11.4.1 Sequence Labeling Roadmap: One Label per Token
Sequence labeling predicts one label for each token. NER, word segmentation, part-of-speech tagging, and slot filling all use this idea.
See the Label Path First
Section titled “See the Label Path First”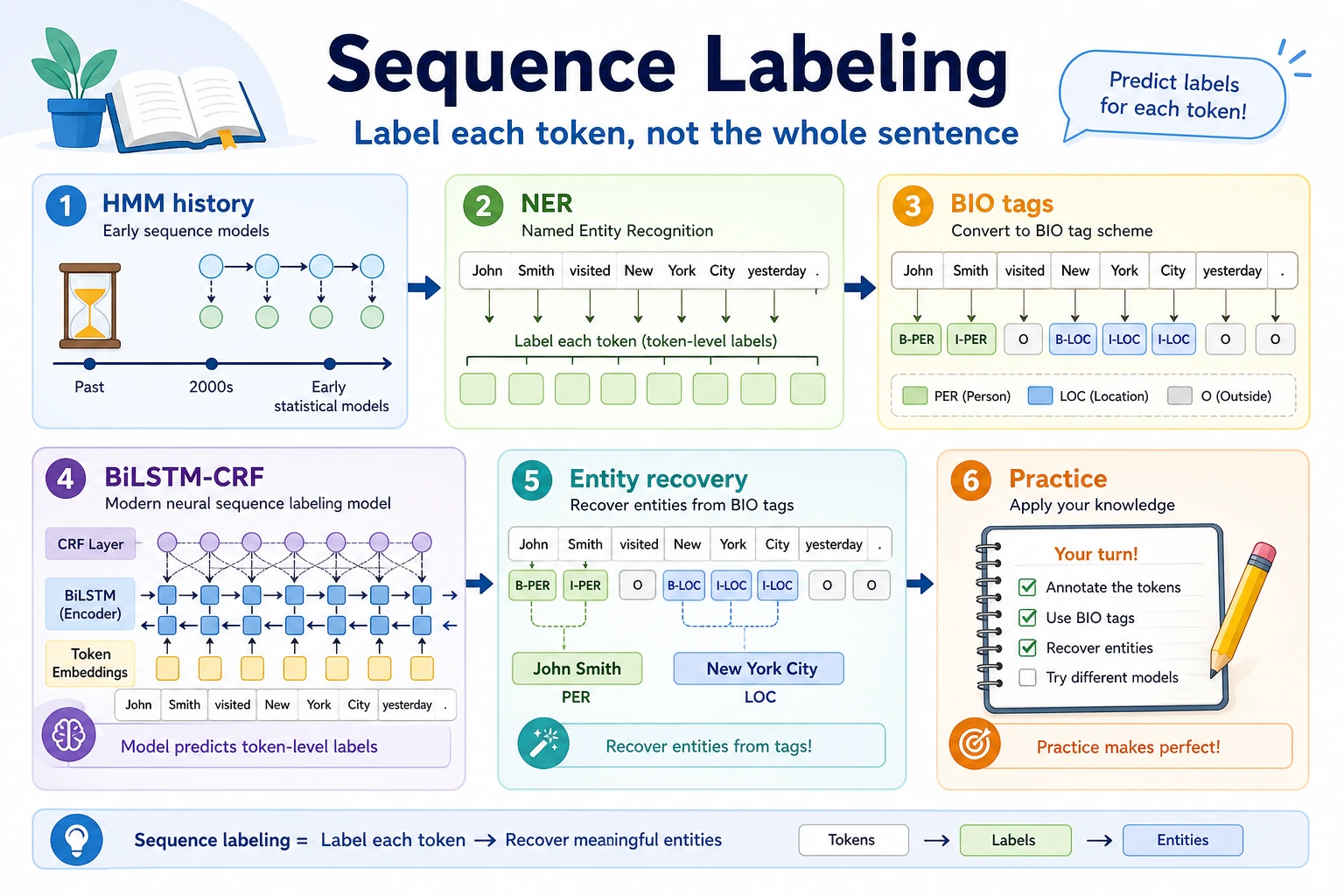

The key output is not one sentence label, but aligned token-level tags such as B-PER, I-PER, and O.
