E.0 Elective Hands-on Workshop
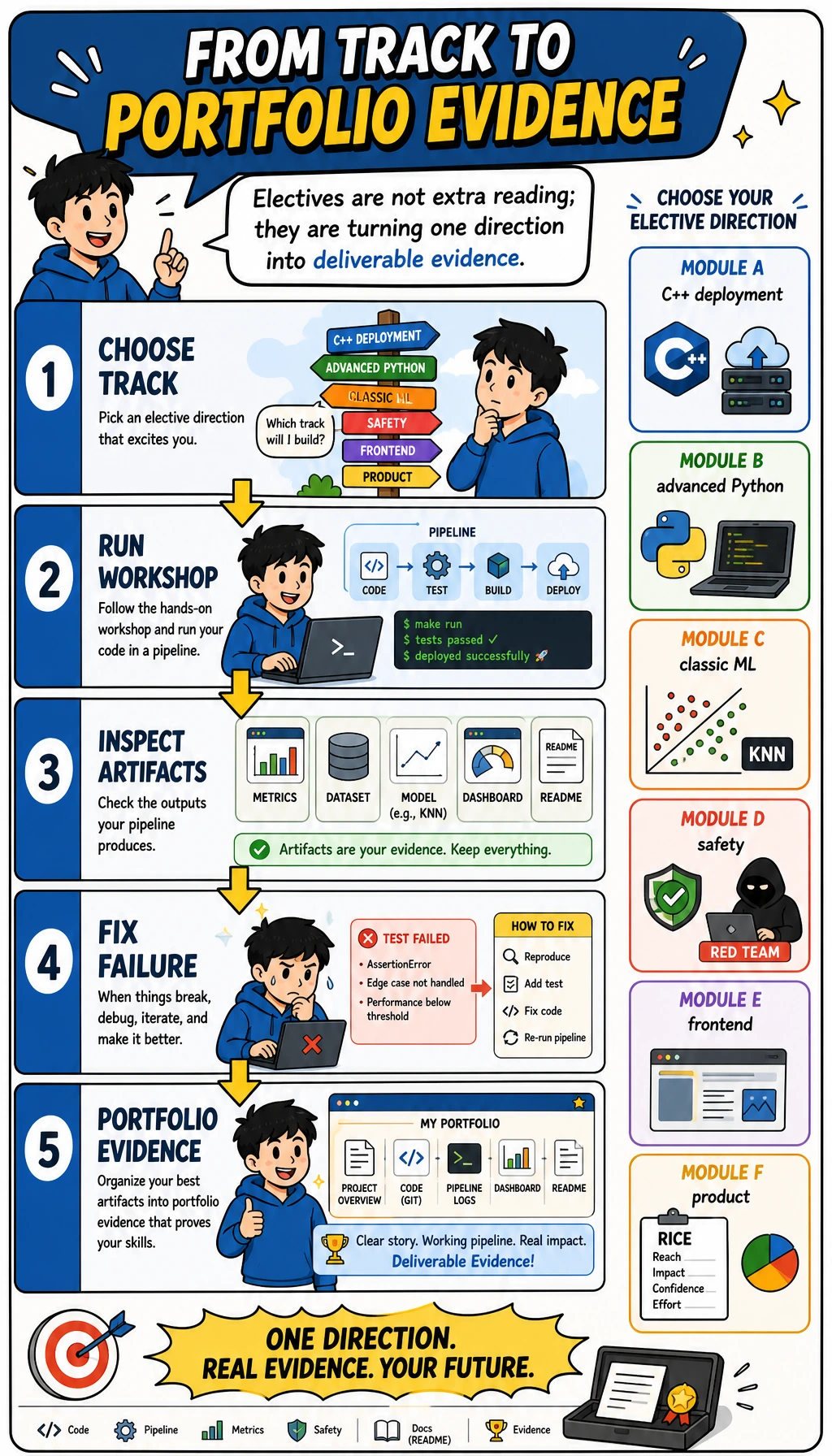
This workshop is the shortest way to feel what the electives are for. You will run one Python script and inspect the evidence files it creates.
