7.6.6 Data Labeling and the Data Flywheel
Learning Objectives
Section titled “Learning Objectives”- Understand that labeling is not just “assigning tags,” but defining task boundaries
- Know how to design label systems, labeling guidelines, and quality-check processes
- Learn to use agreement metrics and hard example selection to check data quality
- Understand how the data flywheel turns failed online samples into the next round of training assets
Why is “data labeling” essentially task definition?
Section titled “Why is “data labeling” essentially task definition?”Labels are not clerical work, but product decisions
Section titled “Labels are not clerical work, but product decisions”Suppose your task is “customer service reply quality classification.”
If you only give annotators a label name:
- Good reply
- Bad reply
then everyone will interpret the standard differently:
- Some people judge politeness
- Some judge whether the issue is solved
- Some judge whether it follows policy
In the end, the model will learn a mixture of standards.
So the labels should really answer:
- What counts as correct
- What counts as wrong
- How to judge edge cases
Analogy: the model is not learning label names, but the rules behind them
Section titled “Analogy: the model is not learning label names, but the rules behind them”You can think of each labeled data point as:
- A case judged by humans
What the model sees is not the words “safe/unsafe,” but the judgment criteria you implicitly express through many examples.
So if the rules themselves are vague, the model cannot learn them clearly.
Why do many fine-tuning projects get stuck here?
Section titled “Why do many fine-tuning projects get stuck here?”Because teams often overestimate how clear the “label names” are, and underestimate the importance of the “labeling guidelines.”
What really improves data quality in a stable way is often not the labeling platform, but:
- Label definitions
- Positive and negative examples
- Boundary examples
- Review mechanisms
First, design the label system clearly
Section titled “First, design the label system clearly”Labels should map naturally to business actions
Section titled “Labels should map naturally to business actions”A good label system should map cleanly to downstream actions.
For example, in a customer service review task, instead of simply dividing into:
- Good
- Bad
more practical labels might be:
correct_and_politecorrect_but_too_briefpolicy_violationhallucinated_promise
Because these labels are more useful for:
- Error analysis
- Data augmentation
- Targeted fine-tuning
Boundary cases must have their own rules
Section titled “Boundary cases must have their own rules”What beginners most easily overlook is that:
- Clear positive cases
- Clear negative cases
are usually not hard to label.
The truly difficult cases are:
- Partially correct
- Polite in tone but factually wrong
- The refusal direction is right, but the wording is harsh
If these boundary cases are not clearly defined, consistency will definitely drop.
When should you use classification labels, and when should you use preference comparison?
Section titled “When should you use classification labels, and when should you use preference comparison?”If your task focuses on:
- Clear categories
- Whether something violates a rule
classification labels are usually more natural.
If your task focuses on:
- Which of two answers is better
- Which style better matches the expectation
preference comparison is often more stable.
