7.4.1 Pretraining Roadmap: Data, Objective, Engineering
Pretraining is how a model first learns broad language patterns. The useful engineering view is: clean data, choose an objective, train at scale, track risk.
Look at the Pretraining Triangle First
Section titled “Look at the Pretraining Triangle First”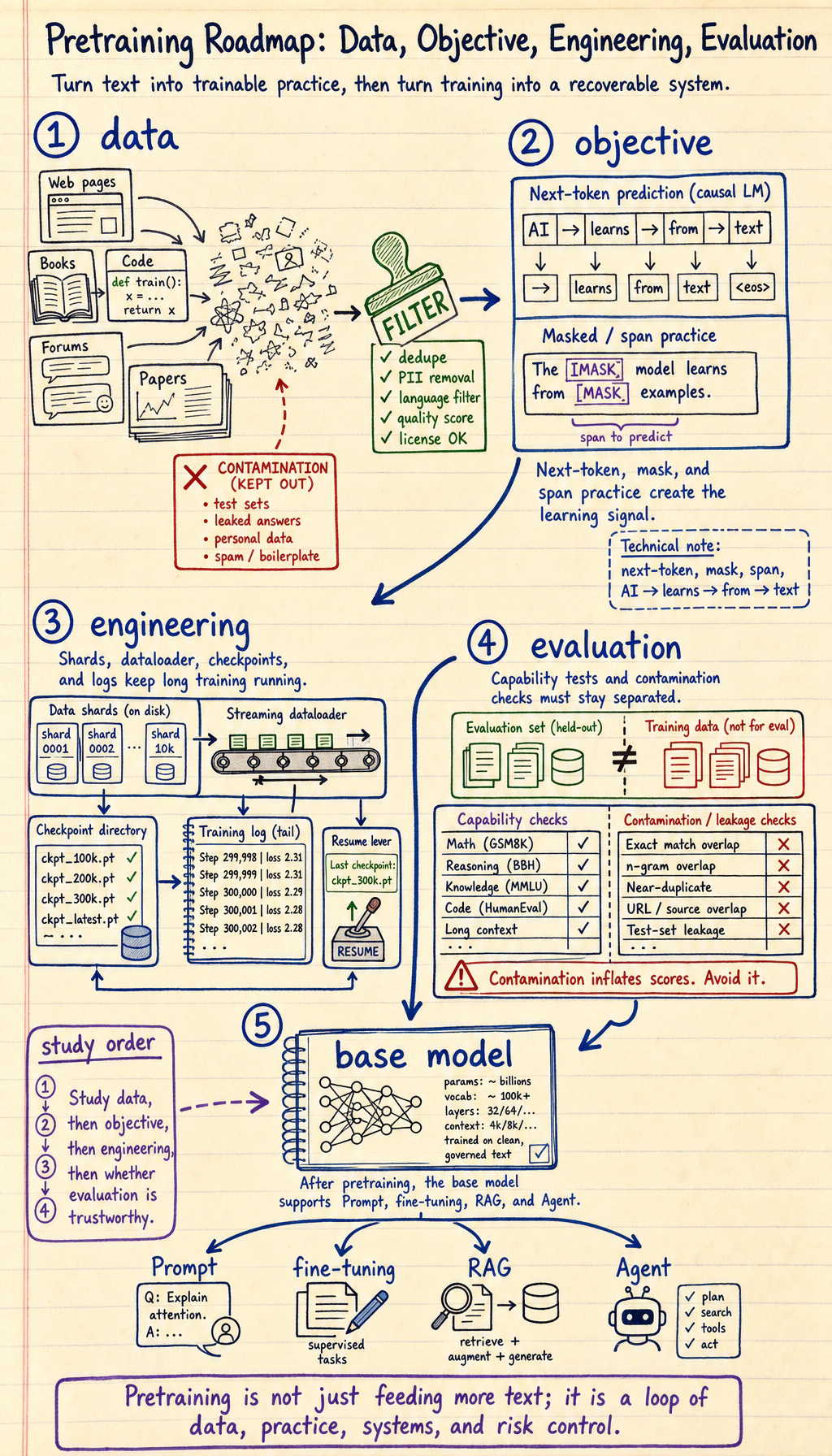
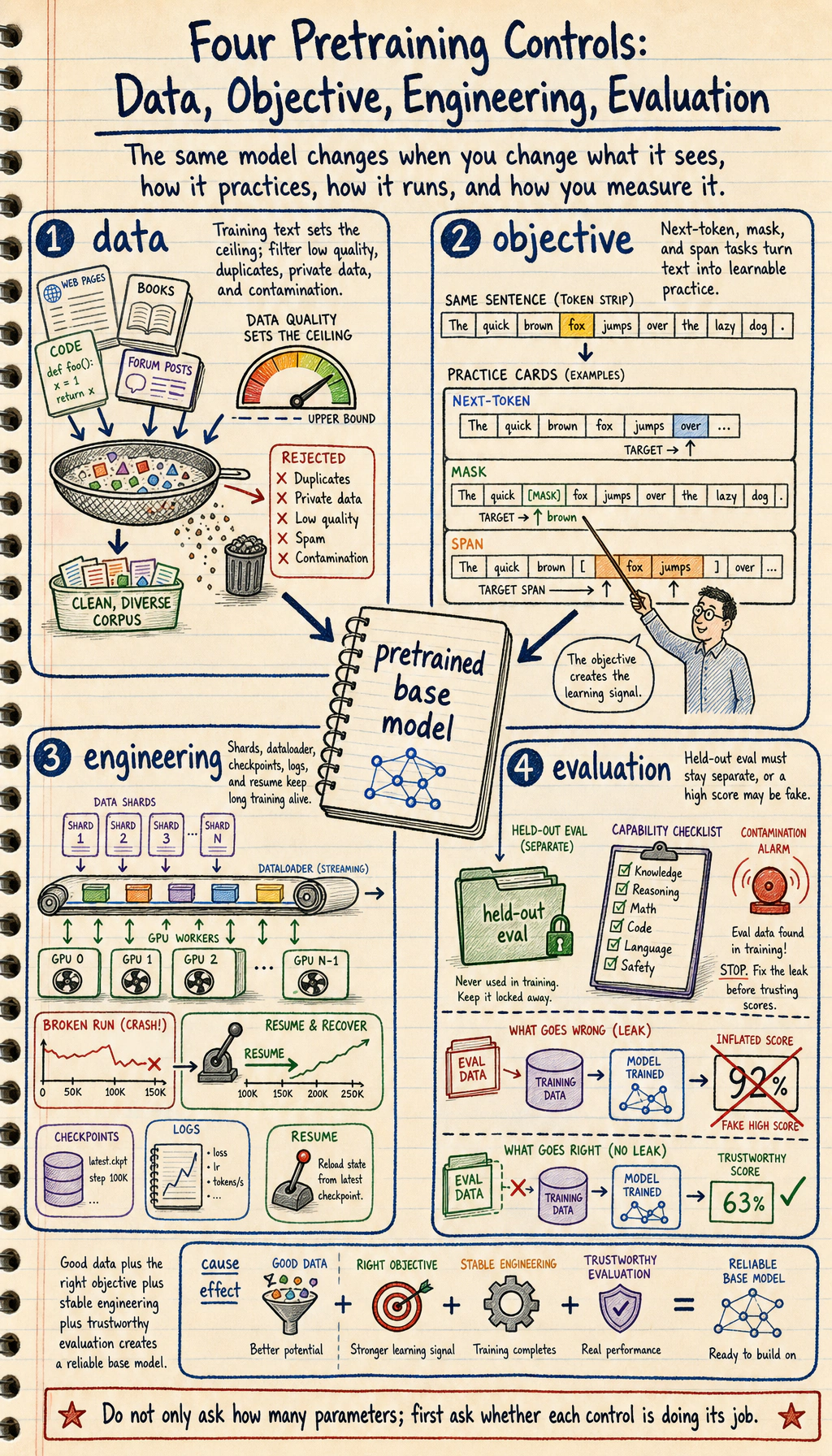
| Piece | First question |
|---|---|
| data | what text enters training and what must be filtered? |
| objective | what prediction task creates learning signal? |
| engineering | how are scale, checkpoints, logs, and failures handled? |
| evaluation | what can the model do, and where does it fail? |
Create Next-Token Pairs
Section titled “Create Next-Token Pairs”tokens = ["AI", "learns", "from", "text"]pairs = list(zip(tokens[:-1], tokens[1:]))
for source, target in pairs: print(f"{source} -> {target}")Expected output:
AI -> learnslearns -> fromfrom -> text
This tiny example is the shape of next-token prediction. Real pretraining repeats this over massive text with careful data governance.
Learn in This Order
Section titled “Learn in This Order”| Order | Read | What to focus on |
|---|---|---|
| 1 | 7.4.2 Pretraining Data | sources, filtering, deduplication, contamination |
| 2 | 7.4.3 Pretraining Methods | next-token prediction, loss, scaling |
| 3 | 7.4.4 Pretraining Engineering | distributed training, checkpoints, monitoring |
| 4 | 7.4.5 Rent a GPU and Train a Hand-Built GPT-2 | platform choice, environment setup, device: cuda mini GPT-2 walkthrough |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Triangle
- data, objective, and engineering all matter
- Sample Pairs
- next-token training pairs from one sentence
- Data Risk
- contamination, duplication, or low-quality mixture
- Objective Note
- objective shapes behavior and architecture fit
- Engineering Note
- sharding, resume, throughput, and monitoring
- Hands On Bridge
- run a mini GPT-2 training script on free or low-cost GPU compute
Pass Check
Section titled “Pass Check”You pass this roadmap when you can explain how data, objective, and engineering each affect the final model, why contamination can make evaluation misleading, and why the mini GPT-2 lab treats CPU as smoke testing while device: cuda is the official training evidence.
Check reasoning and explanation
- A passing answer explains how tokens, context, attention, prompts, and generation behavior connect in one request-response path.
- The evidence should include at least one reproducible prompt or structured-output test, plus notes on why the output passed or failed.
- A good self-check separates prompt design, RAG, fine-tuning, and alignment: use the lightest method that fixes the observed problem.