12.4.4 AI Regulations and Compliance
Learning Objectives
Section titled “Learning Objectives”- Understand why AI compliance issues directly affect product design
- Understand why keywords such as risk classification, auditing, and traceability matter
- Learn how to translate regulatory requirements into system requirements
- Build the perspective that “regulatory issues are not handled by legal alone; engineering must also participate in the design”
First, Build a Map
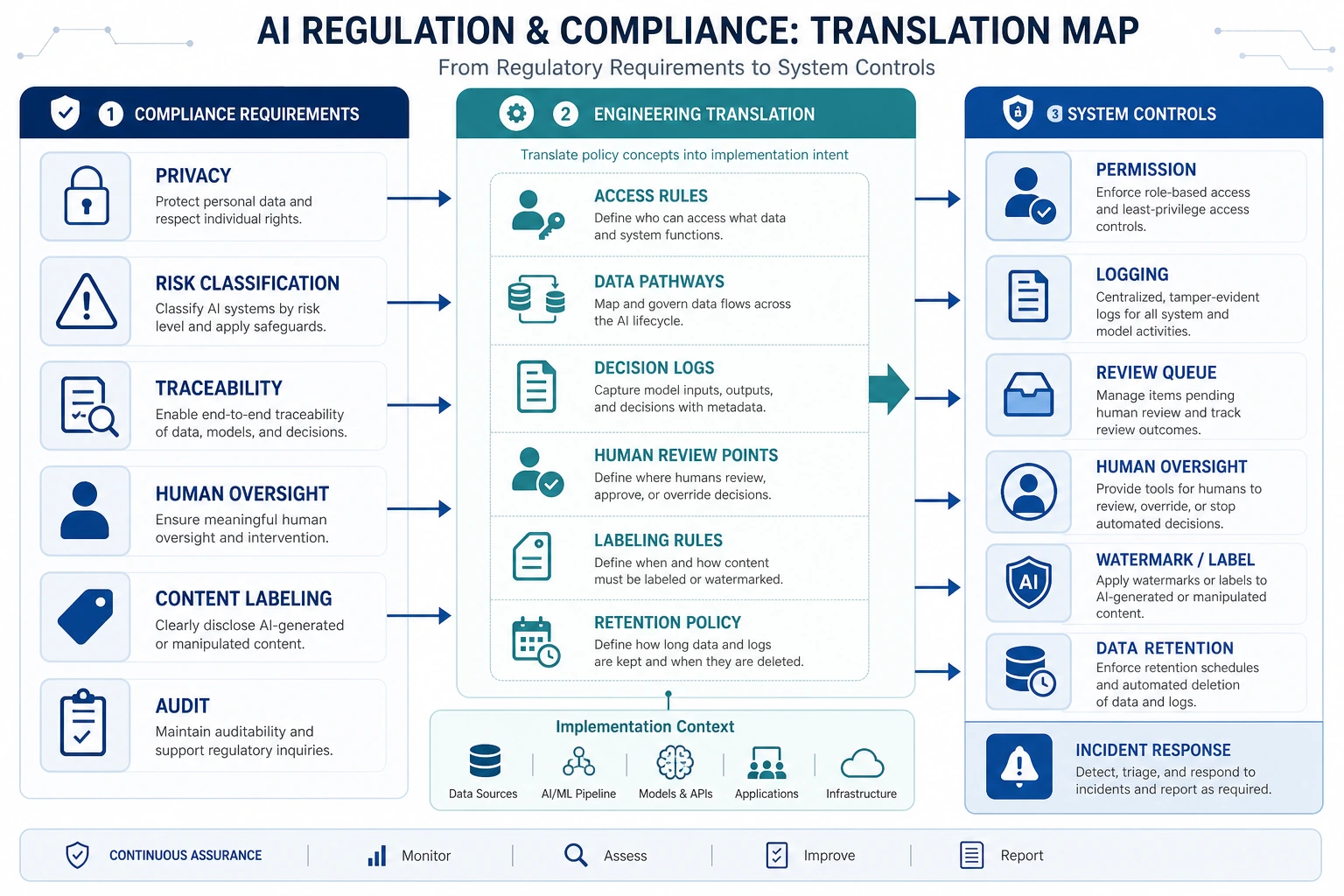
Section titled “First, Build a Map”AI regulations and compliance are easier to understand as “legal requirements -> system capabilities -> engineering implementation”:
flowchart LR A["Regulatory and compliance requirements"] --> B["Risk classification / traceability / permissions / human confirmation"] B --> C["System design and process configuration"]So what this section is really trying to solve is:
- Why regulatory issues directly become part of system structure
- Why technical teams must participate in “compliance translation”
Why Are Regulatory Issues Not Far From Engineers?