In other words:
- Classification is better for “absolute standards”
- Preference is better for “relative quality”
Start with a truly useful data quality check script
Section titled “Start with a truly useful data quality check script”The code below does three very practical things:
- Computes agreement rate between two annotators
- Computes Cohen’s kappa
- Finds samples that should go into the next round of review or relabeling
from collections import Counter
records = [ { "id": 1, "text": "You can reset the password first, then try logging in again.", "label_a": "good", "label_b": "good", "model_confidence": 0.93, }, { "id": 2, "text": "Go check it yourself.", "label_a": "bad", "label_b": "bad", "model_confidence": 0.91, }, { "id": 3, "text": "Even if it has already been shipped, it can definitely be refunded instantly.", "label_a": "bad", "label_b": "good", "model_confidence": 0.52, }, { "id": 4, "text": "After the order is completed, you can apply for an invoice in the invoice center.", "label_a": "good", "label_b": "good", "model_confidence": 0.51, }, { "id": 5, "text": "I'm not sure whether changing the address is supported. Please contact human support to confirm.", "label_a": "good", "label_b": "bad", "model_confidence": 0.47, },]
def agreement_rate(labels_a, labels_b): matches = sum(a == b for a, b in zip(labels_a, labels_b)) return matches / len(labels_a)
def cohens_kappa(labels_a, labels_b): n = len(labels_a) observed = agreement_rate(labels_a, labels_b)
counter_a = Counter(labels_a) counter_b = Counter(labels_b) all_labels = sorted(set(labels_a) | set(labels_b)) expected = sum( (counter_a[label] / n) * (counter_b[label] / n) for label in all_labels )
if expected == 1: return 1.0 return (observed - expected) / (1 - expected)
labels_a = [row["label_a"] for row in records]labels_b = [row["label_b"] for row in records]
print("agreement =", round(agreement_rate(labels_a, labels_b), 3))print("kappa =", round(cohens_kappa(labels_a, labels_b), 3))
needs_review = [ row for row in records if row["label_a"] != row["label_b"] or row["model_confidence"] < 0.6]
needs_review = sorted(needs_review, key=lambda row: row["model_confidence"])print("\nreview queue:")for row in needs_review: print( f"id={row['id']} confidence={row['model_confidence']:.2f} " f"labels=({row['label_a']}, {row['label_b']}) text={row['text']}" )Expected output:
agreement = 0.6kappa = 0.167
review queue:id=5 confidence=0.47 labels=(good, bad) text=I'm not sure whether changing the address is supported. Please contact human support to confirm.id=4 confidence=0.51 labels=(good, good) text=After the order is completed, you can apply for an invoice in the invoice center.id=3 confidence=0.52 labels=(bad, good) text=Even if it has already been shipped, it can definitely be refunded instantly.Why is this code not a “useless example”?
