E.C.4 Linear Discriminant Analysis
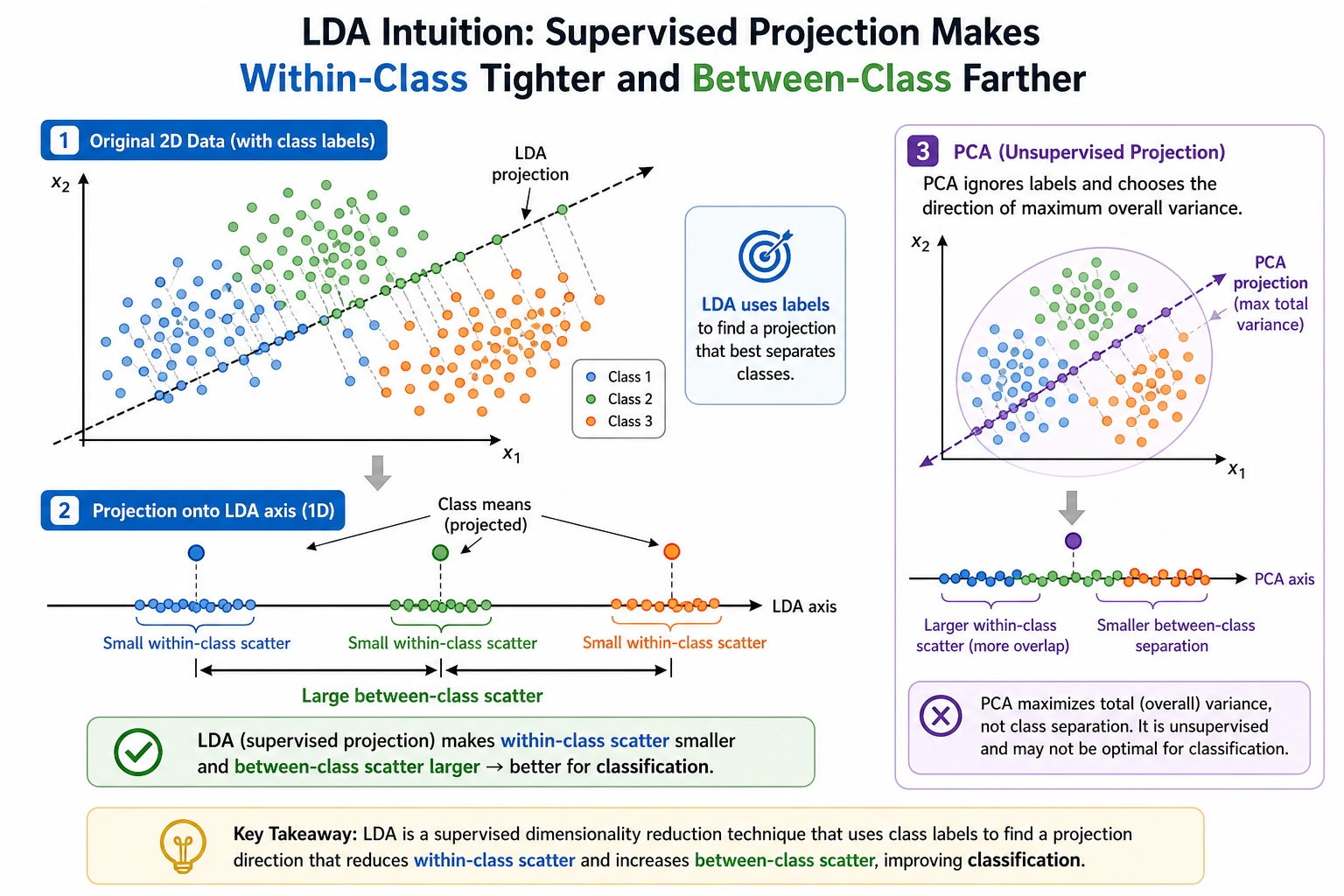
LDA finds a projection that keeps samples from the same class close and different classes far apart. It can act as a classifier and as supervised dimensionality reduction.
What You Need
Section titled “What You Need”- Python 3.10+
- Current stable
scikit-learnandnumpy
python -m pip install -U scikit-learn numpyKey Terms
Section titled “Key Terms”- Within-class variance: how spread out each class is.
- Between-class separation: how far class centers are from each other.
- Projection: mapping features into fewer dimensions.
- Supervised dimensionality reduction: reducing dimensions while using labels.
- LDA here: Linear Discriminant Analysis, not Latent Dirichlet Allocation.
Run LDA Classification And Projection
Section titled “Run LDA Classification And Projection”Create lda_projection.py:
import numpy as npfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X = np.array([ [1.0, 2.0], [1.5, 1.8], [2.0, 1.5], [4.0, 5.0], [4.5, 4.8], [5.0, 4.5],])y = np.array([0, 0, 0, 1, 1, 1])
model = LinearDiscriminantAnalysis(n_components=1)model.fit(X, y)
pred = model.predict([[1.4, 1.9], [4.8, 4.6]])projection = model.transform(X)
print("predictions:", pred.tolist())print("projection_shape:", projection.shape)Run it:
python lda_projection.pyExpected output:
predictions: [0, 1]projection_shape: (6, 1)The same model classified new points and projected the training data into one discriminative direction.
Baseline Review
Section titled “Baseline Review”Review LDA by checking whether classes become easier to separate after projection. The projection is not just compression; it is label-aware compression, so the result should help class separation.
Use LDA when you want a lightweight classifier or a supervised view of features. If the classes overlap heavily or form curved boundaries, record that limitation and compare with SVM, tree models, or a later neural baseline.
Compare With PCA
Section titled “Compare With PCA”PCA finds directions with high overall variance and ignores labels. LDA uses labels and asks which direction separates classes best. That makes LDA useful when class separation matters more than general compression.
Practical Rule
Section titled “Practical Rule”Try LDA when:
- Labels are available.
- Classes are reasonably compact.
- You want a lightweight linear baseline.
- You want a low-dimensional representation for visualization or downstream models.
Avoid it as the first choice when class boundaries are highly nonlinear.
Baseline Review
Section titled “Baseline Review”Review LDA by checking whether the projected space actually separates classes better than the raw features. A small plot, a class mean table, or a before/after score is enough evidence for this page.
Do not treat projection as guaranteed improvement. If classes overlap after projection, write that down and compare with SVM, KNN, or a tree-based baseline. The value of LDA is the explanation of separation, not just another transformed matrix.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Model Family
- SVM, KNN, Naive Bayes, LDA, or another classical baseline
- Dataset View
- feature scale, class balance, decision boundary, and train/test split
- Metric
- accuracy/F1, confusion matrix, margin, neighbor behavior, or projection quality
- Failure Check
- scaling, high dimensionality, weak assumptions, leakage, or poor baseline fit
- Expected Output
- classical-ML baseline result with one limitation note
Common Mistakes
Section titled “Common Mistakes”- Confusing this LDA with topic-model LDA.
- Assuming LDA is always better than PCA because it uses labels.
- Forgetting that with two classes, LDA can project to at most one component.
Practice
Section titled “Practice”Add a third class and set n_components=2. Then print the new projection shape and explain why the maximum number of components changed.
Project reference and review notes
With three classes, LDA can project to at most classes - 1 = 2 discriminative components, assuming the feature dimension also allows it. If you add three points for class 2 and set n_components=2, the transformed data should have two columns, such as (9, 2) when you now have nine rows.
The important explanation is that LDA directions separate classes. Two classes need at most one separating direction; three classes can need two.