Section titled “Why Are Regulatory Issues Not Far From Engineers?”A Common Misunderstanding
Section titled “A Common Misunderstanding”Many technical learners instinctively think:
- regulations are the legal team’s job
- models are the engineering team’s job
But in real projects, these two often meet directly.
Why Do They Meet?
Section titled “Why Do They Meet?”Because many regulatory requirements eventually become questions like these:
- Do you have logs?
- Can you trace the source?
- Do you have permission control?
- Can a human take over?
In other words:
Regulatory requirements often end up becoming system capability requirements.
So compliance is not a post-check; it is often an architecture input.
A Better Analogy for Beginners
Section titled “A Better Analogy for Beginners”You can think of compliance as:
- a set of “building codes” that must be satisfied before a product can go live
Building codes do not directly tell you how to place every brick, but they do specify:
- where fire exits must be kept clear
- where emergency exits must be installed
AI compliance is very similar:
- it does not directly write your code for you
- but it does constrain what shape your system must take
What Are the Most Common Compliance Concerns?
Section titled “What Are the Most Common Compliance Concerns?”Data and Privacy
Section titled “Data and Privacy”Does the system handle:
- personal information
- sensitive information
- internal enterprise data
Traceability
Section titled “Traceability”Can the system explain:
- where this answer came from
- which data was used
- what happened at each step
Risk Classification
Section titled “Risk Classification”Different systems have different risk levels. Not all generative systems need the same level of control.
Human Oversight and Appeal Mechanisms
Section titled “Human Oversight and Appeal Mechanisms”In high-risk scenarios, the system usually cannot be fully automated end to end.
A Very Practical Way to Translate Requirements into Engineering
Section titled “A Very Practical Way to Translate Requirements into Engineering”When translating regulatory requirements into system requirements, you can usually think about them like this:
| Regulatory / compliance issue | What it becomes in engineering |
|---|---|
| Data protection | Data masking, access control, minimal retention |
| Explainability / traceability | Logs, traces, source citations |
| Restrictions on high-risk decisions | Human confirmation, dual approval, refusing automatic execution |
| Audit capability | Operation records, version records, request traceability |
This table is very important because it turns “compliance” from an abstract term into an engineering problem you can act on.
A Beginner-Friendly Table to Remember First
Section titled “A Beginner-Friendly Table to Remember First”| Requirement | Engineering focus |
|---|---|
| Data protection | Masking, permissions, retention boundaries |
| Traceability | Logs, traces, source references |
| High-risk restrictions | Approval flow, human confirmation, refusing automatic execution |
| Audit | Version records, operation traces, replayable configuration |
This table is especially useful for beginners because it translates “regulatory vocabulary” back into engineering language.
Why Has “Traceability” Become Such a Frequent Term in AI Compliance?
Section titled “Why Has “Traceability” Become Such a Frequent Term in AI Compliance?”Because many AI system problems are not just “the output is wrong,” but rather:
- you do not know why it is wrong
- you do not know what data it used
- you do not know which module caused the issue
That is why compliance often places strong emphasis on:
- source citations
- task traces
- decision logs
You can think of it like this:
It is not enough for the system to run; you also need to be able to look back and find out what happened.
Why Is Risk Classification So Important for AI Systems?
Section titled “Why Is Risk Classification So Important for AI Systems?”Not all AI applications should be controlled with the same level of strictness.
For example:
- a poster generator
- a medical advice assistant
These two clearly do not carry the same level of risk.
So one core idea is:
Governance and compliance are usually tiered, not one-size-fits-all.
This affects:
- whether human confirmation is required
- whether automatic decisions are allowed
- whether stronger auditing is required
A Minimal Illustration of “Compliance Requirements -> System Configuration”
Section titled “A Minimal Illustration of “Compliance Requirements -> System Configuration””compliance_config = { "data_traceable": True, "human_override": True, "audit_log_enabled": True, "sensitive_action_requires_approval": True}
print(compliance_config)Expected output:
{'data_traceable': True, 'human_override': True, 'audit_log_enabled': True, 'sensitive_action_requires_approval': True}This is not legal advice; it is a translation exercise. Each True represents a system capability that engineers can implement, test, and audit.
