7.6.1 Finetuning Roadmap: Data, LoRA, Evaluation
Finetuning changes model behavior by training on examples. It is useful for stable task patterns, repeated formats, domain style, or behavior habits. It is usually not the first fix for missing private knowledge; that is often a RAG problem.
See the Decision Loop First
Section titled “See the Decision Loop First”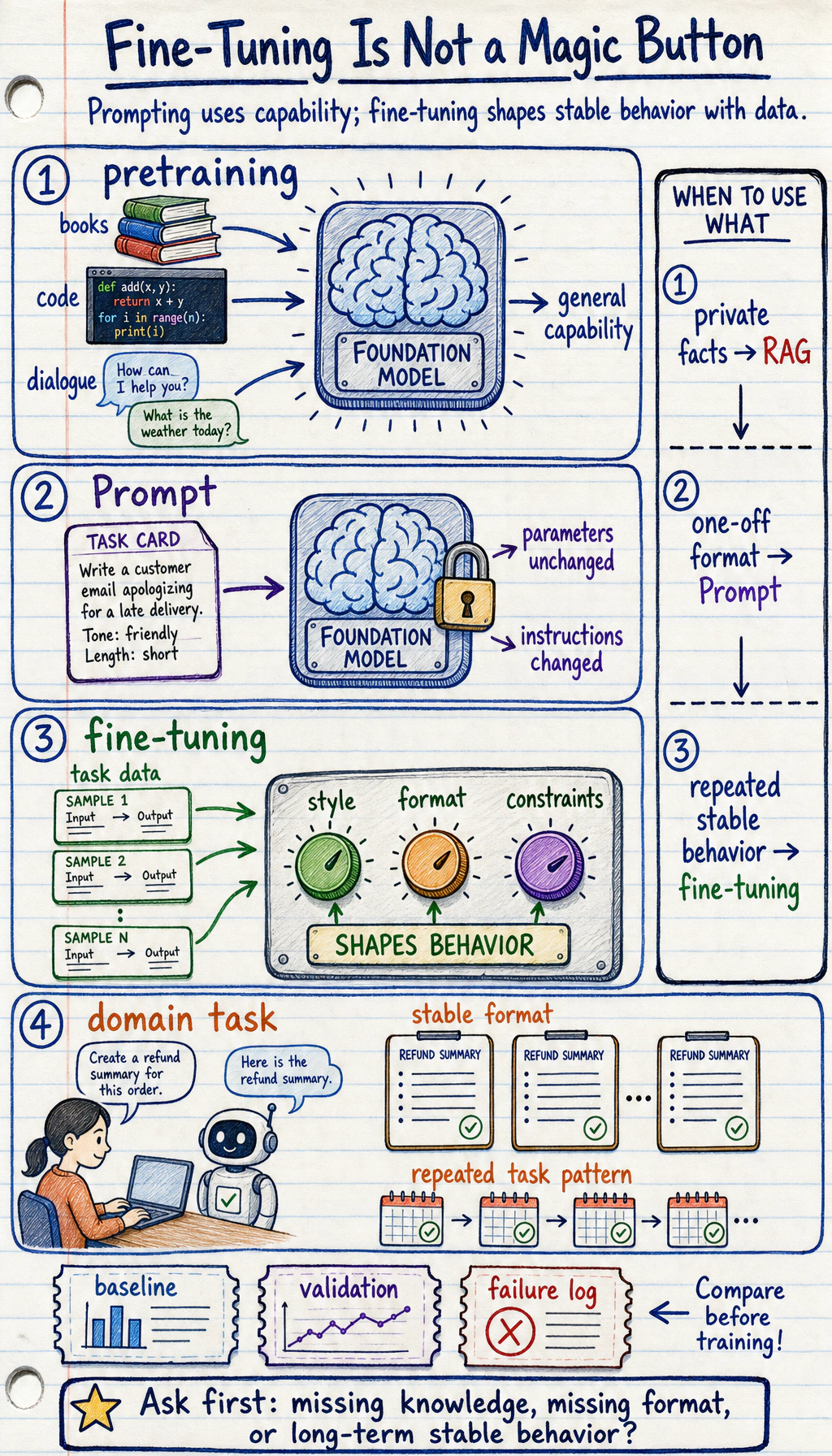

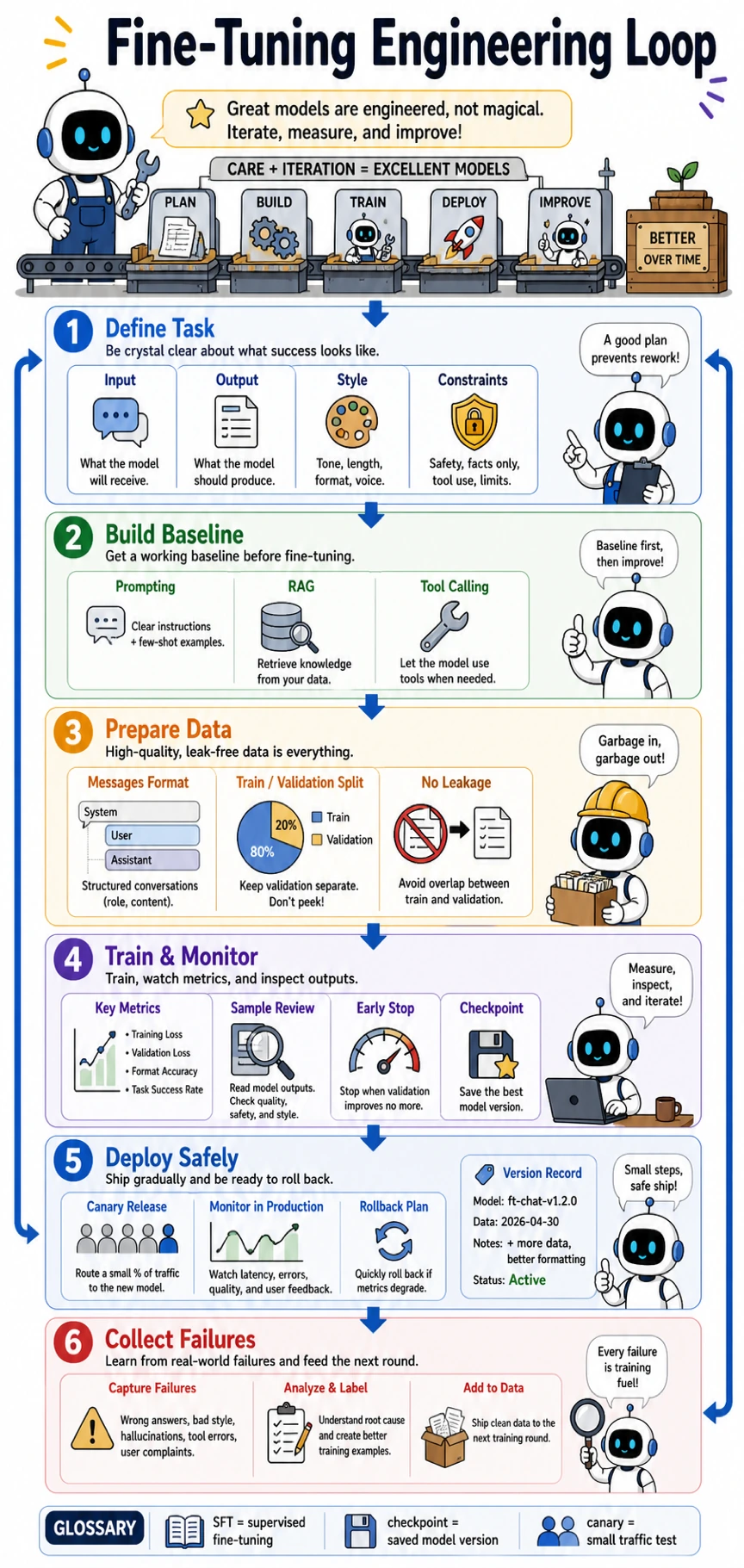
Key terms: LoRA means low-rank adapters, QLoRA means quantized LoRA, and PEFT means parameter-efficient fine-tuning. They reduce cost by training a small set of extra parameters instead of every model weight.
Run a Finetuning Route Check
Section titled “Run a Finetuning Route Check”Use this check before you start training. A finetuning run without a prompt baseline, validation set, and failure log is hard to judge.
case = { "private_facts": False, "format_drift": True, "stable_task": True, "labeled_examples": 120,}
if case["private_facts"]: route = "RAG first"elif case["format_drift"] and case["stable_task"] and case["labeled_examples"] >= 50: route = "fine-tuning candidate"else: route = "prompt baseline first"
print("route:", route)print("minimum_before_training:", ["prompt baseline", "validation set", "failure log"])Expected output:
route: fine-tuning candidateminimum_before_training: ['prompt baseline', 'validation set', 'failure log']Change one value at a time and rerun it. For example, set private_facts to True; the decision should move to RAG first.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | Finetuning overview | Write when to use prompt, RAG, or finetuning |
