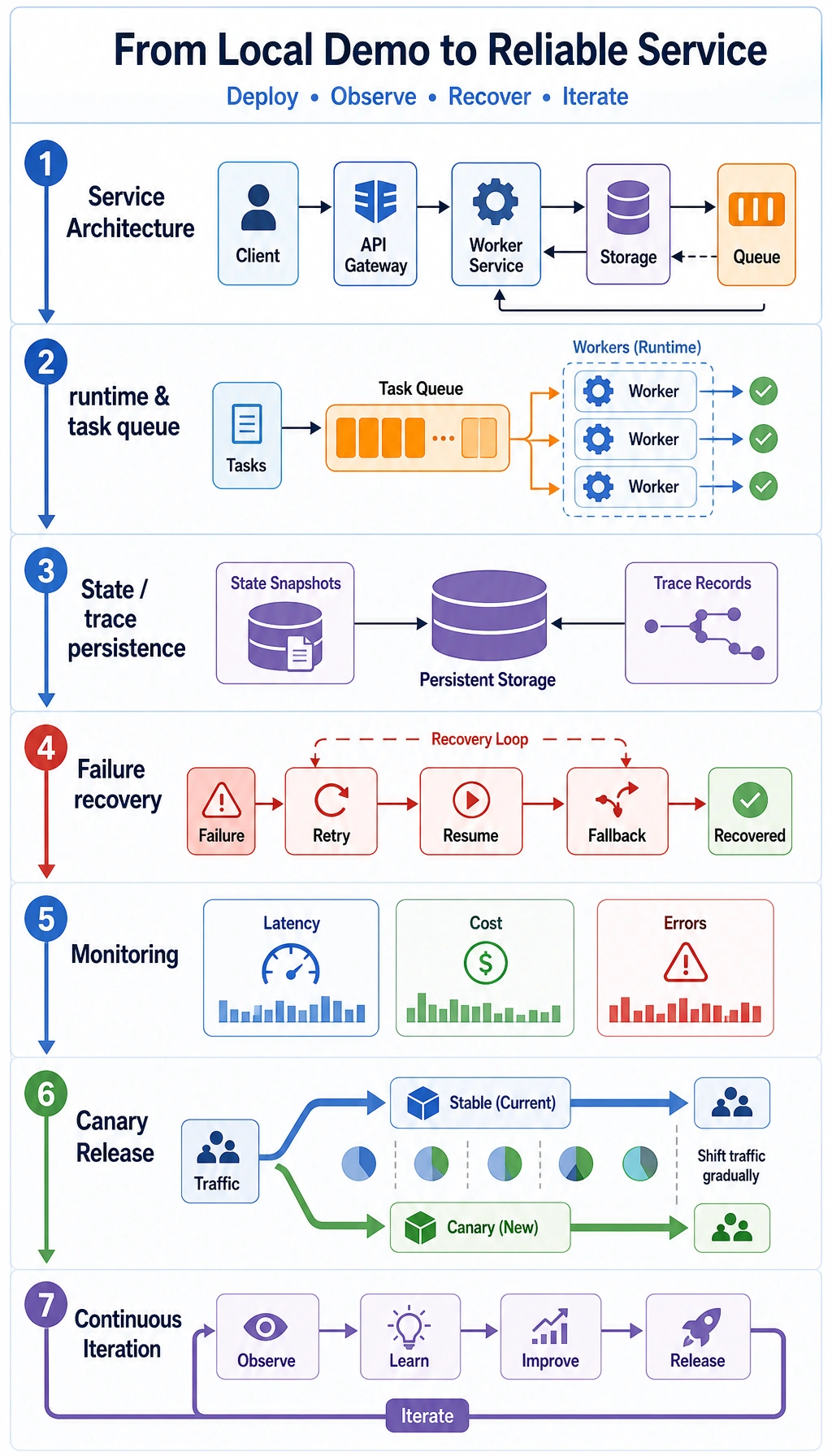
9.9.1 Deployment Roadmap: Runtime, Persistence, Recovery
Deploying an Agent means more than putting code on a server. You need model calls, tool services, queues, state storage, traces, permissions, cost limits, and rollback paths.