Section titled “Why is this code not a “useless example”?”Because it corresponds to three things data teams do every day:
- Check whether annotators are consistent
- Check which samples the model is most uncertain about
- Pull out disputed samples for focused review
If you only look at “total sample size” and ignore these signals, data quality can easily stay at a superficial level.
Why is agreement not enough?
Section titled “Why is agreement not enough?”Because sometimes the classes are highly imbalanced.
For example, if 90% of samples are good,
then even two lazy annotators can get a seemingly high agreement rate.
That is why many teams also look at:
- Cohen’s kappa
It tries to subtract the part that may have matched by chance.
Why should low-confidence samples go into the review queue?
Section titled “Why should low-confidence samples go into the review queue?”Because such samples often mean:
- The model is unsure
- The rule boundaries are blurry
- Or the sample itself is noisy
They are exactly where the next round of data gains is greatest.
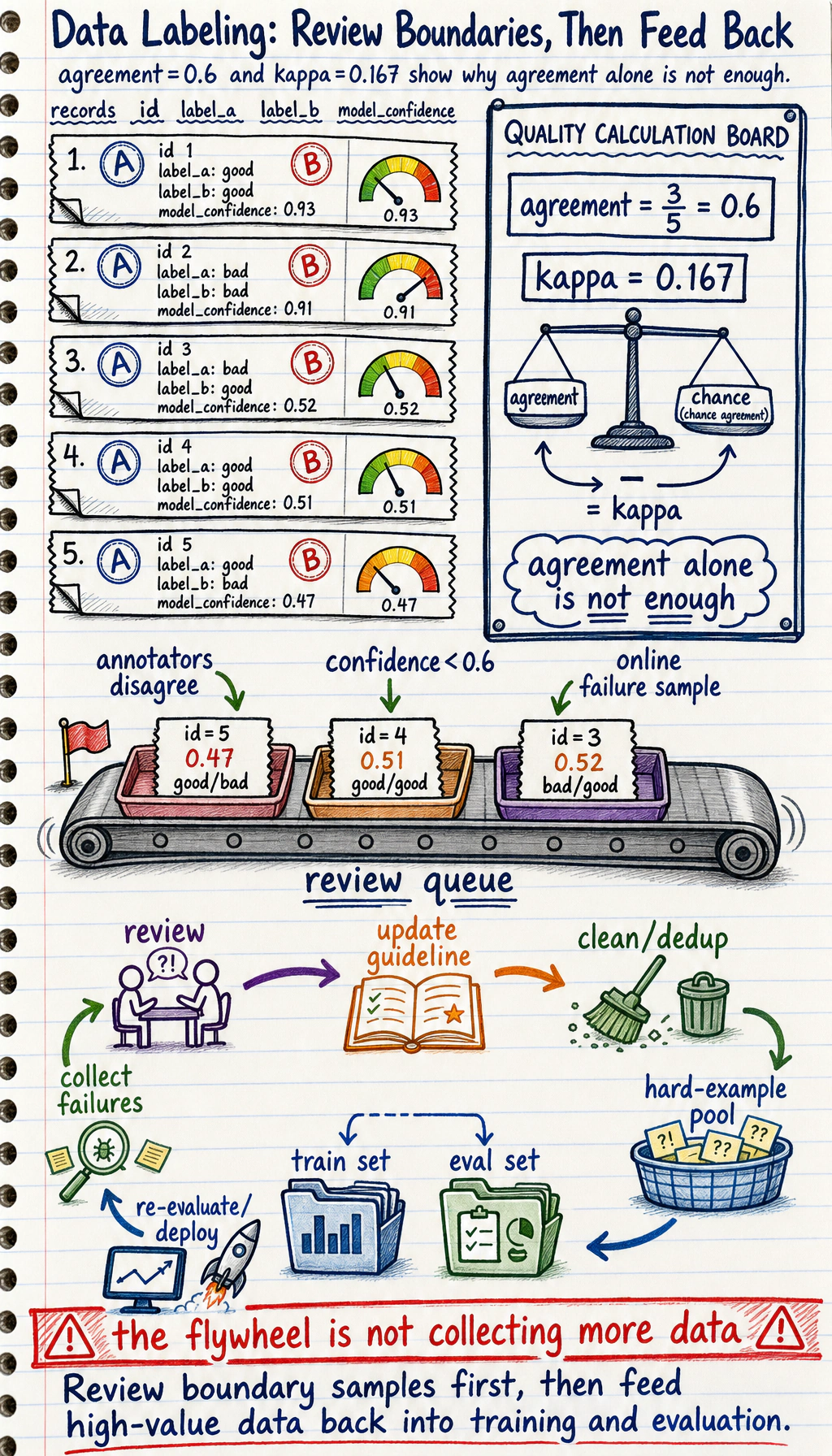
What is the “data flywheel”?
Section titled “What is the “data flywheel”?”What does the smallest loop look like?
Section titled “What does the smallest loop look like?”A typical data flywheel usually looks like this:
- Deploy the model
- Collect failed samples
- Clean and deduplicate
- Relabel or add labels
- Add them to the next training set
- Evaluate again, then deploy again
The key point of the flywheel is not the word “loop,” but that the data coming back each round is closer to the real problem.
Why are failed online samples especially valuable?
Section titled “Why are failed online samples especially valuable?”Because they usually have two characteristics:
- They come from real users
- They hit the system’s weakest points exactly
Compared with manually invented samples, this kind of data is much more targeted.
What does the flywheel fear most?
Section titled “What does the flywheel fear most?”It fears three things the most:
- Failed samples cannot be collected
- Once collected, no one categorizes the causes
- After categorization, they are not used in the next round of training or evaluation
If you only collect data but do not feed it back, that is not a flywheel — it is just accumulation.
How do we make the flywheel more stable?
Section titled “How do we make the flywheel more stable?”First, bucket the failure types
Section titled “First, bucket the failure types”Dividing online issues into categories is often more effective than simply piling up samples.
For example:
- Format errors
- Hallucinations
- Policy violations
- Over-refusal
- Missing key fields
Then in the next round, you know exactly which type of data to add.