| 2 | LoRA / QLoRA | Explain what parameters are trained and why cost drops |
| 3 | Other PEFT methods | Know that full finetuning is not the only path |
| 4 | Finetuning practice | Prepare train/validation examples and one run command |
| 5 | Data labeling | Audit samples for format, duplicates, leakage, and edge cases |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Decision
- why prompt/RAG/tooling is not enough
- Data Shape
- instruction, input, output, metadata
- Method
- full finetune, LoRA, QLoRA, or other PEFT
- Eval Set
- fixed cases before training starts
- Risk
- overfitting, style drift, safety regression, or cost
Pass Check
Section titled “Pass Check”You pass this chapter when you can say why finetuning is worth trying, show the baseline it beats, and keep a validation set that was not used for training.
The exit mini project is a small instruction-tuning plan: choose one fixed task, prepare dozens to hundreds of examples, define a prompt baseline, and compare format stability or accuracy after a LoRA/QLoRA run.
Check reasoning and explanation
- A passing answer explains how tokens, context, attention, prompts, and generation behavior connect in one request-response path.
- The evidence should include at least one reproducible prompt or structured-output test, plus notes on why the output passed or failed.
- A good self-check separates prompt design, RAG, fine-tuning, and alignment: use the lightest method that fixes the observed problem.