IDF baseline |
| hiding sarcasm/mixed sentiment errors | document them as known limitations |
Exercises
Section titled “Exercises”- Add
"not clear"and"never useful"to validation examples. - Add an
otherbucket example that your rules cannot classify. - Replace keyword counts with TF-IDF in your project plan.
- Write a label rule for
neutral, but do not add it to the model yet. - Create a README outline for this project.
Project reference and review notes
"not clear"is likely neutral or uncertain, while"never useful"should probably be negative. These examples test whether the rule system handles negation and weak sentiment.- Good
otherexamples include sarcasm, mixed languages, or text that is about shipping or price rather than sentiment. The goal is to keep unclear inputs from being forced into a wrong label. - TF-IDF should become the feature extraction step before the classifier. The plan should mention vocabulary, vectorization, train/validation split, and metrics.
- A simple
neutralrule might catch texts with no strong positive or negative keyword, or texts where positive and negative cues cancel out. Keep it separate until you can evaluate it. - The README should include task definition, labels, dataset examples, baseline, metric, error examples, and next model upgrade.
Key Takeaways
Section titled “Key Takeaways”- Sentiment projects live or die by label boundaries and error analysis.
- Simple baselines are useful because they are explainable.
- Negation is a classic first failure type.
- Error buckets make the project stronger than a single accuracy score.