Although this example is simple, it expresses a very important idea:
Compliance requirements often end up becoming system switches, policies, and workflows.
In AIGC / Agent Scenarios, Where Are Compliance Problems Most Likely to Appear?
Section titled “In AIGC / Agent Scenarios, Where Are Compliance Problems Most Likely to Appear?”Retrieval and Knowledge Bases
Section titled “Retrieval and Knowledge Bases”If the system looks up internal documents, then it will definitely involve:
- permission boundaries
- source scope
Tool Calls
Section titled “Tool Calls”If the system can:
- send emails
- modify databases
- call enterprise systems
then the risk of automatic execution will appear quickly.
Generated Content
Section titled “Generated Content”If the system can generate:
- user-facing advice
- marketing copy
- contract drafts
then content responsibility and misinformation risk will rise.
Why Is “Human in the Loop” Becoming More and More Important?
Section titled “Why Is “Human in the Loop” Becoming More and More Important?”Because in many scenarios, what regulations and compliance care about most is not:
- whether the model can produce output
but rather:
- whether a human still has control over the final critical action
For example:
- high-risk approvals
- official external releases
- decisions involving legal and financial matters
This means:
Many system designs need to leave room for “human takeover points.”
This is both a compliance requirement and an engineering requirement.
A Beginner-Friendly Tiering Idea
Section titled “A Beginner-Friendly Tiering Idea”You can first think of systems in three categories:
- Low risk: more automation
- Medium risk: stronger logs and auditing
- High risk: human confirmation and takeover points are retained
This tiering idea is important because it helps you avoid one-size-fits-all governance.
A Very Important Engineering Habit
Section titled “A Very Important Engineering Habit”If you are building a high-risk AI application, it is recommended that you develop this way of thinking:
- First ask what risk level the system belongs to
- Then ask what logs and tracing are needed
- Then ask which actions must be confirmed by a human
- Finally, think about how the model and workflow should be implemented
This is much more reliable than “building the system first and adding compliance later.”
If You Turn This Into a System Design or Governance Document, What Is Most Worth Showing?
Section titled “If You Turn This Into a System Design or Governance Document, What Is Most Worth Showing?”What is most worth showing is usually not:
- “We are compliant”
but rather:
- How the risk level is classified
- Which capabilities were added to meet compliance requirements
- Which actions require human confirmation
- Which logs and traces can support auditing
This makes it easier for others to see:
- that you understand the translation process from compliance to engineering
- not just the policy layer
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Risk Scope
- frontier capability, ethics issue, regulation, or product policy boundary
- Engineering Rule
- what must be logged, blocked, reviewed, disclosed, or escalated
- Test Case
- one realistic input/output case that exercises the rule
- Failure Check
- privacy, copyright, portrait, bias, safety, provenance, or compliance gap
- Expected Output
- review checklist or product requirement translated into engineering action
Summary
Section titled “Summary”The most important thing in this section is not memorizing legal text, but understanding:
The parts of AI regulations and compliance that truly land on the technical side are usually data boundaries, log tracing, access control, and human confirmation mechanisms.
Once you start looking at the problem this way, compliance is no longer “a term far away from engineering,” but a layer you must actively consider when designing systems.
Exercises
Section titled “Exercises”- Pick an AI system you are familiar with and try to list its requirements in the four areas of “data, logs, permissions, and human confirmation.”
- Think about why “traceability” has become a core term in many AI compliance discussions.
- Explain in your own words why risk classification directly affects system design.
- Try translating “compliance” into three specific technical requirements that you can implement in a system.
Reference implementation and walkthrough
- A practical requirement list might include documented training or input data sources, immutable audit logs, role-based permissions, and human confirmation before high-risk actions or external publication.
- Traceability matters because teams need to reconstruct what data, prompt, model version, user action, and approval produced an output. Without that trail, debugging and accountability are weak.
- Risk classification changes the system because low-risk features may need lightweight disclosure, while high-risk features may need stricter logging, access control, review, fallback, and human approval.
- Three implementable requirements are: keep prompt/model/version logs, enforce permission checks on sensitive operations, and require manual approval for risky generated outputs before release.