See the Runtime Loop First
Section titled “See the Runtime Loop First”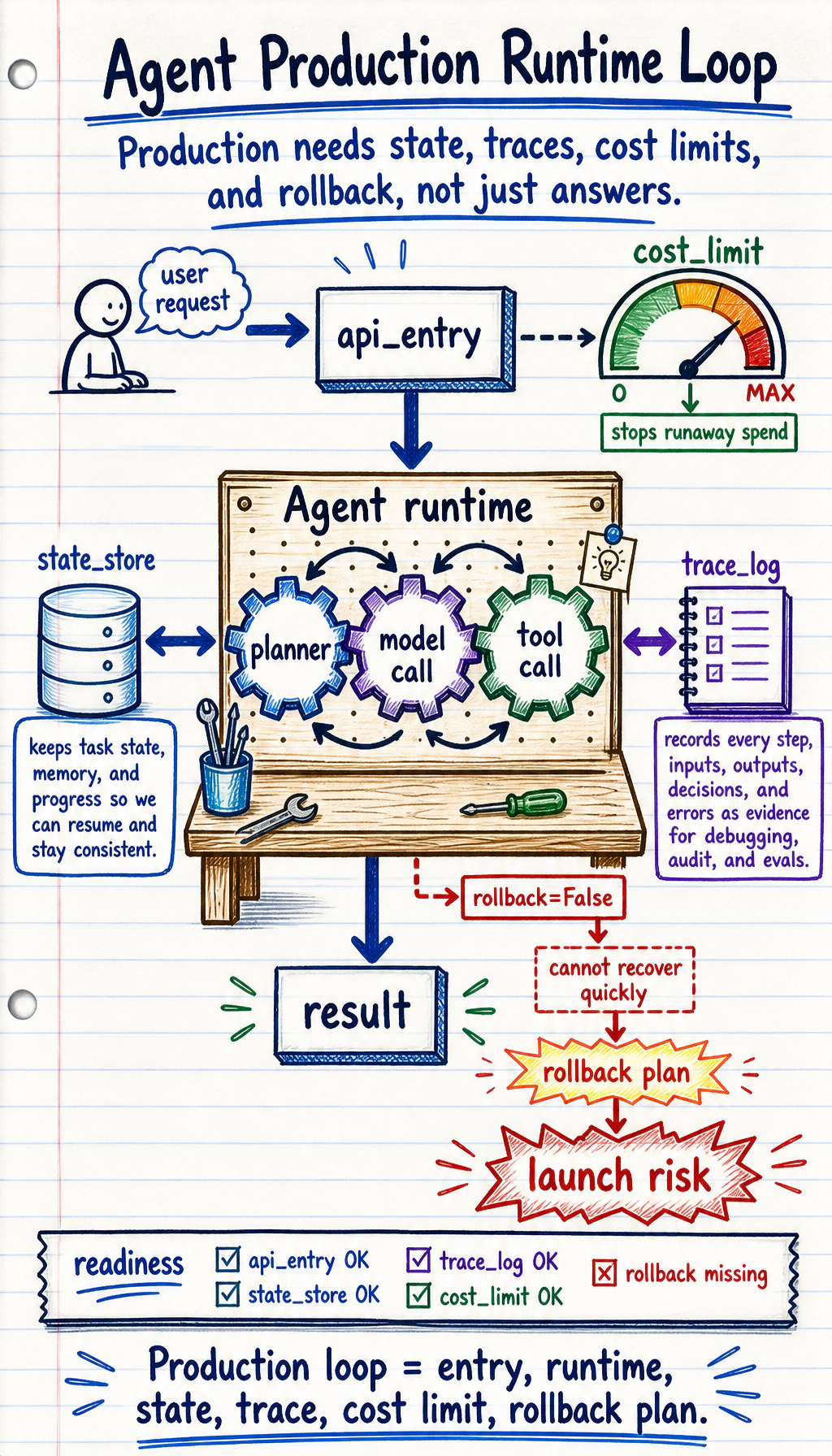

The production question is not “did it work once?” It is “can it keep working, fail safely, and recover?”
Run a Deployment Readiness Check
Section titled “Run a Deployment Readiness Check”This check highlights missing production basics.
service = { "api_entry": True, "state_store": True, "trace_log": True, "cost_limit": True, "rollback": False,}
missing = [name for name, ok in service.items() if not ok]
print("ready:", not missing)print("missing:", missing)Expected output:
ready: Falsemissing: ['rollback']If the system cannot roll back or recover, do not call it production-ready.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | Deployment architecture | Draw frontend, backend, model service, tool service, storage |
| 2 | Runtime management | Handle sync, async, long-running tasks, queues, interruption |
| 3 | Persistence and recovery | Save task state, memory, traces, intermediate results |
| 4 | Cost optimization | Track model calls, tool calls, caching, batching, routing |
| 5 | Production practices | Add monitoring, alerts, canary release, rollback, permissions |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Runtime
- queues, workers, state store, tool services, and model endpoint
- Persistence
- checkpoints, event log, memory store, and recovery path
- Ops Signal
- latency, cost, error rate, trace coverage, and saturation
- Failure Check
- stuck run, duplicate action, partial failure, or runaway cost
- Recovery Action
- resume, rollback, cancel, human handoff, or degrade gracefully
Pass Check
Section titled “Pass Check”You pass this chapter when a local Agent demo becomes a small service with API entry, state persistence, trace logs, error responses, cost records, and deployment instructions.
Check reasoning and explanation
- A passing answer describes the agent loop: goal, plan, tool call, observation, memory or state update, and stop condition.
- The evidence should include a trace that another developer can inspect, not only the final answer.
- A good self-check names one safety or reliability control such as tool schemas, permission boundaries, retries, evaluation cases, or a human-review point.