11.7.1 Project Roadmap: Build an Evaluatable NLP Pipeline
An NLP project is not a fluent paragraph. It is a clear task boundary, data source, baseline, evaluation method, failure analysis, and structured deliverable.
See the Project Evidence Loop First
Section titled “See the Project Evidence Loop First”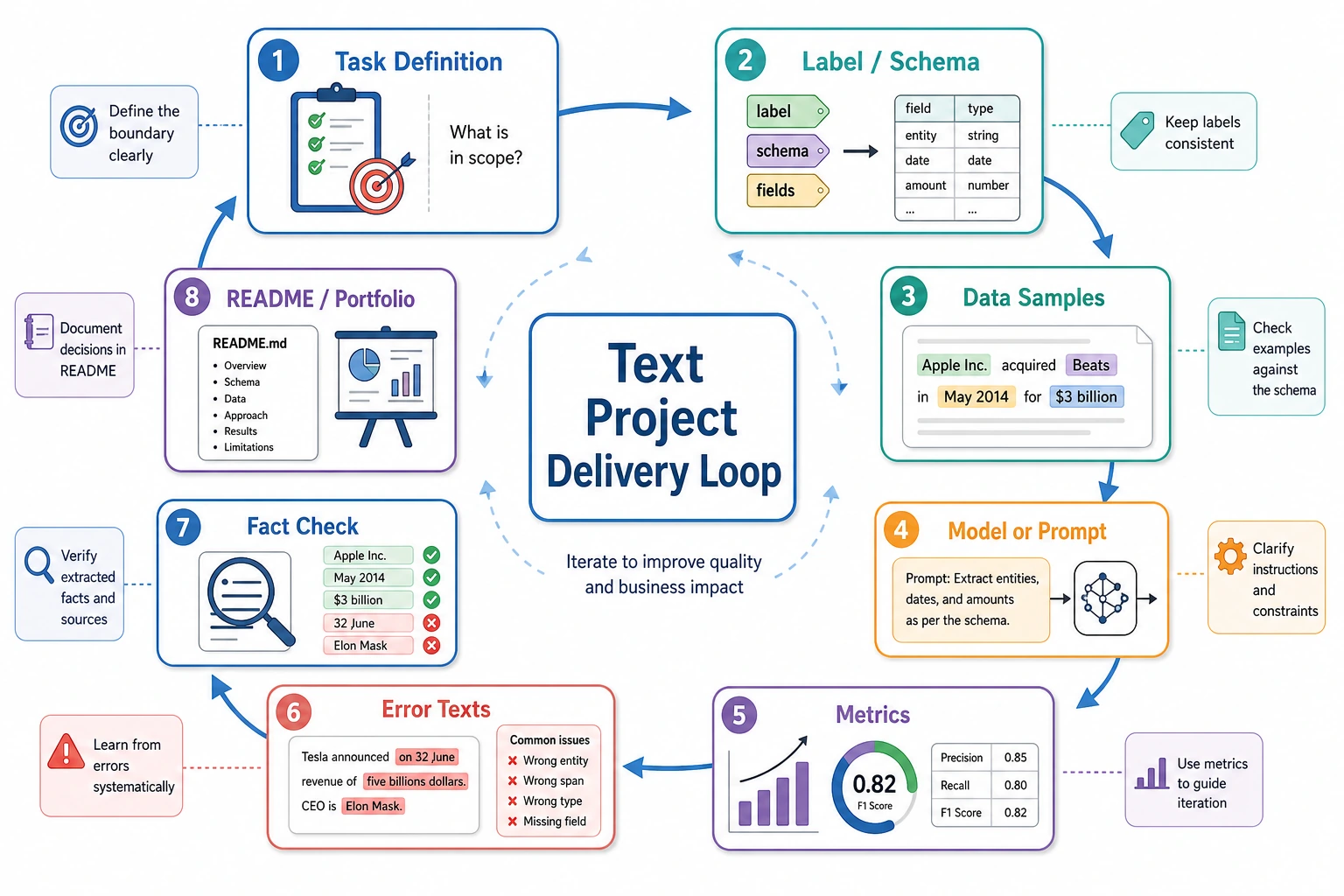
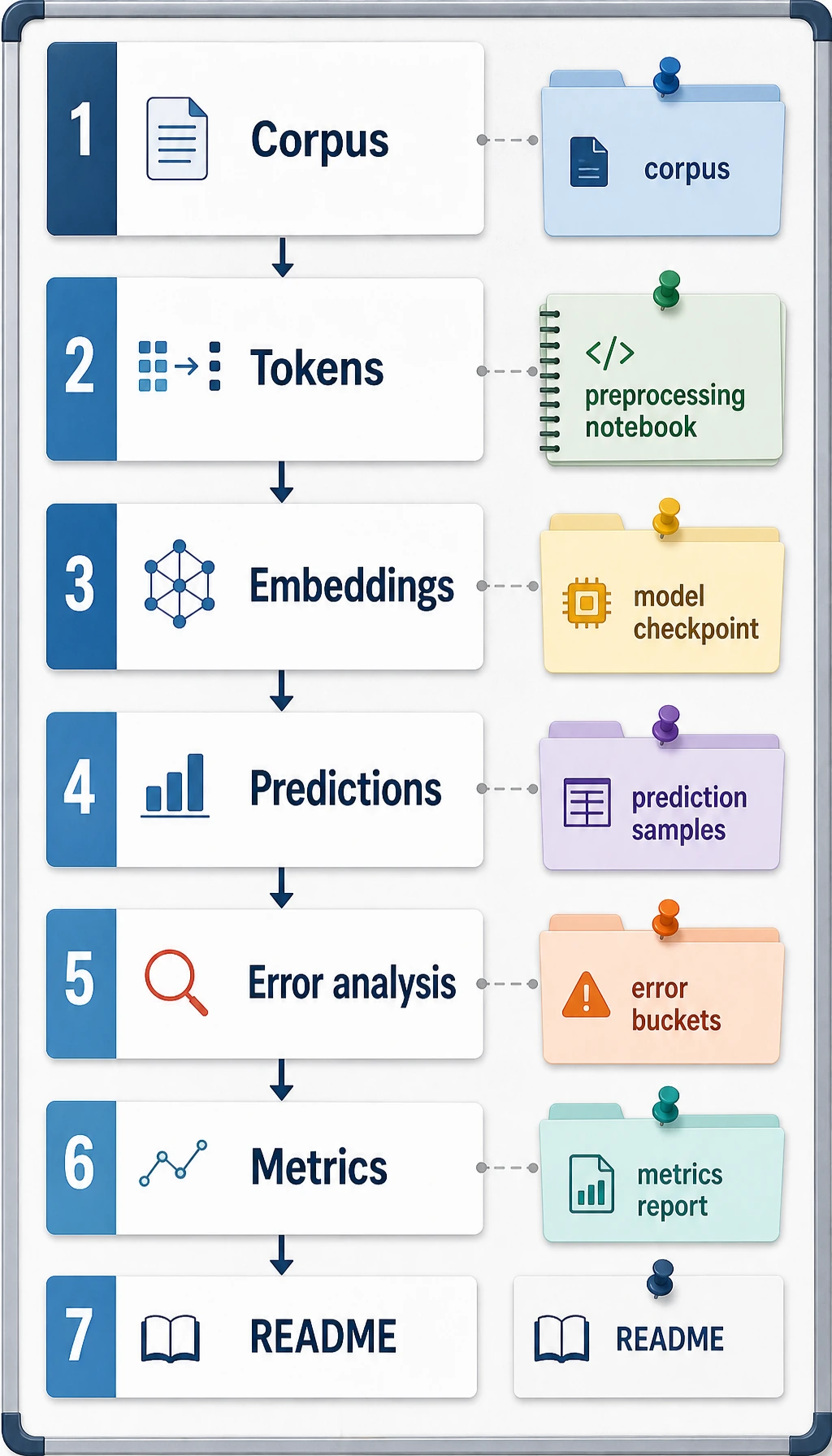
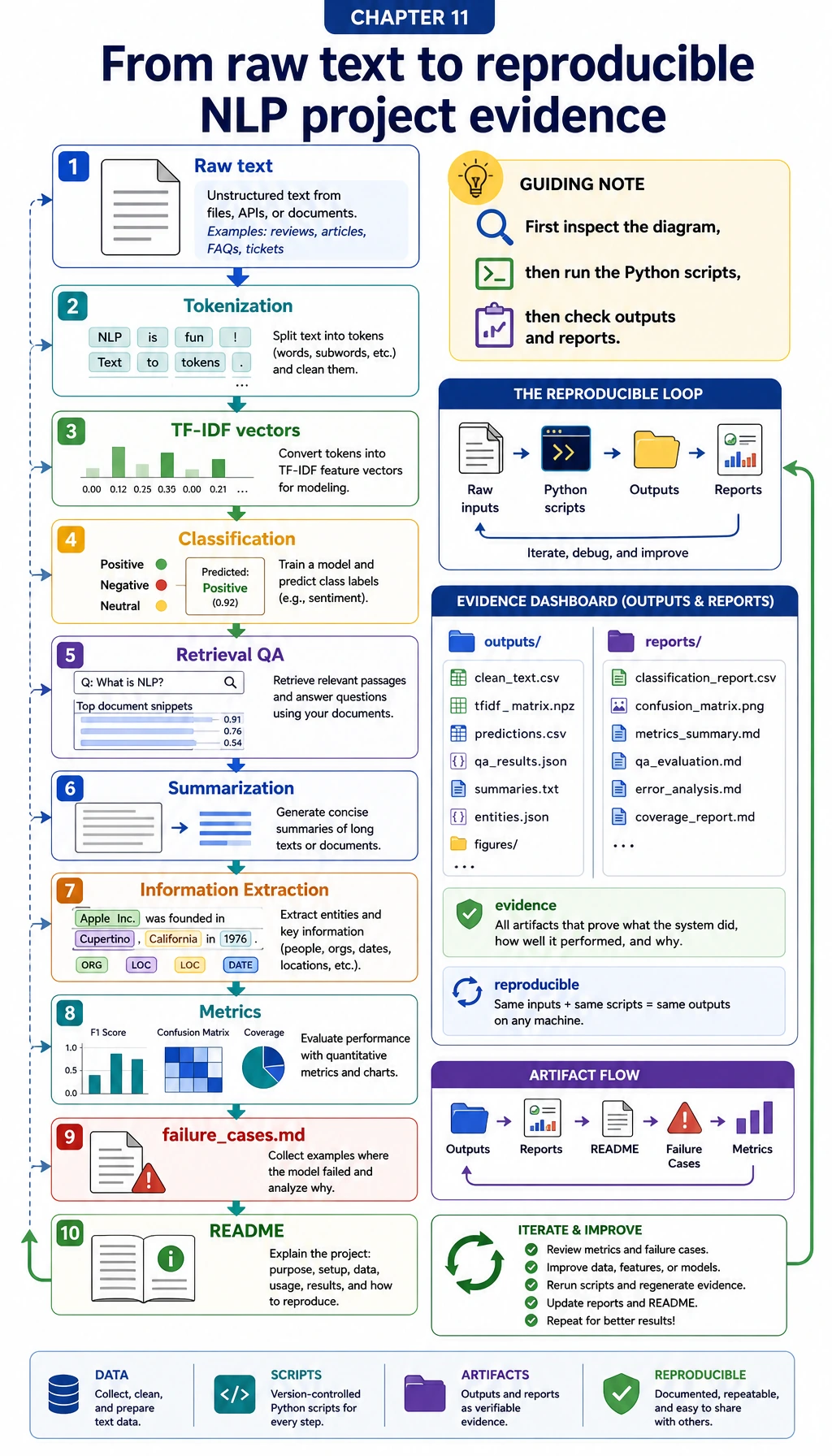
Start with information extraction or classification for clear labels. Move to summarization and QA when you can evaluate factuality, refusal, citations, and boundaries.
Run a Project Readiness Check
Section titled “Run a Project Readiness Check”project = { "task": "information extraction", "has_schema": True, "has_baseline": True, "has_eval_cases": True, "has_failure_case": True,}
ready = all(project[key] for key in ["has_schema", "has_baseline", "has_eval_cases", "has_failure_case"])
print("task:", project["task"])print("portfolio_ready:", ready)Expected output:
task: information extractionportfolio_ready: TrueIf labels, fields, or knowledge boundaries are unclear, fix the task definition before changing models.
Learn in This Order
Section titled “Learn in This Order”| Step | Project | Evidence |