Run a BIO Tag Check
Section titled “Run a BIO Tag Check”tokens = ["Ada", "Lovelace", "wrote", "notes"]tags = ["B-PER", "I-PER", "O", "O"]
for token, tag in zip(tokens, tags): print(token, tag)Expected output:
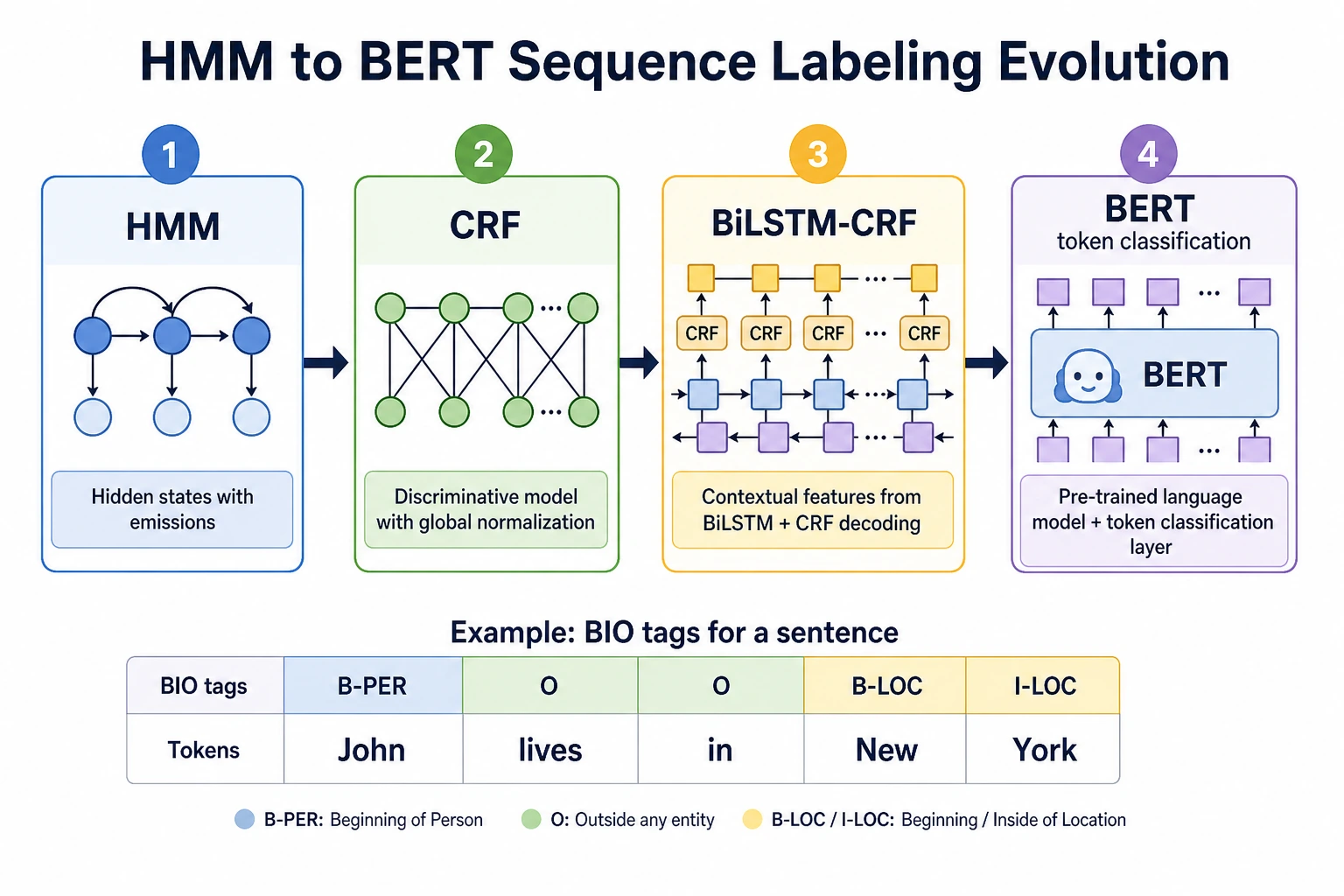
Ada B-PERLovelace I-PERwrote Onotes OIf tokenization changes, labels must stay aligned. Many sequence-labeling bugs are alignment bugs.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | NER and BIO | Create token-level labels and entity spans |
| 2 | HMM/CRF history | Understand sequence constraints and label transitions |
| 3 | BiLSTM-CRF | Connect contextual features with valid label paths |
| 4 | Project practice | Evaluate precision, recall, F1, boundary errors |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Schema
- entity types, BIO tags, or sequence-label rules
- Prediction
- token-level labels and extracted spans
- Metric
- entity precision/recall/F1 and boundary cases
- Failure Check
- span boundary, nested entity, unknown word, or inconsistent annotation
- Expected Output
- gold-vs-predicted span table with at least one miss
Pass Check
Section titled “Pass Check”You pass this chapter when you can inspect token/tag alignment and explain one boundary error or invalid tag transition.
Check reasoning and explanation
- A passing answer starts from the text unit and output type: token, span, sentence label, sequence, embedding, or generated text.
- The evidence should include a small dataset example, model or pipeline choice, metric, and at least one inspected error case.
- A good self-check distinguishes preprocessing issues from model issues, such as tokenization mistakes, label ambiguity, data imbalance, or hallucinated generation.