What you will build
Section titled “What you will build”
The script creates this folder:
elective_workshop_run/ outputs/module_a_deployment_score.csv outputs/module_b_python_trace.json outputs/module_c_knn_predictions.csv outputs/module_d_red_team_report.md outputs/module_e_dashboard.html outputs/module_f_product_canvas.md reports/failure_cases.md reports/readiness_score.json README.mdEach file maps to one elective:
| Module | Skill | Evidence file |
|---|---|---|
| A | deployment trade-off | deployment score CSV |
| B | Python engineering trace | JSON trace |
| C | classic ML baseline | KNN prediction CSV |
| D | safety regression | red-team Markdown report |
| E | frontend evidence | static HTML dashboard |
| F | product judgment | product priority Markdown table |
Run the workshop
Section titled “Run the workshop”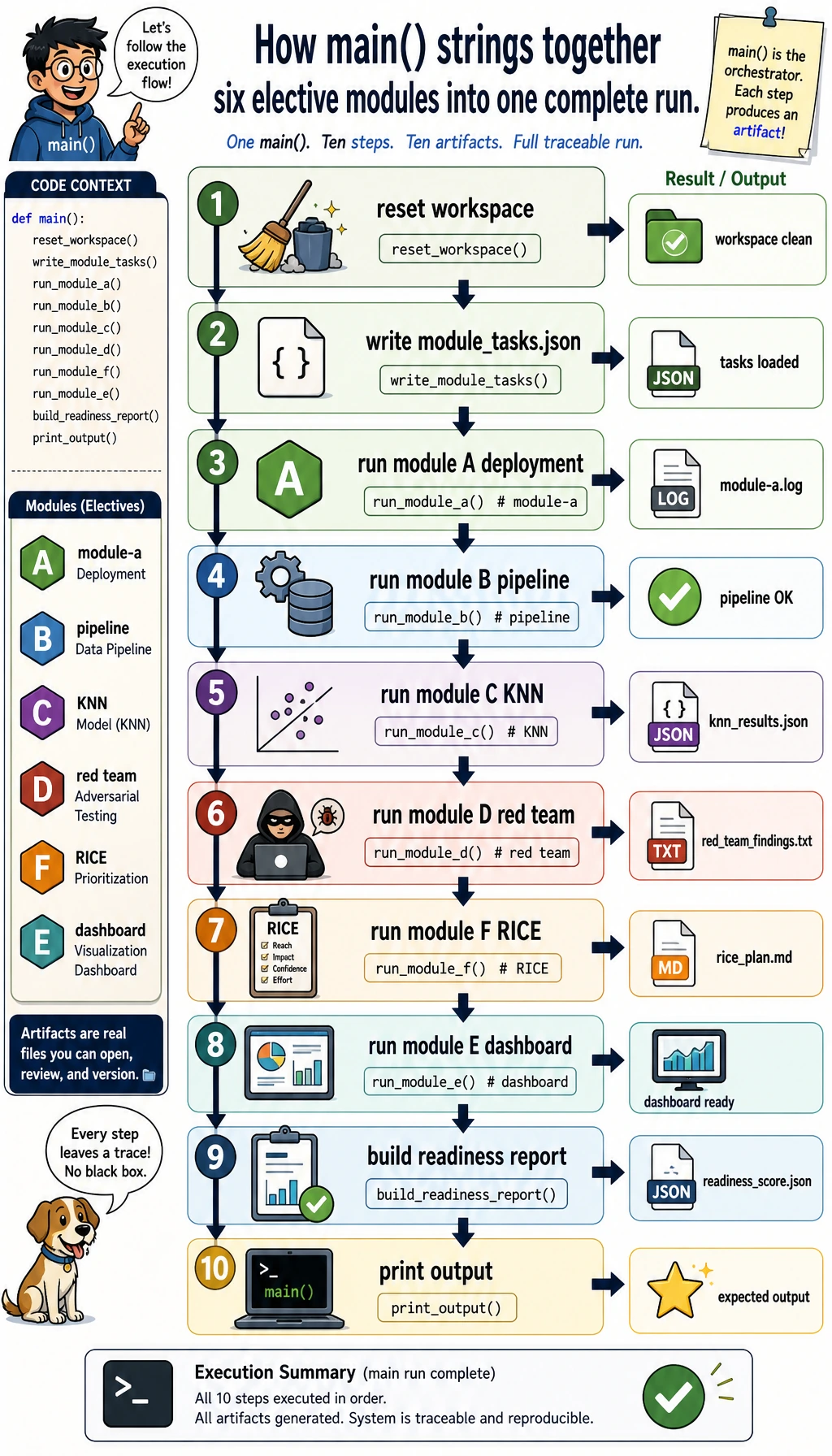
Create a clean folder:
mkdir elective-workshopcd elective-workshopCreate elective_workshop.py:
from pathlib import Pathimport csvimport htmlimport jsonimport mathimport shutil
RUN = Path("elective_workshop_run")OUT = RUN / "outputs"REPORTS = RUN / "reports"
def reset(): if RUN.exists(): shutil.rmtree(RUN) OUT.mkdir(parents=True) REPORTS.mkdir(parents=True)
def write_json(path, data): path.write_text(json.dumps(data, indent=2, ensure_ascii=False), encoding="utf-8")
def write_csv(path, rows): with path.open("w", newline="", encoding="utf-8") as f: writer = csv.DictWriter(f, fieldnames=list(rows[0])) writer.writeheader() writer.writerows(rows)
def write_md_table(path, headers, rows): lines = ["| " + " | ".join(headers) + " |", "|" + "|".join(["---"] * len(headers)) + "|"] lines += ["| " + " | ".join(map(str, row)) + " |" for row in rows] path.write_text("\n".join(lines) + "\n", encoding="utf-8")
def module_a_deployment(): rows = [ {"variant": "baseline-fp32", "latency_ms": 118, "memory_mb": 640, "accuracy": 0.912}, {"variant": "quantized-int8", "latency_ms": 54, "memory_mb": 310, "accuracy": 0.901}, {"variant": "distilled-small", "latency_ms": 43, "memory_mb": 220, "accuracy": 0.872}, ] for row in rows: latency_score = min(80 / row["latency_ms"], 1.2) * 35 memory_score = min(450 / row["memory_mb"], 1.2) * 20 accuracy_score = max(0, (row["accuracy"] - 0.89) / 0.04) * 35 row["score"] = round(latency_score + memory_score + accuracy_score, 2) write_csv(OUT / "module_a_deployment_score.csv", rows) return max(rows, key=lambda row: row["score"])