Then deduplicate and sample representatively
Section titled “Then deduplicate and sample representatively”Real online data is often repetitive. If users repeatedly ask the same kind of question, you should not mechanically dump all samples back into the training set.
A better approach is usually:
- Remove near-duplicates
- Keep representative samples
- Give higher priority to rare but high-risk issues
Don’t forget version control
Section titled “Don’t forget version control”Each round of data should clearly record:
- Where it came from
- Why it was added
- Which error category it belongs to
- Whether it has been manually reviewed
Otherwise, later on it will be very hard to answer:
Was this improvement due to a method change, or because the data changed?
How detailed should labeling guidelines be?
Section titled “How detailed should labeling guidelines be?”At minimum, include positive examples, negative examples, and boundary examples
Section titled “At minimum, include positive examples, negative examples, and boundary examples”A good guideline usually includes at least:
- Label definition
- Applicability conditions
- Clear positive examples
- Clear negative examples
- Confusing boundary examples
It should preferably answer “why”
Section titled “It should preferably answer “why””If the guideline only says:
- In this case, assign
bad
but does not explain why, annotators will hesitate when they encounter similar but not identical cases.
The guidelines themselves also need to evolve
Section titled “The guidelines themselves also need to evolve”As the project progresses, you will keep discovering:
- New scenarios not covered by old rules
- Labels that are too coarse
- Two labels that are easy to confuse
At that point, what needs updating is not just the data, but the guidelines themselves.
These mistakes are especially easy to make
Section titled “These mistakes are especially easy to make”Mistake 1: Label a lot first, talk about rules later
Section titled “Mistake 1: Label a lot first, talk about rules later”If the rules are not clearly defined before large-scale labeling, the rework burden is usually enormous.
Mistake 2: Only focus on agreement rate, not on the reasons for disagreement
Section titled “Mistake 2: Only focus on agreement rate, not on the reasons for disagreement”Low agreement is just a symptom. What matters more is knowing whether:
- The guidelines are unclear
- The samples are too noisy
- Or the label system itself is unreasonable
Mistake 3: Thinking of the flywheel as “just adding more data all the time”
Section titled “Mistake 3: Thinking of the flywheel as “just adding more data all the time””The flywheel is not about blindly increasing volume, but about continuously turning the most valuable failed samples into high-quality training assets.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Label Rule
- task definition and allowed outputs
- Quality Check
- duplicate, conflict, empty, or vague label count
- Guideline
- one rule that resolves ambiguity
- Flywheel
- model failure → label fix → retrain/evaluate
- Risk
- bad labels teach bad behavior more efficiently
Summary
Section titled “Summary”The most important conclusion in this section is:
Data labeling is not a side task before fine-tuning; it is the core of task definition, quality control, and continuous iteration capability.
A truly vibrant data system usually has all three of these:
- Clear rules
- Strong quality control
- Reliable feedback of failed samples
When all three are in place, your model quality can improve continuously and in an explainable way.
Exercises
Section titled “Exercises”- Design 3 to 5 labels for a task you know well, and write positive and negative examples for each label.
- Refer to the code in this section and manually construct a set of two-annotator labeled data. Calculate the agreement rate and kappa.
- Think about which failed online samples in your project are most worth feeding back into the training set first.
- If two annotators keep disagreeing on the same type of sample, would you first revise the guidelines, revise the label system, or directly decide by vote? Why?
Project reference and review notes
- Good labels should be mutually distinguishable, useful for action, and illustrated with boundary cases. Positive and negative examples should make the decision rule visible, not just repeat the label name.
- Agreement rate shows raw consistency, while kappa adjusts for chance agreement. If agreement is low, the problem is often unclear instructions, overlapping labels, or ambiguous samples.
- Prioritize high-frequency failures, high-risk failures, and failures that represent a stable pattern. Rare one-off mistakes are usually less valuable than repeated failure modes that affect real users.
- First inspect whether the guideline or label system is ambiguous. Voting can resolve a single sample, but repeated disagreement means the task definition itself needs repair.