11.6.1 Pretrained Models Roadmap: BERT, GPT, T5
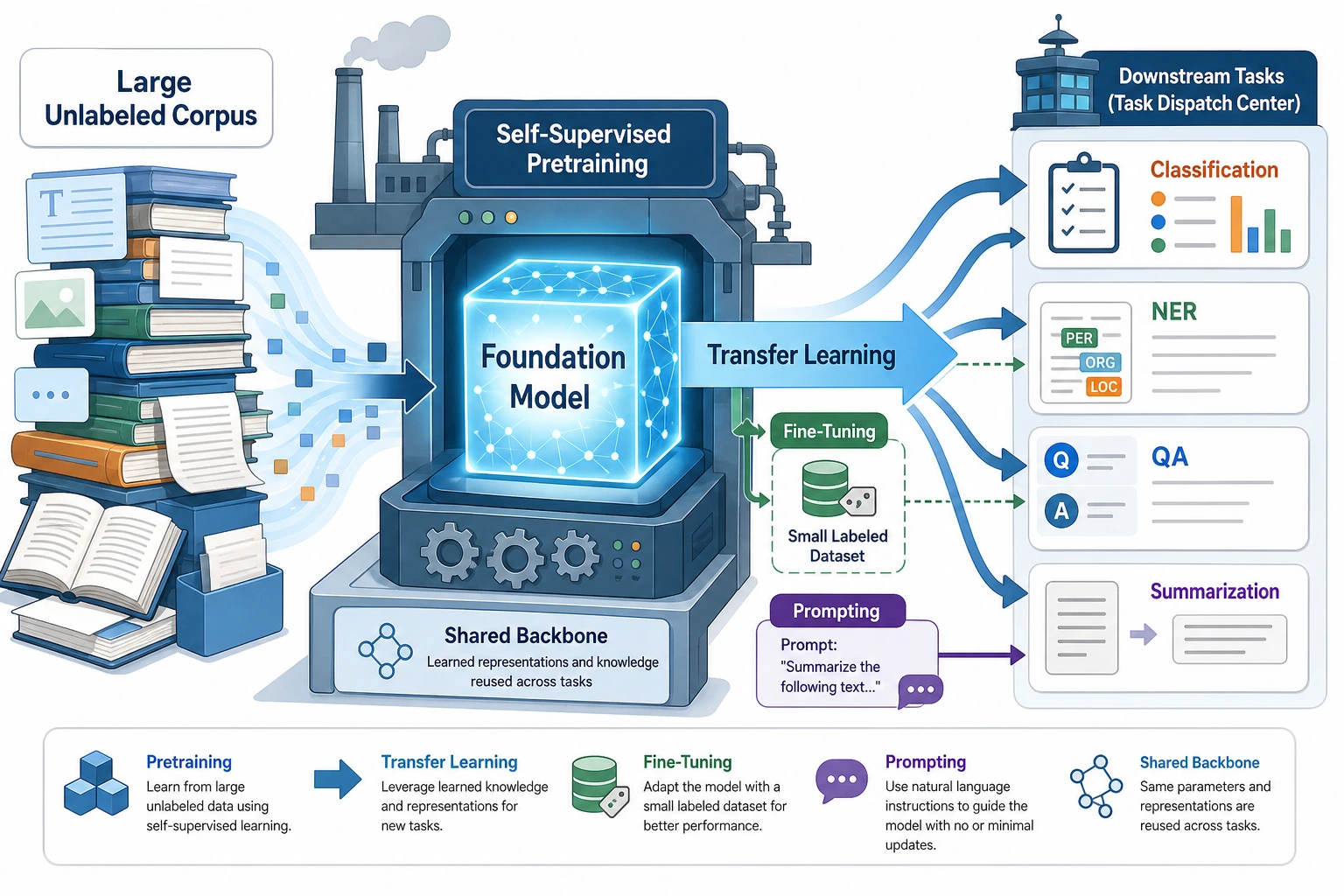
Pretrained models move NLP from one-task training to a reusable foundation: pretrain on large text, then transfer to downstream tasks.