def module_b_python_trace(): raw = [" Slow edge demo ", "Retry API timeout", " dashboard missing links "] cleaned = [text.strip().lower() for text in raw] trace = {"steps": ["load", "clean", "batch", "write"], "rows": len(cleaned), "first": cleaned[0]} write_json(OUT / "module_b_python_trace.json", trace) return trace
def distance(a, b): return math.sqrt(sum((x - y) ** 2 for x, y in zip(a, b)))
def module_c_knn(): train = [([0.1, 0.2], "low"), ([0.8, 0.9], "high"), ([0.5, 0.45], "review")] tests = [([0.12, 0.18], "low"), ([0.82, 0.85], "high"), ([0.48, 0.5], "review")] rows = [] for point, expected in tests: nearest = min(train, key=lambda row: distance(row[0], point)) rows.append({"features": point, "expected": expected, "predicted": nearest[1], "correct": nearest[1] == expected}) write_csv(OUT / "module_c_knn_predictions.csv", rows) return {"accuracy": sum(row["correct"] for row in rows) / len(rows), "rows": rows}
def module_d_safety(): cases = [ ["prompt", "refuse", "refuse"], ["retrieval", "ignore_untrusted_instruction", "ignore_untrusted_instruction"], ["tool", "ask_confirmation", "executed"], ] rows, failures = [], [] for surface, expected, observed in cases: status = "PASS" if expected == observed else "FAIL" rows.append([surface, expected, observed, status]) if status == "FAIL": failures.append(surface) write_md_table(OUT / "module_d_red_team_report.md", ["surface", "expected", "observed", "status"], rows) (REPORTS / "failure_cases.md").write_text("\n".join(f"- {name}" for name in failures) + "\n", encoding="utf-8") return {"passed": len(cases) - len(failures), "total": len(cases), "failures": failures}
def module_f_product(): ideas = [ {"idea": "Deployment evidence checker", "reach": 7, "impact": 8, "confidence": 0.8, "effort": 3}, {"idea": "Async batch runner", "reach": 5, "impact": 7, "confidence": 0.65, "effort": 4}, {"idea": "Red-team regression gate", "reach": 6, "impact": 9, "confidence": 0.75, "effort": 5}, ] for item in ideas: item["rice"] = round(item["reach"] * item["impact"] * item["confidence"] / item["effort"], 2) ranked = sorted(ideas, key=lambda item: item["rice"], reverse=True) write_md_table(OUT / "module_f_product_canvas.md", list(ranked[0]), [item.values() for item in ranked]) return ranked[0]