|---|---|---|
| 1 | Information extraction | Schema, field boundaries, precision/recall, failure examples |
| 2 | Text classification | Labels, baseline, F1, ambiguity cases |
| 3 | Summarization | Compression, factuality, readability, missing facts |
| 4 | QA | Retrieval, citation, refusal, no-answer evaluation |
| 5 | Hands-on workshop | Reproducible mini pipeline before larger project pages |
Run 11.7.6 Hands-on: Build a Reproducible NLP Mini Pipeline before expanding the project.
Project Deliverable Standards
Section titled “Project Deliverable Standards”| Deliverable | Minimum Requirement | Stronger Portfolio Version |
|---|---|---|
| README | Goal, run command, dependencies, examples | Add task boundary, data source, trade-offs, review summary |
| Label/schema | Labels, entity boundaries, or output fields | Add positive, negative, boundary examples, consistency notes |
| Baseline | Keyword, TF-IDF, rule, or simple model | Add model comparison and error attribution |
| Evaluation | Accuracy, recall, F1, human score, or factuality check | Add analysis by label, length, domain, and noise type |
| Failure case | At least 1 real failure | Add cause, fix action, regression check |
| Presentation | Screenshot or short GIF proving it runs | Build a clear text-understanding project page |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Task Output
- label, entity fields, summary, answer, retrieval result, or semantic graph
- Artifacts
- raw text, processed text, predictions, metrics, and failure cases
- Metric
- accuracy/F1, precision/recall, retrieval hit rate, faithfulness, or schema validity
- Failure Check
- unclear labels, over-cleaning, boundary errors, hallucination, or unsupported answer
- Expected Output
- reproducible text pipeline folder with metrics and examples
Pass Check
Section titled “Pass Check”You pass this chapter when your NLP project has a task definition, data examples, evaluation metric, baseline, failure case, and next-step improvement plan.
Check reasoning and explanation
- A passing answer starts from the text unit and output type: token, span, sentence label, sequence, embedding, or generated text.
- The evidence should include a small dataset example, model or pipeline choice, metric, and at least one inspected error case.
- A good self-check distinguishes preprocessing issues from model issues, such as tokenization mistakes, label ambiguity, data imbalance, or hallucinated generation.