See the Paradigm Map First
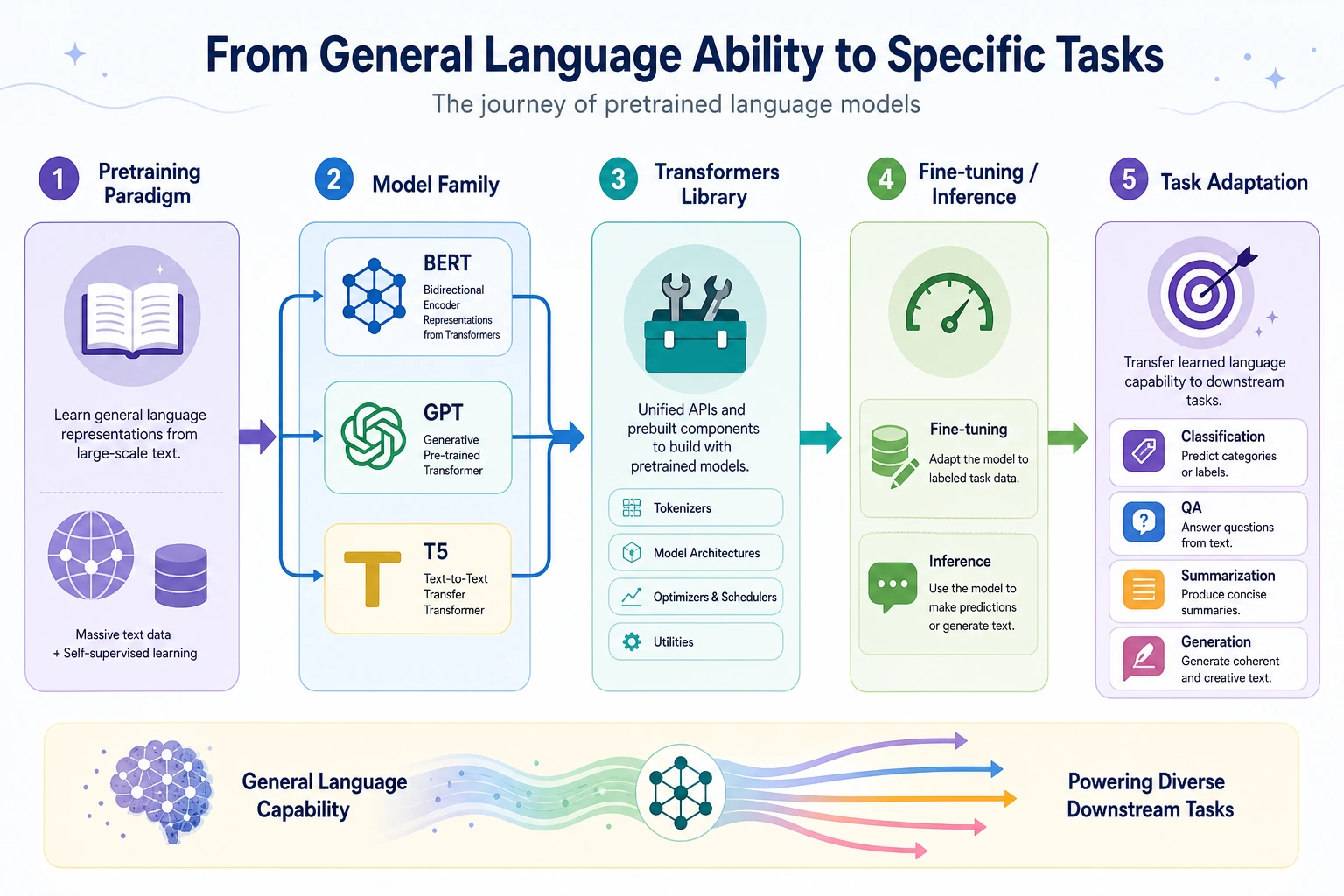
Section titled “See the Paradigm Map First”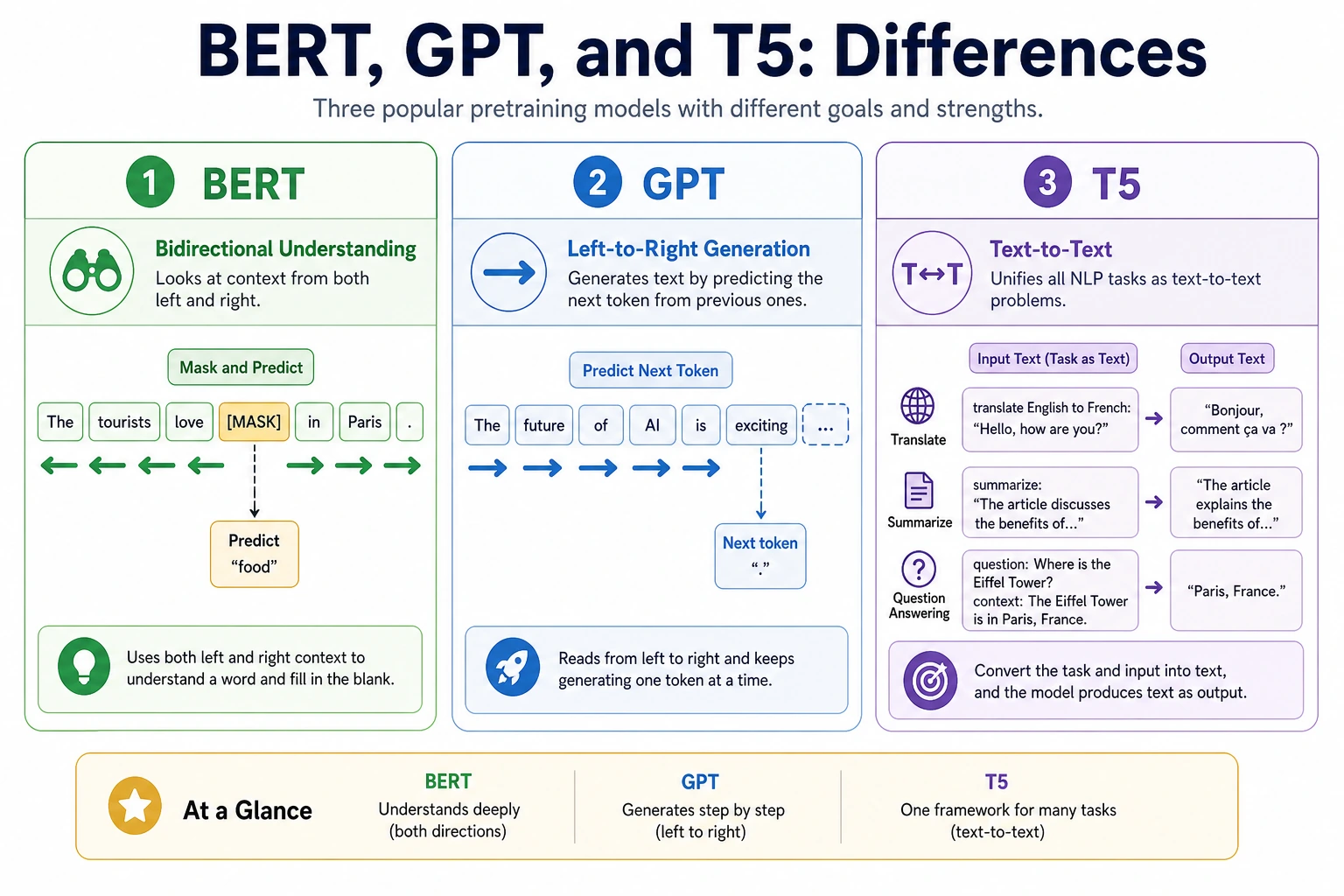
BERT emphasizes understanding, GPT emphasizes generation, and T5 rewrites many tasks into text-to-text form.
Run a Model Family Choice Check
Section titled “Run a Model Family Choice Check”task = { "needs_generation": True, "needs_sentence_label": False, "needs_text_to_text": True,}
if task["needs_text_to_text"]: family = "T5-style text-to-text"elif task["needs_generation"]: family = "GPT-style autoregressive"else: family = "BERT-style understanding"
print("family:", family)print("reason:", "match model objective to task output")Expected output:
family: T5-style text-to-textreason: match model objective to task outputDo not choose by model name alone. Match tokenizer, objective, output format, cost, and deployment constraints.
Learn in This Order
Section titled “Learn in This Order”| Step | Read | Practice Output |
|---|---|---|
| 1 | Pretraining paradigm | Explain pretrain → transfer → fine-tune/infer |
| 2 | BERT | Understand mask prediction and bidirectional representations |
| 3 | GPT | Understand next-token generation and context window |
| 4 | T5 | Rewrite tasks into text-to-text form |
| 5 | Transformers practice | Connect tokenizer, model, pipeline, input, output |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Model Choice
- BERT, GPT, T5, Transformers pipeline, or other pretrained baseline
- Tokenizer Output
- ids, masks, decoded text, or batch shape
- Task Result
- classification, generation, extraction, or text-to-text output
- Failure Check
- wrong model family, token limit, domain mismatch, cost, or latency
- Expected Output
- model call result plus a short choice rationale
Pass Check
Section titled “Pass Check”You pass this chapter when you can explain why different objectives create different strengths, and run or design one small pretrained-model comparison experiment.
Check reasoning and explanation
- A passing answer starts from the text unit and output type: token, span, sentence label, sequence, embedding, or generated text.
- The evidence should include a small dataset example, model or pipeline choice, metric, and at least one inspected error case.
- A good self-check distinguishes preprocessing issues from model issues, such as tokenization mistakes, label ambiguity, data imbalance, or hallucinated generation.