5.5.1 Feature Engineering Roadmap: Make Data Easier to Learn
Feature engineering is the work of making inputs useful, stable, and safe for models. Many model problems are actually feature problems.
Look at the Feature Flow First
Section titled “Look at the Feature Flow First”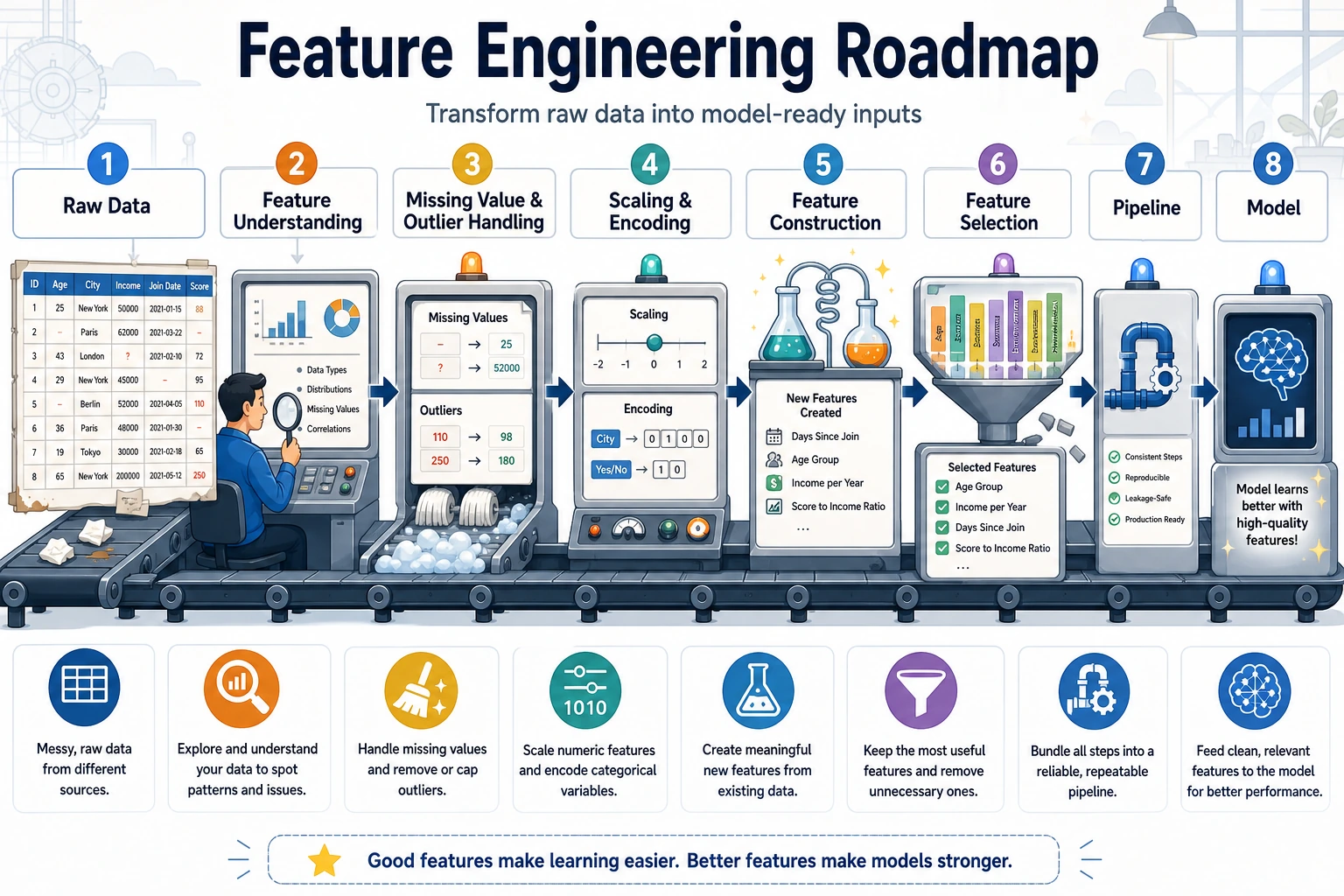
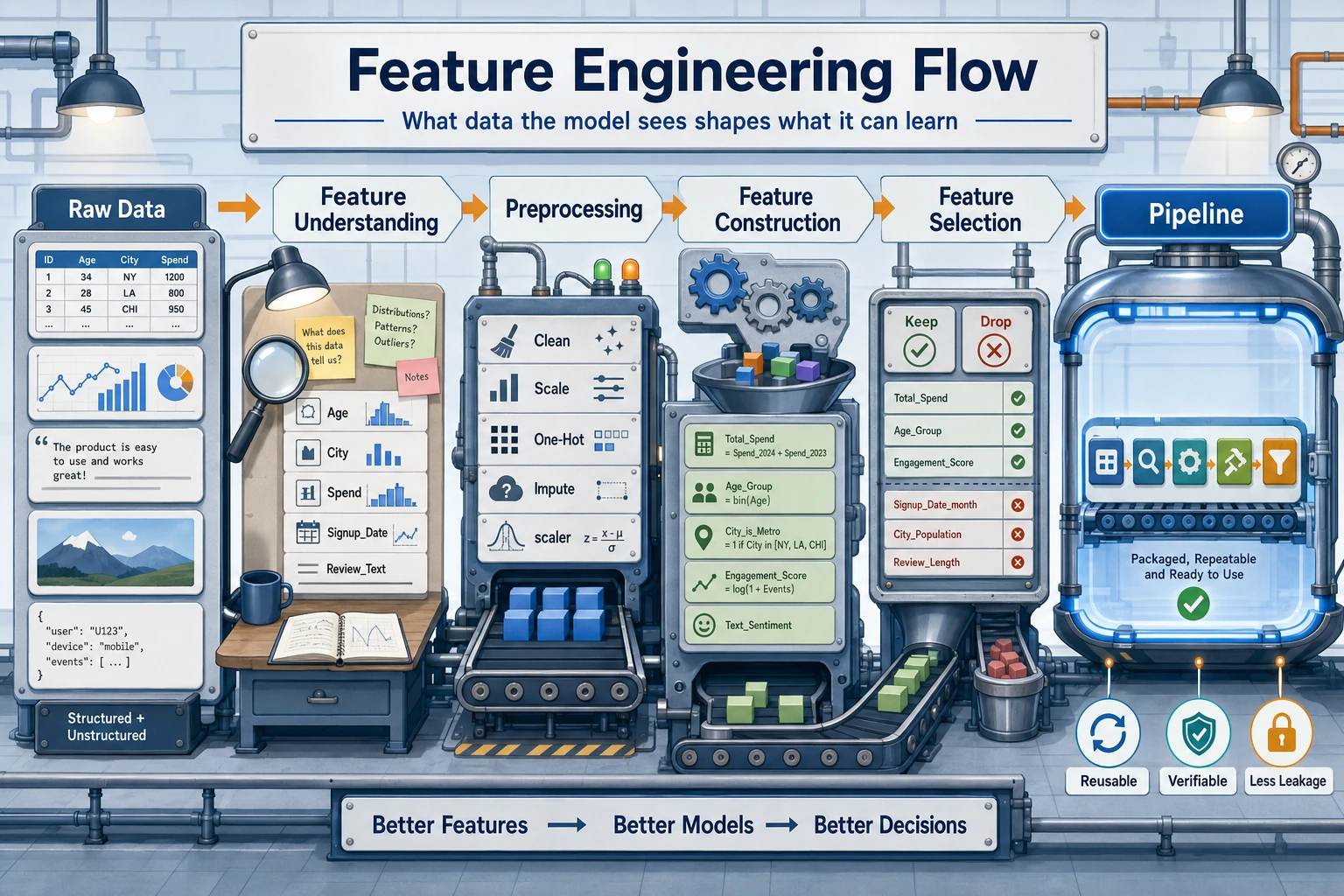
understand columnspreprocessconstructselectpackage as Pipeline
| Step | First action |
|---|---|
| understand | list numeric, categorical, text, date, target columns |
| preprocess | scale, encode, fill missing values |
| construct | create ratios, counts, dates, interactions |
| select | remove useless or leaking features |
| pipeline | make preprocessing reproducible |
Run One Pipeline
Section titled “Run One Pipeline”Create feature_first_loop.py and run it after installing pandas and scikit-learn.
import pandas as pdfrom sklearn.compose import ColumnTransformerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import OneHotEncoder, StandardScaler
X = pd.DataFrame( { "age": [22, 35, 47, 52, 28, 41], "city": ["A", "B", "A", "C", "B", "C"], "visits": [2, 6, 5, 9, 3, 7], })y = [0, 1, 1, 1, 0, 1]
preprocess = ColumnTransformer( transformers=[ ("num", StandardScaler(), ["age", "visits"]), ("cat", OneHotEncoder(handle_unknown="ignore"), ["city"]), ])
pipe = Pipeline([("preprocess", preprocess), ("model", LogisticRegression())])pipe.fit(X, y)
print("pipeline_steps:", list(pipe.named_steps))print("training_accuracy:", round(pipe.score(X, y), 3))Expected output:
pipeline_steps: ['preprocess', 'model']training_accuracy: 1.0This tiny dataset is too small for real evaluation. The point is the workflow: preprocessing and model travel together.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to practice |
|---|---|---|
| 1 | 5.5.2 Feature Understanding | feature types, target, leakage risk |
| 2 | 5.5.3 Data Preprocessing | scaling, encoding, missing values |
| 3 | 5.5.4 Feature Construction | ratios, bins, dates, interactions |
| 4 | 5.5.5 Feature Selection | remove noise, redundancy, leakage |
| 5 | 5.5.6 Pipeline | reproducible preprocessing and training |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Feature State
- raw columns, types, missing values, scale, and target relationship
- Transformation
- preprocessing, construction, selection, or pipeline step
- Output
- transformed feature table, pipeline object, score change, or selected features
- Failure Check
- leakage, inconsistent train/test transform, high-cardinality trap, or meaningless feature
- Expected Output
- feature pipeline evidence with before/after and metric impact
Pass Check
Section titled “Pass Check”You pass this roadmap when you can list feature types, build one preprocessing Pipeline, and explain why preprocessing outside the train/test workflow can cause leakage.
Check reasoning and explanation
- Start by listing feature types, missing values, scale differences, categorical cardinality, and possible target leakage.
- Preprocessing should live inside a
PipelineorColumnTransformerso train and test data receive the same learned transformation without leaking information. - A useful feature change includes before/after evidence: transformed columns, score change, error sample change, or a reason to reject the feature.