def module_e_dashboard(summary): cards = "".join( f"<section><h2>{html.escape(k)}</h2><pre>{html.escape(json.dumps(v, ensure_ascii=False, indent=2))}</pre></section>" for k, v in summary.items() ) page = f"""<!doctype html><html lang='en'><meta charset='utf-8'><title>Elective Workshop</title><style>body{{font-family:system-ui,sans-serif;max-width:900px;margin:32px auto;background:#f8fafc}}section{{background:white;border:1px solid #ddd;border-radius:8px;padding:16px;margin:12px 0}}pre{{white-space:pre-wrap}}</style><h1>Elective Workshop Evidence</h1>{cards}</html>""" (OUT / "module_e_dashboard.html").write_text(page, encoding="utf-8") return {"cards": len(summary)}
def main(): reset() summary = { "module_a": module_a_deployment(), "module_b": module_b_python_trace(), "module_c": module_c_knn(), "module_d": module_d_safety(), "module_f": module_f_product(), } summary["module_e"] = module_e_dashboard(summary) readiness = round( (summary["module_c"]["accuracy"] * 100 + summary["module_d"]["passed"] / summary["module_d"]["total"] * 100 + summary["module_a"]["score"]) / 3, 1, ) write_json(REPORTS / "readiness_score.json", {"readiness_score": readiness, "summary": summary}) (RUN / "README.md").write_text("# Elective Workshop Evidence Pack\n\nRun `python elective_workshop.py`, then inspect `outputs/` and `reports/`.\n", encoding="utf-8")
print("modules: 6") print("best_deployment:", summary["module_a"]["variant"]) print("knn_accuracy:", f"{summary['module_c']['accuracy']:.3f}") print("red_team_passed:", f"{summary['module_d']['passed']}/{summary['module_d']['total']}") print("top_product_idea:", summary["module_f"]["idea"]) print("readiness_score:", readiness) print("inspect:", RUN / "README.md")
if __name__ == "__main__": main()Run it:
python3 elective_workshop.pyExpected output:
modules: 6best_deployment: quantized-int8knn_accuracy: 1.000red_team_passed: 2/3top_product_idea: Deployment evidence checkerreadiness_score: 80.8inspect: elective_workshop_run/README.mdInspect the results
Section titled “Inspect the results”| File | What to check |
|---|---|
outputs/module_a_deployment_score.csv | Why quantized-int8 wins: latency and memory improve while accuracy stays above the floor |
outputs/module_b_python_trace.json | The pipeline has visible steps instead of hidden work |
outputs/module_c_knn_predictions.csv | A tiny classic ML baseline predicts all test rows correctly |
outputs/module_d_red_team_report.md | The tool case intentionally fails and becomes a regression case |
outputs/module_e_dashboard.html | The evidence is readable in a browser |
outputs/module_f_product_canvas.md | RICE turns product priority into explicit numbers |
Debug quickly
Section titled “Debug quickly”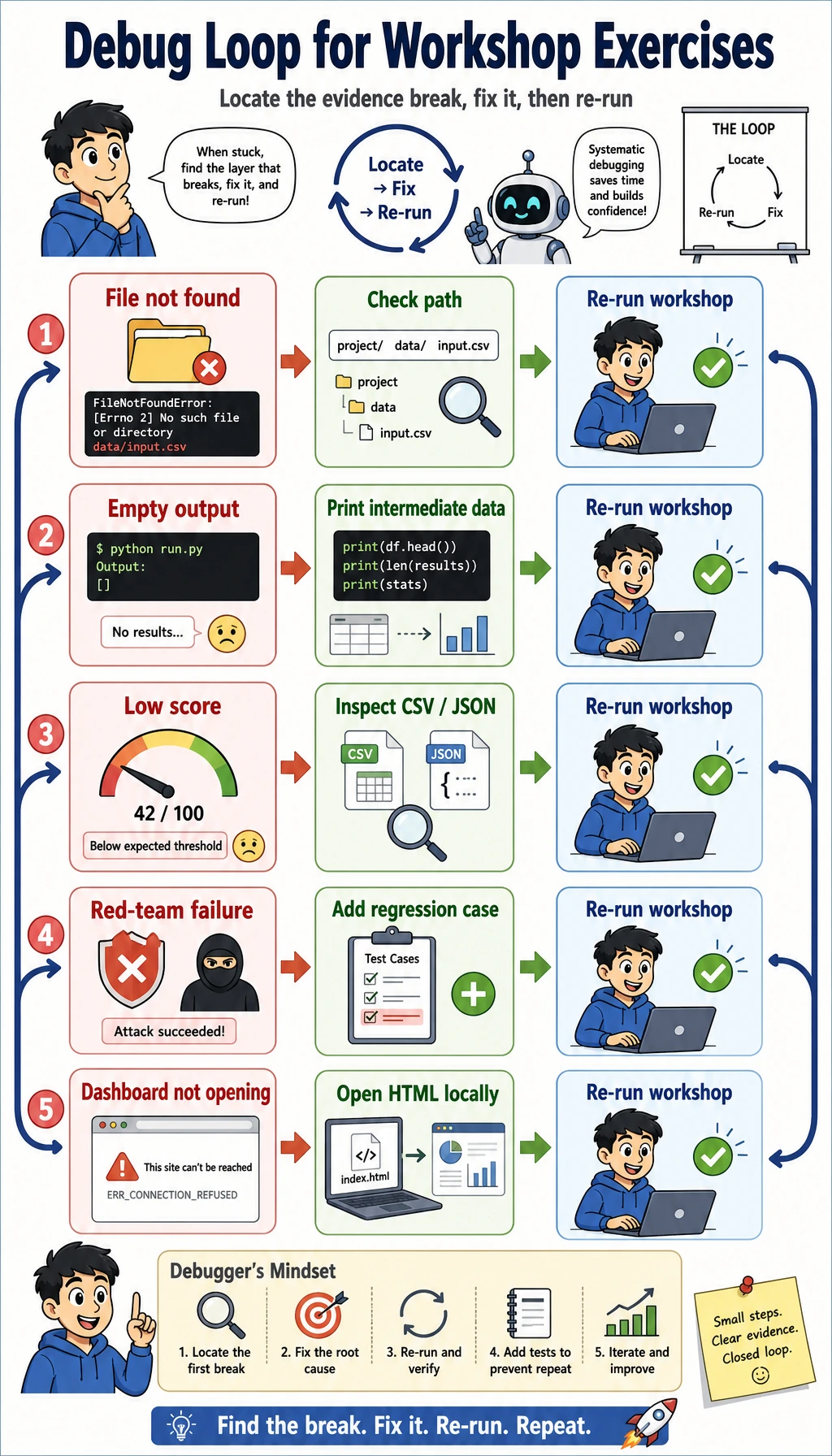
| Symptom | First fix |
|---|---|
python3 not found | Try python --version, then run python elective_workshop.py if it is Python 3 |
| No output folder | Run pwd and confirm you are in the workshop folder |
| CSV looks wrong | Print rows before write_csv(...) |
| Red-team failure appears | This is intentional; change observed from executed to ask_confirmation and rerun |
| HTML does not open | Open elective_workshop_run/outputs/module_e_dashboard.html directly |
Turn it into your project
Section titled “Turn it into your project”
Replace one module with real evidence:
- Module A: real latency, memory, and accuracy.
- Module B: real pipeline trace.
- Module C: your dataset and baseline.
- Module D: your safety cases.
- Module E: your dashboard or screenshot.
- Module F: your product ideas and RICE scores.
You are done when another person can run one command, inspect the files, understand one failure, and see the next action.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Elective Goal
- why this optional module matters for your target role or project
- Artifact
- runnable code, benchmark, product note, UI state, or safety test
- Metric Or Review
- what proves the elective skill improved the system
- Failure Check
- when this elective is unnecessary or too early for the current learner
- Expected Output
- a small portfolio artifact connected back to the main route
Review notes and pass criteria
This workshop passes when all six elective directions leave reviewable evidence, not when every module is production-grade.
Review the run in this order:
- Check terminal output for
modules: 6,readiness_score, andinspect. - Open
reports/readiness_score.jsonand confirm the summary was generated by the script. - Open
outputs/module_d_red_team_report.mdand confirm the intentional safety failure is recorded. - Open
outputs/module_e_dashboard.htmland confirm the evidence can be read by a non-code reviewer. - When replacing one module with real evidence, change only one evidence source and rerun the script.
If you are unsure which elective to choose, keep this evidence pack as a baseline. Replace a module only when the main project actually needs deployment, frontend, safety, or product judgment.